41 releases (5 breaking)
| 0.6.0 | Jun 22, 2024 |
|---|---|
| 0.5.3 | Jun 8, 2024 |
| 0.4.9 | Jun 2, 2024 |
| 0.4.4 | Feb 4, 2024 |
| 0.1.0 | Jan 2, 2024 |
#293 in HTTP server
2,475 downloads per month
2MB
1.5K
SLoC

A simple way to run a llama.cpp executable via a local private HTTP API for completions and embeddings.
Privacy goals:
- server is stateless
- always run on localhost only
- never write logs
- never put prompts in console logs
- MIT license so you can modify this to your specific needs at whim
The goal of this project is to make a completely clear and visible way to run a server locally. The code for how this runs is as minimal as possible so you can understand exactly what you are running.
You can install by grabbing binaries for all operating systems from Releases
or if you have rust installed:
cargo install epistemology
example:
epistemology -m ../llama.cpp/phi-2.Q2_K.gguf -e ../llama.cpp/main -d ../llama.cpp/embedding
Serving UI on https://localhost:8080/ from built-in UI
Listening with GET and POST on https://localhost:8080/api/completion
Examples:
* https://localhost:8080/api/completion?prompt=famous%20qoute:
* curl -X POST -d "famous quote:" https://localhost:8080/api/completion
* curl -X POST -d "robots are good" https://localhost:8080/api/embedding
You can also run your own web interface from a static path
epistemology -m ../llama.cpp/phi-2.Q2_K.gguf -e ../llama.cpp/main -d ../llama.cpp/embedding -u ./my-web-interface
Serving UI on https://localhost:8080/ from ./my-web-interface
Listening with GET and POST on https://localhost:8080/api/completion
Examples:
* https://localhost:8080/api/completion?prompt=famous%20qoute:
* curl -X POST -d "famous quote:" https://localhost:8080/api/completion
* curl -X POST -d "robots are good" https://localhost:8080/api/embedding
You can also constrain the output grammar with *.gbnf files for things like JSON output
epistemology -m ../llama.cpp/phi-2.Q2_K.gguf -e ../llama.cpp/main -d ../llama.cpp/embedding -g ./json.gbnf
Serving UI on https://localhost:8080/ from built-in UI
Listening with GET and POST on https://localhost:8080/completion
Examples:
* https://localhost:8080/api/completion?prompt=famous%20qoute:
* curl -X POST -d "famous quote:" https://localhost:8080/api/completion
* curl -X POST -d "robots are good" https://localhost:8080/api/embedding
Constraining to JSON Schema
Constraining AI output to structured data can make it much more useful for programatic usage. This project uses a sister project GBNF-rs for using JSON schema file as grammars.
Let's assume you have a file called "schema.json" that has JSON schema inside it
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/product.schema.json",
"title": "Product",
"description": "Famouse quote and person generator",
"type": "object",
"properties": {
"quote": {
"description": "A famous quote most people would know",
"type": "string"
},
"firstName": {
"description": "The authors's first name.",
"type": "string"
},
"lastName": {
"description": "The authors's last name.",
"type": "string"
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "number"
}
}
}
epistemology -m ../llama.cpp/phi-2.Q2_K.gguf -e ../llama.cpp/main -d ../llama.cpp/embedding -j ./my-schema.json
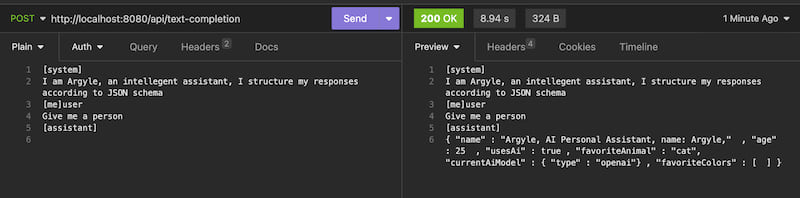
We can now ask the AI questions and now get answers constrained to our JSON format. Since a lot of metadata is lost during conversion to an AI grammar, we should re-iterate in the system prompt what we want to guide the generation better.
HTTP POST https://localhost:8080/api/completion
[system]
I am Argyle, an intellegent assistant, I structure my responses according to JSON schema
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/product.schema.json",
"title": "Product",
"description": "Famouse quote and person generator",
"type": "object",
"properties": {
"quote": {
"description": "A famous quote most people would know from the author's book",
"type": "string"
},
"firstName": {
"description": "The authors's first name.",
"type": "string"
},
"lastName": {
"description": "The authors's last name.",
"type": "string"
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "number"
}
}
}
[me]user
Generate me a famous quote?
[assistant]
Output
{
"quote" : "The sky above the port was the color of television, tuned to a dead channel.",
"firstName" : "William",
"lastNameName" : "William",
"age": 75.0
}
Advanced: How do I make things go faster
The main three knobs to play with are number of layers offloaded to GPU, number of threads, and context size
epistemology -m phi2.gguf -e ../llama.cpp/main.exe -l 35 -t 16 -c 50000
Advanced: Why am I seeing this error about invalid certificates?
Epistemology always uses a randomly generated HTTPS for secure communication, by default it autogenerates a certificate which is not registered with your machine. If you want this message to go away, you will have to create your own certificate and add it to your machine's approved list of certificates. Then run epistemology like.
epistemology -m phi2.gguf -e ../llama.cpp/main.exe --http-key-file key.pem --http-cert-file cert.pem
Advanced: Running Epistemology on AMD Radeon on Windows with a specific layer count
$env:GGML_OPENCL_PLATFORM = "AMD"
$env:GGML_OPENCL_DEVICE = "1" # you can change devices here
epistemology -m phi2.gguf -e ../llama.cpp/main.exe -n 40
Dependencies
~27–41MB
~805K SLoC