10 releases (5 breaking)
| 0.7.1 | Jul 18, 2023 |
|---|---|
| 0.7.0 | Feb 16, 2023 |
| 0.6.1 | Dec 6, 2022 |
| 0.5.1 | Oct 19, 2022 |
| 0.2.0 | May 15, 2021 |
#4 in #jj
Used in jujutsu
1MB
20K
SLoC
Deprecated
The jujutsu and jujutsu-lib crates have been replaced by the jj-cli
and jj-lib crates, respectively.
Please upgrade to jj-cli/jj-lib version 0.8+, or
specify jujutsu/jujutsu-lib of version "=0.7.0" if you need to compile an
obsolete version.
Jujutsu VCS
![]()
Disclaimer
This is not a Google product. It is an experimental version-control system (VCS). It was written by me, Martin von Zweigbergk (martinvonz@google.com). It is my personal hobby project and my 20% project at Google. It does not indicate any commitment or direction from Google. However, my presentation from Git Merge 2022 does include some information about Google's plans. See the slides or the recording.
Introduction
Jujutsu is a Git-compatible
DVCS. It combines
features from Git (data model,
speed), Mercurial (anonymous
branching, simple CLI free from "the index",
revsets, powerful history-rewriting), and Pijul/Darcs
(first-class conflicts), with features not found in most
of them (working-copy-as-a-commit,
undo functionality, automatic rebase,
safe replication via rsync, Dropbox, or distributed file
system).
The command-line tool is called jj for now because it's easy to type and easy
to replace (rare in English). The project is called "Jujutsu" because it matches
"jj".
If you have any questions, please join us on Discord
![]() .
.
Features
Compatible with Git
Jujutsu has two backends. One of them is a Git backend (the other is a native one [^native-backend]). This lets you use Jujutsu as an alternative interface to Git. The commits you create will look like regular Git commits. You can always switch back to Git. The Git support uses the libgit2 C library.
[^native-backend]: At this time, there's practically no reason to use the native backend (the only minor reason might be #27). The backend exists mainly to make sure that it's possible to eventually add functionality that cannot easily be added to the Git backend.
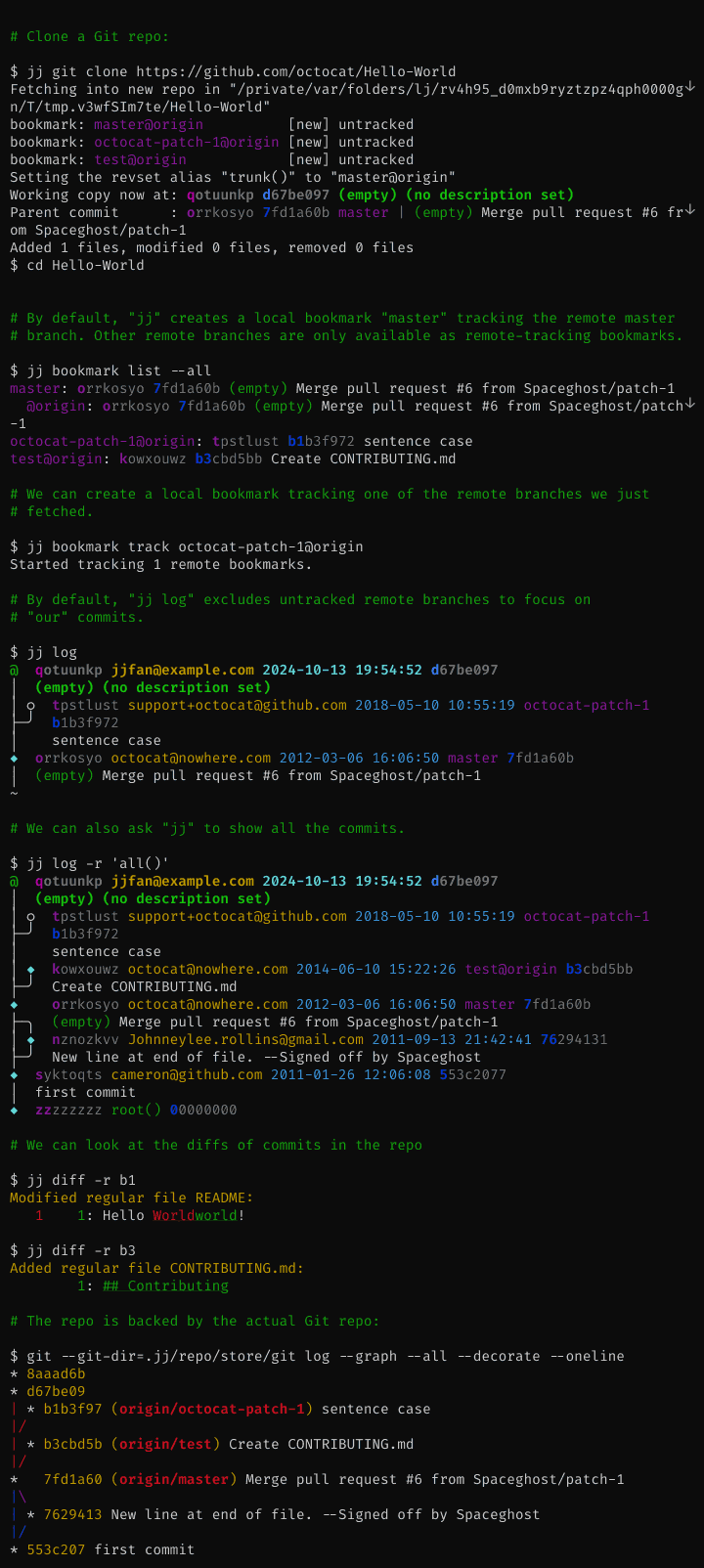
The working copy is automatically committed
Most Jujutsu commands automatically commit the working copy. This leads to a simpler and more powerful interface, since all commands work the same way on the working copy or any other commit. It also means that you can always check out a different commit without first explicitly committing the working copy changes (you can even check out a different commit while resolving merge conflicts).
