1 stable release
| 1.0.0 | Nov 21, 2024 |
|---|
#125 in Machine learning
75KB
1.5K
SLoC
Paddler
Important
Big chances! Paddler is rewritten into Rust (from Golang) and uses Pingora framework for the networking stack.
Version 1.0.0 brings some minor API changes and reporting improvements.
The next plan is to introduce a supervisor who does not just monitor llamas.cpp instances, but to also manage them (replace models without dropping requests, etc.).
Paddler is an open-source, production-ready, stateful load balancer and reverse proxy designed to optimize servers running llama.cpp.
Why Paddler

Typical load balancing strategies like round robin and least connections are ineffective for llama.cpp servers, which utilize continuous batching algorithms and allow to configure slots to handle multiple requests concurrently.
Paddler is designed to support llama.cpp-specific features like slots. It works by maintaining a stateful load balancer aware of each server's available slots, ensuring efficient request distribution.
Note
In simple terms, the slots in llama.cpp refer to predefined memory slices within the server that handle individual requests. When a request comes in, it is assigned to an available slot for processing. They are predictable and highly configurable.
You can learn more about them in llama.cpp server documentation.
Key features
- Uses agents to monitor the slots of individual llama.cpp instances.
- Supports the dynamic addition or removal of llama.cpp servers, enabling integration with autoscaling tools.
- Buffers requests, allowing to scale from zero hosts.
- Integrates with StatsD protocol but also comes with a built-in dashboard.
- AWS integration.
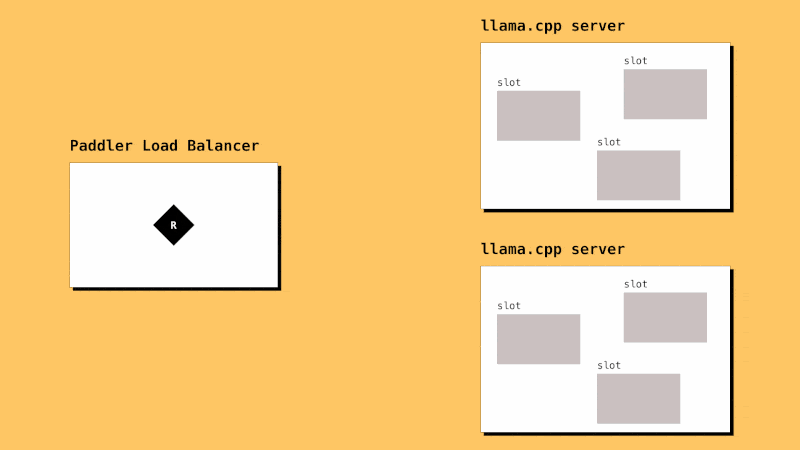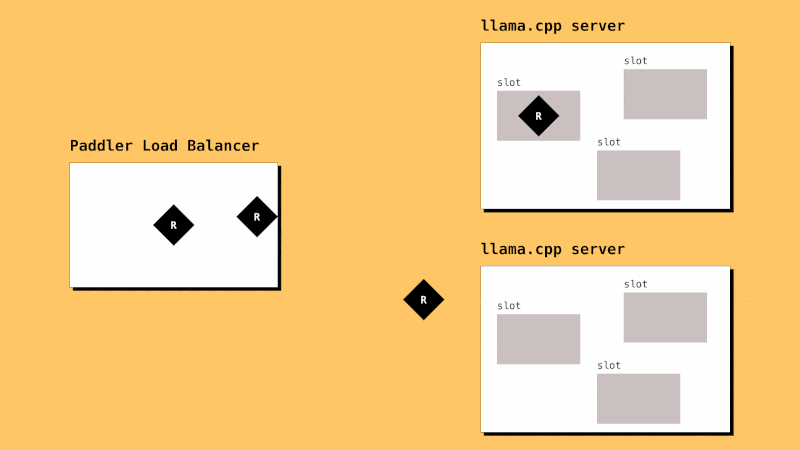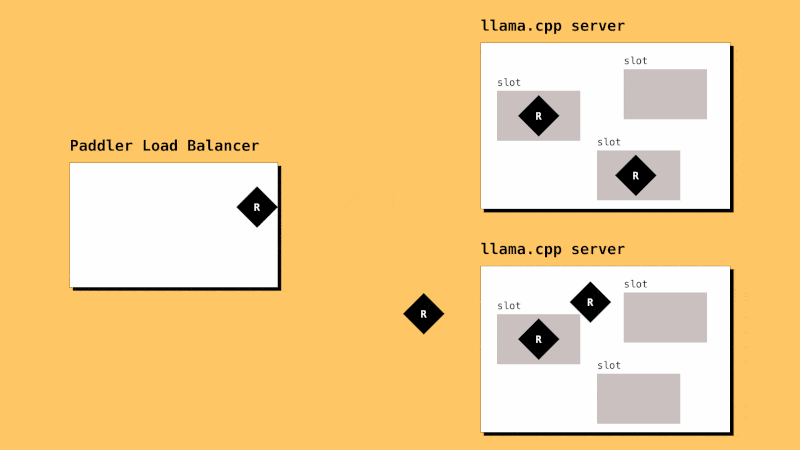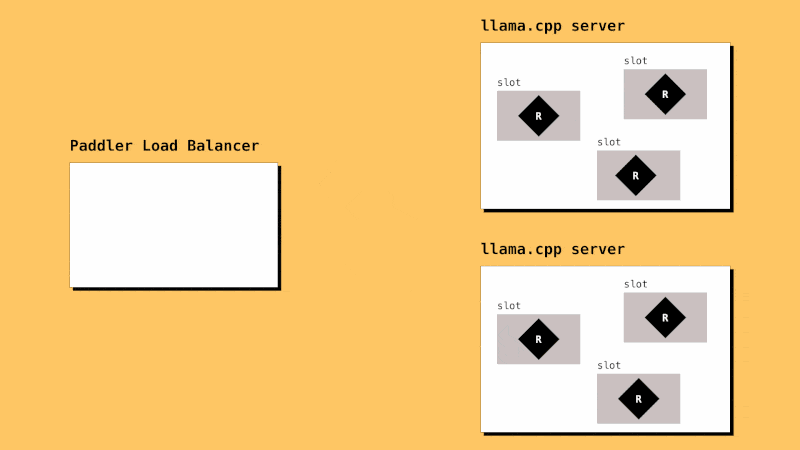
How it Works
llama.cpp instances need to be registered in Paddler. Paddler’s agents should be installed alongside llama.cpp instances so that they can report their slots status to the load balancer.
The sequence repeats for each agent:
sequenceDiagram
participant loadbalancer as Paddler Load Balancer
participant agent as Paddler Agent
