16 releases
| 0.2.5 | Feb 23, 2022 |
|---|---|
| 0.2.4 | Feb 22, 2022 |
| 0.1.9 | Feb 21, 2022 |
#1391 in Math
35 downloads per month
510KB
13K
SLoC
Static L.A. (Linear Algebra)
A fast minimal ultra type safe linear algebra library.
While ndarray offers no compile time type checking
on dimensionality and nalgebra offers some
finnicky checking, this offers the maximum possible checking.
When performing the addition of a MatrixDxS (a matrix with a known number of columns at
compile time) and a MatrixSxD (a matrix with a known number of rows at compile time) you
get a MatrixSxS (a matrix with a known number of rows and columns at compile time) since
now both the number of rows and columns are known at compile time. This then allows this
infomation to propagate through your program providing excellent compile time checking.
An example of how types will propagate through a program:
#![allow(incomplete_features)]
#![feature(generic_const_exprs)]
use static_la::*;
// MatrixSxS<i32,2,3>
let a = MatrixSxS::from([[1,2,3],[4,5,6]]);
// MatrixDxS<i32,3>
let b = MatrixDxS::from(vec![[2,2,2],[3,3,3]]);
// MatrixSxS<i32,2,3>
let c = (a.clone() + b.clone()) - a.clone();
