2 releases
| 0.10.1 | Dec 20, 2024 |
|---|---|
| 0.10.0 | Dec 16, 2024 |
#773 in Text processing
922 downloads per month
255KB
5.5K
SLoC
kitoken
Tokenizer for language models.
use kitoken::Kitoken;
let encoder = Kitoken::from_file("models/llama2.kit")?;
let tokens = encoder.encode("Your future belongs to me.", true)?;
let string = String::from_utf8(encoder.decode(&tokens, true)?)?;
assert!(string == "Your future belongs to me.");
Features
- Fast encoding and decoding
Faster than most other tokenizers in both common and uncommon scenarios. - Support for a wide variety of tokenizer formats and tokenization strategies
Including support for Tokenizers, SentencePiece, Tiktoken and more. - Compatible with many systems and platforms
Runs on Windows, Linux, macOS and embedded, and comes with bindings for Web, Node and Python. - Compact data format
Definitions are stored in an efficient binary format and without merge list. - Support for normalization and pre-tokenization
Including unicode normalization, whitespace normalization, and many others.
Overview
Kitoken is a fast and versatile tokenizer for language models. Multiple tokenization algorithms are supported:
- BytePair: A variation of the BPE algorithm, merging byte or character pairs.
- Unigram: The Unigram subword algorithm.
- WordPiece: The WordPiece subword algorithm.
Kitoken is compatible with many existing tokenizers, including SentencePiece, HuggingFace Tokenizers, OpenAI Tiktoken and Mistral Tekken, while outperforming them in most scenarios. See the benchmarks for comparisons with different datasets.
Compatibility
Kitoken can load and convert many existing tokenizer formats. Every supported format is tested against the original implementation across a variety of inputs to ensure correctness and compatibility.
SentencePiece
let encoder = Kitoken::from_sentencepiece_file("models/mistral.model")?;
Kitoken can convert and initialize with SentencePiece models in BPE and Unigram format.
BPEmodels are converted toBytePairdefinitions in character mode. A merge list is generated and sorted using the token scores, which is then used to sort the vocabulary by merge priority. The scores and the merge list are then discarded.Unigrammodels are converted toUnigramdefinitions retaining the token scores.
If the model does not contain a trainer definition, Unigram is assumed as the default encoding mode. Normalization options and the unicode normalization scheme are taken from the contained normalizer definition and converted to the respective Kitoken configurations.
Notes
- SentencePiece uses different
nfkcnormalization rules in thenmt_nfkcandnmt_nfkc_cfschemes than during regularnfkcnormalization. This difference is not entirely additive and prevents the normalization of~to~. Kitoken uses the regularnfkcnormalization rules fornmt_nfkcandnmt_nfkc_cfand normalizes~to~. - SentencePiece's implementation of Unigram merges pieces with the same merge priority differently depending on preceding non-encodable pieces. For example, with
xlnet_base_cased, SentencePiece encodes.nnnandԶnnnas.., 8705, 180butԶԶnnnas.., 180, 8705. Kitoken always merges pieces with the same merge priority in the same order, resulting in.., 180, 8705for either case in the example and matching the behavior of Tokenizers.
Tokenizers
let encoder = Kitoken::from_tokenizers_file("models/llama2.json")?;
Kitoken can convert and initialize with HuggingFace Tokenizers definitions for BPE, Unigram and WordPiece models.
BPEmodels are converted toBytePairdefinitions. The included merge list is used to sort the vocabulary by merge priority and is then discarded.Unigrammodels are converted toUnigramdefinitions retaining the token scores.WordPiecemodels are converted toWordPiecedefinitions.
Normalization, pre-tokenization, post-processing and decoding options contained in the definition are converted to the respective Kitoken configurations.
Some normalization, post-processing and decoding options used by Tokenizers are used for converting alternative token-byte representations during encoding and decoding. Kitoken always stores and operates on tokens as byte sequences, and will use these options to pre-normalize the vocabulary during conversion.
Notes
- When using a
BPEdefinition with an incomplete vocabulary and without anunktoken, Tokenizers skips over non-encodable pieces and attempts to merge the surrounding ones. Kitoken always considers non-encodable pieces as un-mergeable and encodes the surrounding pieces individually. This can result in different encodings depending on vocabulary coverage and inputs in this scenario. - Tokenizers normalizes inputs character-by-character, while Kitoken normalizes inputs as one. This can result in differences during case-folding in some cases. For example, greek letter
Σhas two lowercase forms,σfor within-word andςfor end-of-word use. Tokenizers will always lowercaseΣtoσ, while Kitoken will lowercase it to either depending on the context.
Tiktoken
let encoder = Kitoken::from_tiktoken_file("models/cl100k_base.tiktoken")?;
Tiktoken is a BPE tokenizer with a custom definition format used by OpenAI for GPT-3 and newer models using BytePair tokenization in byte mode.
Tiktoken definitions contain a sorted vocabulary of base64 encoded bytes and corresponding token ids without any additional metadata. Special tokens and the split regex are expected to be provided separately, but will be inferred from the data for common models including GPT-3, GPT-4 and GPT-4o. For other models, or depending on the data and requirements, these values can be adjusted manually.