participant llamacpp as llama.cpp
agent->>llamacpp: Hey, are you alive?
llamacpp-->>agent: Yes, this is my slots status
agent-->>loadbalancer: llama.cpp is still working
loadbalancer->>llamacpp: I have a request for you to handle
Usage
Installation
Download the latest release for Linux, Mac, or Windows from the releases page.
On Linux, if you want Paddler to be accessible system-wide, rename the downloaded executable to /usr/bin/paddler (or /usr/local/bin/paddler).
Running llama.cpp
Slots endpoint is required to be enabled in llama.cpp. To do so, run llama.cpp with the --slots flag.
Running Agents
The next step is to run Paddler’s agents. Agents register your llama.cpp instances in Paddler and monitor the slots of llama.cpp instances. They should be installed on the same host as your server that runs llama.cpp.
An agent needs a few pieces of information:
external-llamacpp-addrtells how the load balancer can connect to the llama.cpp instancelocal-llamacpp-addrtells how the agent can connect to the llama.cpp instancemanagement-addrtell where the agent should report the slots status
Run the following to start a Paddler’s agent (replace the hosts and ports with your own server addresses when deploying):
./paddler agent \
--external-llamacpp-addr 127.0.0.1:8088 \
--local-llamacpp-addr 127.0.0.1:8088 \
--management-addr 127.0.0.1:8085
Naming the Agents
With the --name flag, you can assign each agent a custom name. This name will be displayed in the management dashboard and not used for any other purpose.
API Key
If your llama.cpp instance requires an API key, you can provide it with the --local-llamacpp-api-key flag.
Running Load Balancer
Load balancer collects data from agents and exposes reverse proxy to the outside world.
It requires two sets of flags:
management-addrtells where the load balancer should listen for updates from agentsreverseproxy-addrtells how load balancer can be reached from the outside hosts
To start the load balancer, run:
./paddler balancer \
--management-addr 127.0.0.1:8085 \
--reverseproxy-addr 196.168.2.10:8080
management-host and management-port in agents should be the same as in the load balancer.