// MatrixDxS<i32,3>
let d = c.add_rows(b);
// MatrixSxS<i32,4,3>
let e = MatrixSxS::from([[1,2,3],[4,5,6],[7,8,9],[10,11,12]]);
// MatrixSxS<i32,4,6>
let f = d.add_columns(e);
In this example the only operations which cannot be fully checked at compile time are:
a.clone() + b.clone()d.add_columns(e)
You must include #![feature(generic_const_exprs)] when using this library otherwise you will get a compiler error.
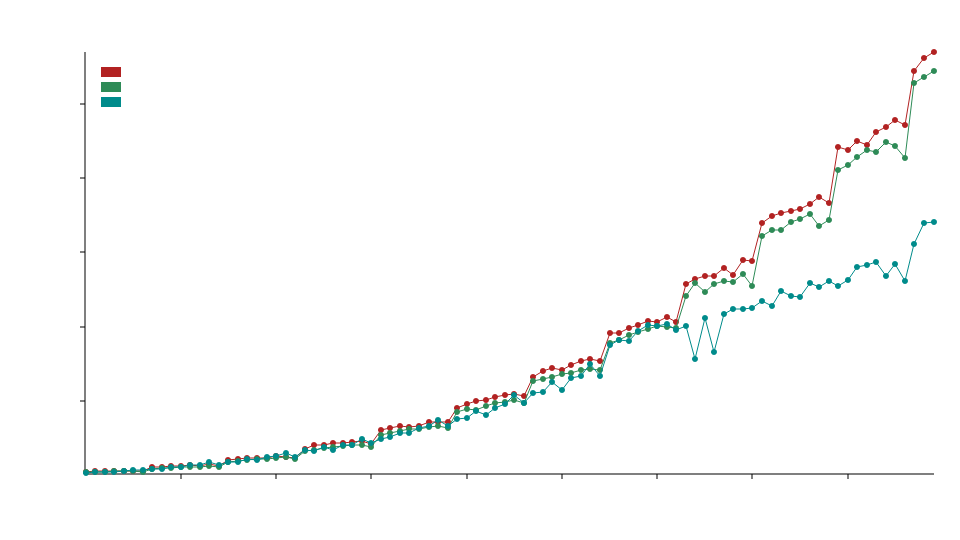
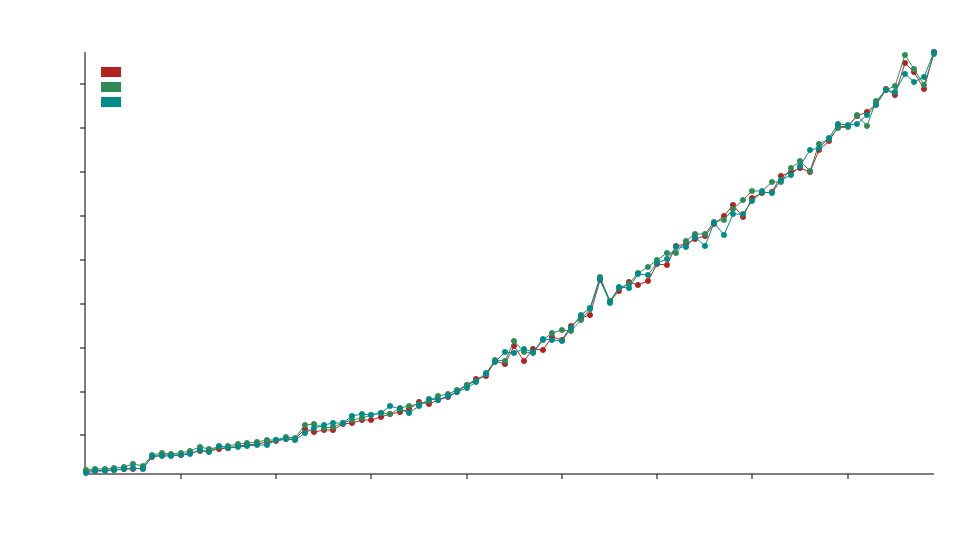
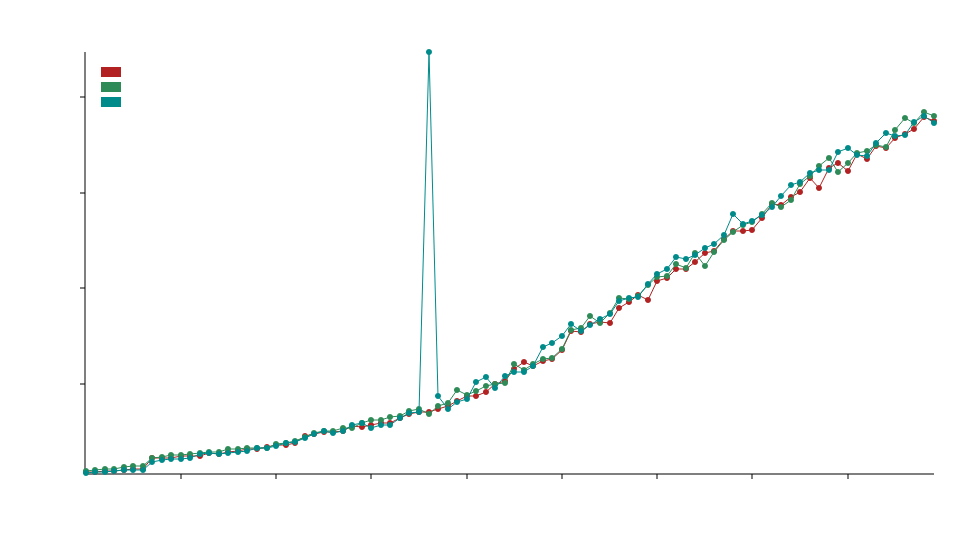
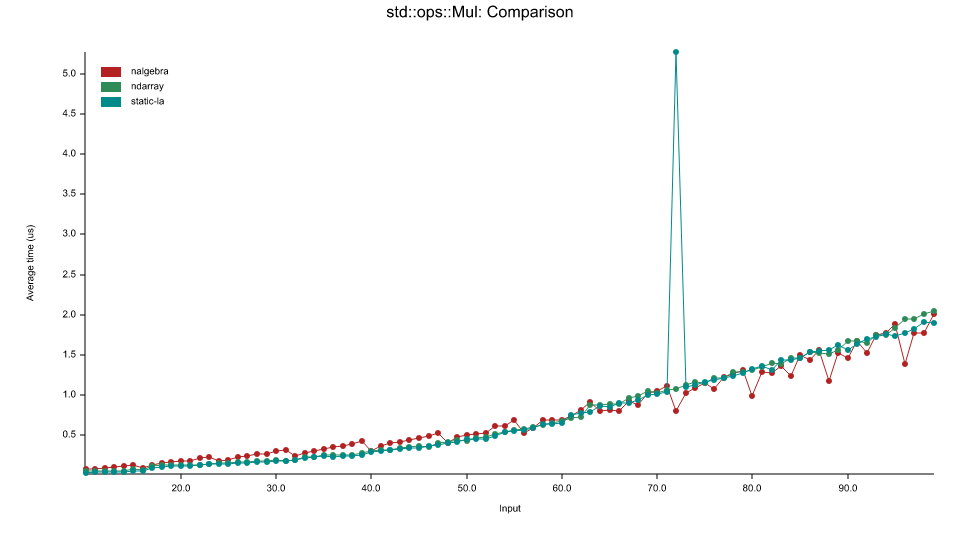
Comparisons
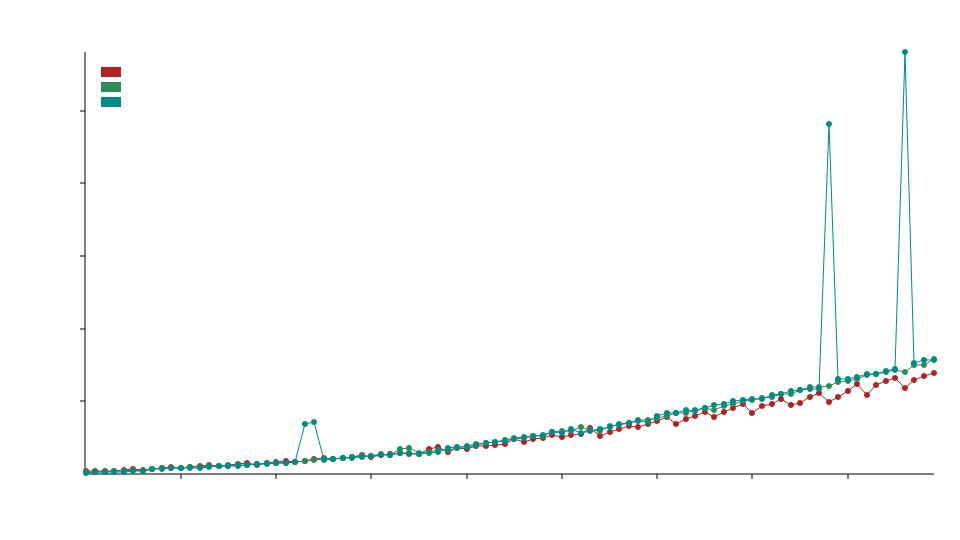
In the comparison benchmarks we are using static_la::MatrixDxD<f32>, ndarray::Array2<f32> and naglebra::DMatrix<f32>.
We use specialization to call optimized BLAS functions for floating point types, this means this library will typically outperform standard ndarray and nalgebra with f32 and f64 operations but may underperformed with integer (u32,i32, etc.) operations.
The x axis refers to the size of the matrices e.g. 50 refers to 50x50 matrices.
 |
 |
 |
 |
Dependencies
~0.3–2.2MB
~38K SLoC