Tekken
let encoder = Kitoken::from_tekken_file("models/nemo.json")?;
Tekken is a BPE tokenizer with a custom definition format based on Tiktoken, used by Mistral for NeMo and newer models using BytePair tokenization in byte mode.
Tekken definitions contain a sorted vocabulary of base64 encoded bytes and corresponding token ids, as well as metadata including the split regex and special tokens.
Performance
Kitoken uses merge-list-free variations of the BPE algorithm and a reversed variation of the Unigram algorithm. The basis for the merge-list-free BPE algorithm was inspired by Tiktoken, which has similarly good performance characteristics with common tokenization inputs. However, Kitoken can be much faster with inputs that fail to split during pre-tokenization by falling back to a priority-queue-based implementation when optimal.
The core tokenization functions are optimized for multiple CPU architectures and make use of SIMD instructions where available. Kitoken also avoids memory allocations and copying of data to great extent, and most operations are performed in-place and buffers are reused where possible.
Benchmarks
Benchmarks were performed on a MacBook Pro M1 Max using each libraries Python bindings with tokenizer-bench.
Llama 2
Llama 2 uses a SentencePiece-based tokenizer model and BytePair tokenization in character mode with byte mode fallback.
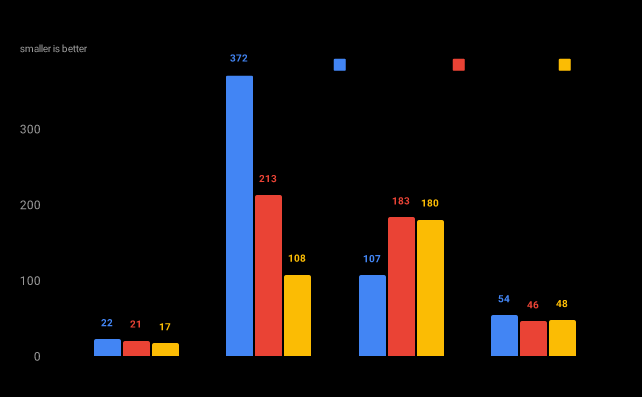
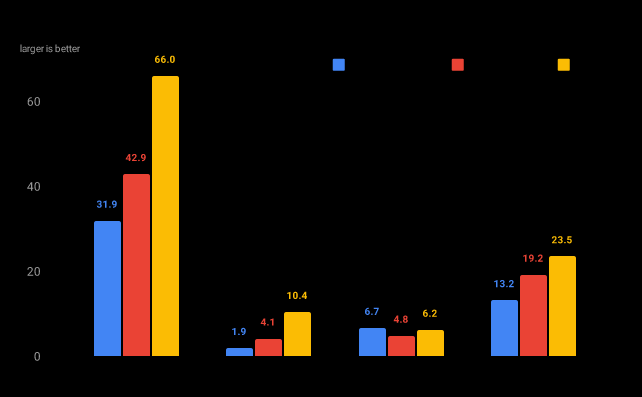
Encoding throughput
GPT-2
GPT-2 uses a Tokenizers-based tokenizer model and BytePair tokenization in byte mode.
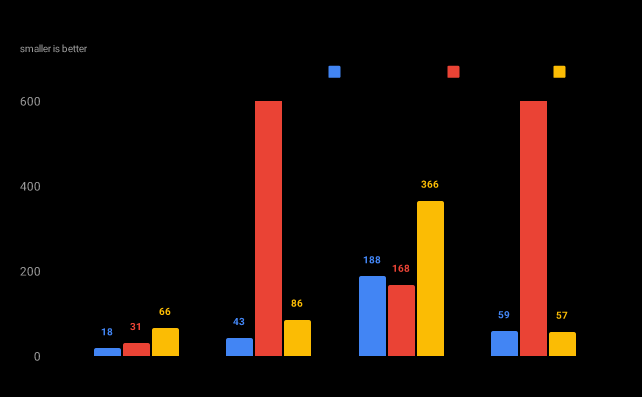
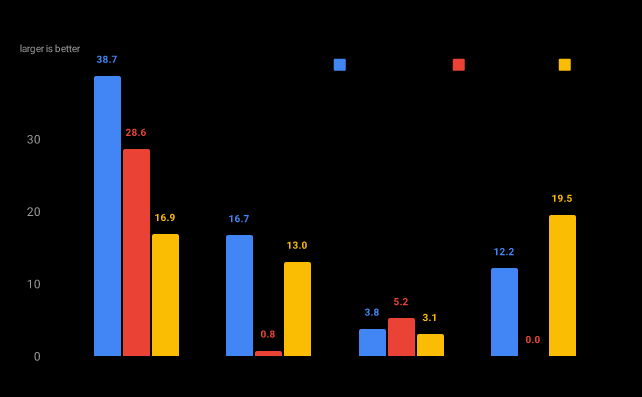
Encoding throughput
Datasets
-
Pride and Prejudice: A text document containing Pride and Prejudice by Jane Austen. This data is a good representation for common English-language inputs containing a mix of short and long paragraphs.
-
UTF-8 Sequence: A text document containing a single-line UTF-8 sequence. This data is a good representation of inputs that might fail to split during pre-tokenization.
-
Wagahai: A text document containing Wagahai wa Neko de Aru by Natsume Sōseki. This data is a good representation for Japanese-language inputs containing many long paragraphs.
Dependencies
~4–8MB
~143K SLoC