Enabling Dashboard
You can enable dashboard to see the status of the agents with
--management-dashboard-enable flag. If enabled, it is available at the
management server address under /dashboard path.
Enabling Slots Endpoint
Note
Available since v1.0.0
By default, Paddler blocks access to /slots endpoint, even if it is enabled in llama.cpp, because it exposes a lot of sensistive information about the server, and should only be used internally. If you want to expose it anyway, you can use the --slots-endpoint-enable flag.
Rewriting the Host Header
.
Note
Available since v0.8.0
In some cases (see: #20), you might want to rewrite the Host header.
In such cases, you can use the --rewrite-host-header flag. If used, Paddler will use the external host provided by agents instead of the balancer host when forwarding the requests.
Feature Highlights
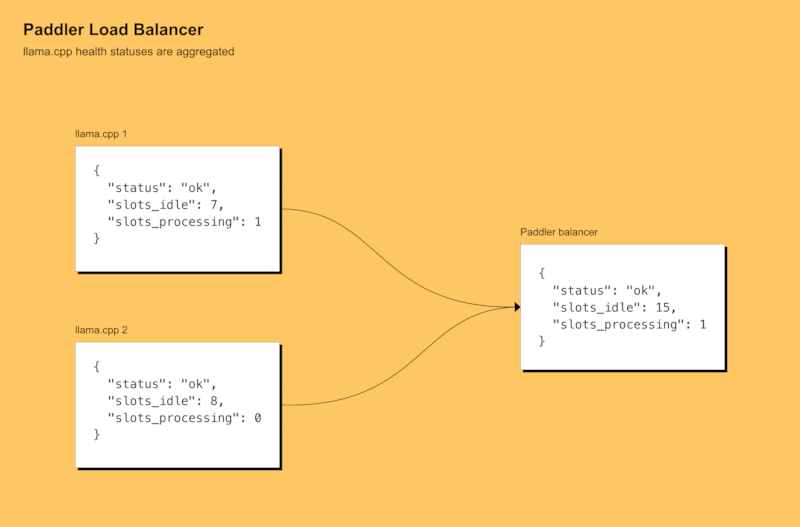
Aggregated Health Status
Paddler balancer endpoint aggregates the slots of all llama.cpp instances and reports the total number of available and processing slots.
Aggregated health status is available at the /api/v1/agents endpoint of the management server.
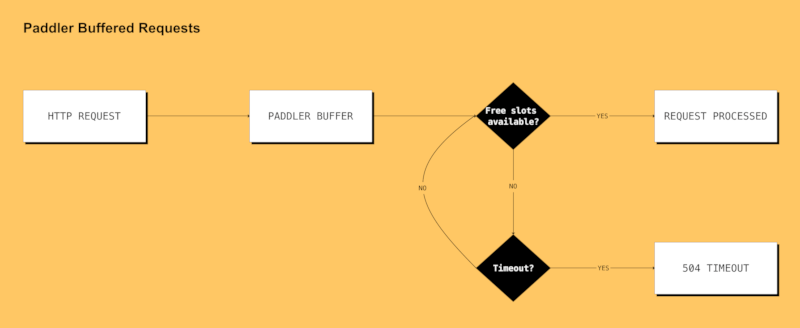
Buffered Requests (Scaling from Zero Hosts)
Note
Available since v0.3.0
Load balancer's buffered requests allow your infrastructure to scale from zero hosts by providing an additional metric (unhandled requests).
It also gives your infrastructure some additional time to add additional hosts. For example, if your autoscaler is setting up an additional server, putting an incoming request on hold for 60 seconds might give it a chance to be handled even though there might be no available llama.cpp instances at the moment of issuing it.
Scaling from zero hosts is especially suitable for low-traffic projects because it allows you to cut costs on your infrastructure—you won't be paying your cloud provider anything if you are not using your service at the moment.
https://github.com/distantmagic/paddler/assets/1286785/34b93e4c-0746-4eed-8be3-cd698e15cbf9
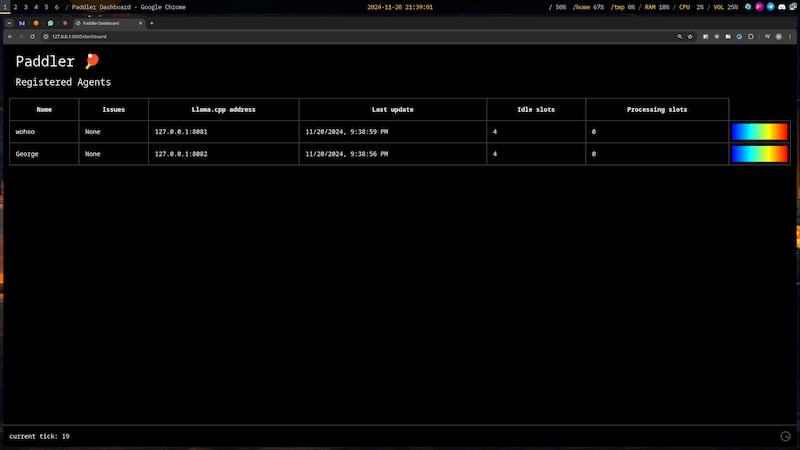
State Dashboard
Although Paddler integrates with the StatsD protocol, you can preview the cluster's state using a built-in dashboard.
StatsD Metrics
Note
Available since v0.3.0
Tip
If you keep your stack self-hosted you can use Prometheus with StatsD exporter to handle the incoming metrics.
Tip
This feature works with AWS CloudWatch Agent as well.
Paddler supports the following StatsD metrics:
requests_bufferednumber of buffered requests since the last report (resets after each report)slots_idletotal idle slotsslots_processingtotal slots processing requests
All of them use gauge internally.
StatsD metrics need to be enabled with the following flags:
./paddler balancer \
# .. put all the other flags here ...
--statsd-addr=127.0.0.1:8125
If you do not provide the --statsd-addr flag, the StatsD metrics will not be collected.
Tutorials
Changelog
v1.0.0
The first stable release! Paddler is now rewritten in Rust and uses the Pingora framework for the networking stack. A few minor API changes and reporting improvements are introduced (documented in the README). API and configuration are now stable, and won't be changed until version 2.0.0.
This is a stability/quality release. The next plan is to introduce a supervisor who does not just monitor llama.cpp instances, but to also manage them.
Requires llama.cpp version b4027 or above.
v0.10.0
This update is a minor release to make Paddler compatible with /slots endpoint changes introduced in llama.cpp b4027.
Requires llama.cpp version b4027 or above.
v0.9.0
Latest supported llama.cpp release: b4026
Features
- Add
--local-llamacpp-api-keyflag to balancer to support llama.cpp API keys (see: #23)
v0.8.0
Features
- Add
--rewrite-host-headerflag to balancer to rewrite theHostheader in forwarded requests (see: #20)
v0.7.1
Fixes
- Incorrect preemptive counting of remaining slots in some scenarios
v0.7.0
Requires at least b3606 llama.cpp release.
Breaking Changes
-
Adjusted to handle breaking changes in llama.cpp
/healthendpoint: https://github.com/ggerganov/llama.cpp/pull/9056Instead of using the
/healthendpoint to monitor slot statuses, starting from this version, Paddler uses the/slotsendpoint to monitor llama.cpp instances. Paddler's/healthendpoint remains unchanged.
v0.6.0
Latest supported llama.cpp release: b3604
Features
v0.5.0
Fixes
- Management server crashed in some scenarios due to concurrency issues
v0.4.0
Thank you, @ScottMcNaught, for the help with debugging the issues! :)
Fixes
- OpenAI compatible endpoint is now properly balanced (
/v1/chat/completions) - Balancer's reverse proxy
panicked in some scenarios when the underlyingllama.cppinstance was abruptly closed during the generation of completion tokens - Added mutex in the targets collection for better internal slots data integrity
v0.3.0
Features
- Requests can queue when all llama.cpp instances are busy
- AWS Metadata support for agent local IP address
- StatsD metrics support
v0.1.0
Features
Why the Name
I initially wanted to use Raft consensus algorithm (thus Paddler, because it paddles on a Raft), but eventually, I dropped that idea. The name stayed, though.
Later, people started sending me a "that's a paddlin'" clip from The Simpsons, and I just embraced it.
Community
Discord: https://discord.gg/kysUzFqSCK
Dependencies
~42–59MB
~1M SLoC