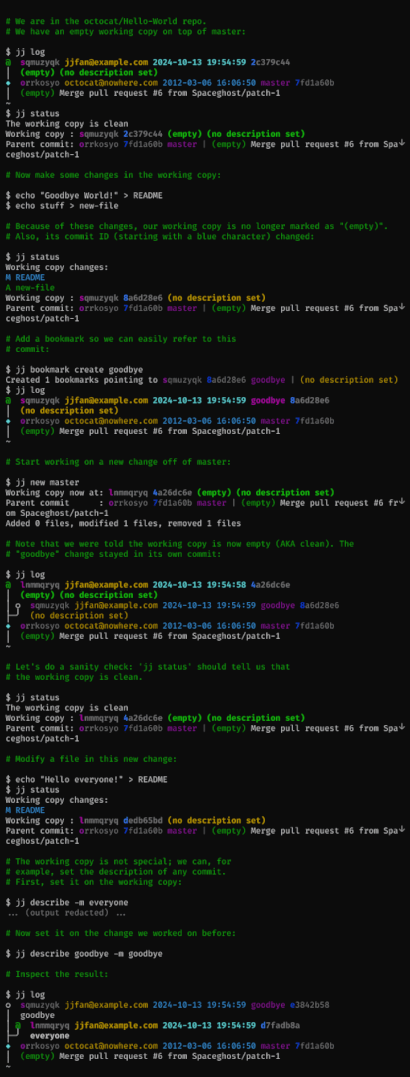
Operations update the repo first, then possibly the working copy
The working copy is only updated at the end of an operation, after all other
changes have already been recorded. This means that you can run any command
(such as jj rebase) even if the working copy is dirty.
Entire repo is under version control
All operations you perform in the repo are recorded, along with a snapshot of the repo state after the operation. This means that you can easily revert to an earlier repo state, or to simply undo a particular operation (which does not necessarily have to be the most recent operation).
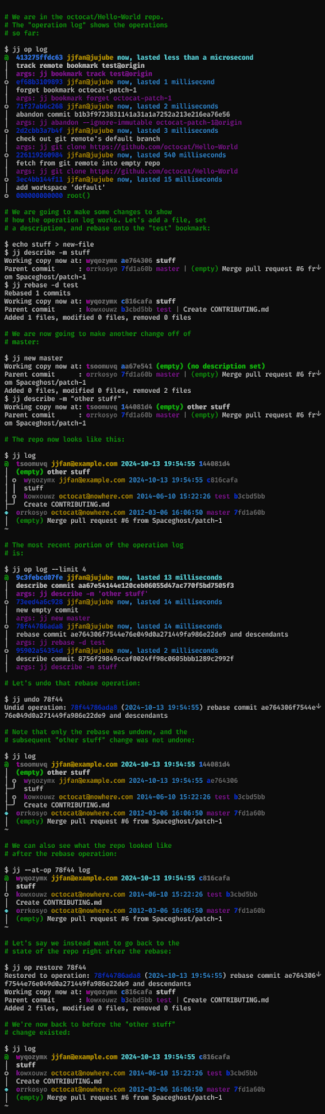
Conflicts can be recorded in commits
If an operation results in conflicts, information about those conflicts will be recorded in the commit(s). The operation will succeed. You can then resolve the conflicts later. One consequence of this design is that there's no need to continue interrupted operations. Instead, you get a single workflow for resolving conflicts, regardless of which command caused them. This design also lets Jujutsu rebase merge commits correctly (unlike both Git and Mercurial).
Basic conflict resolution:
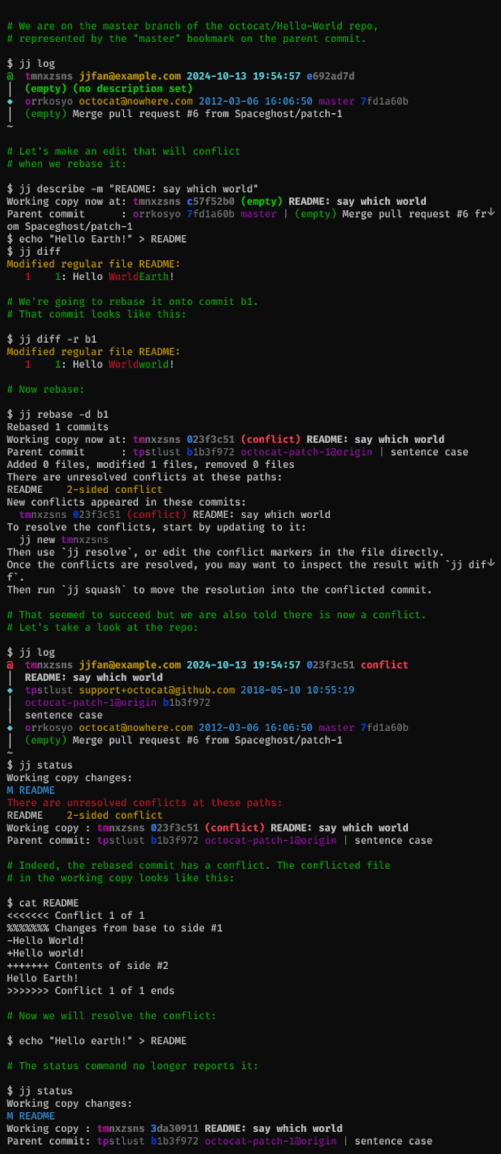
Juggling conflicts:
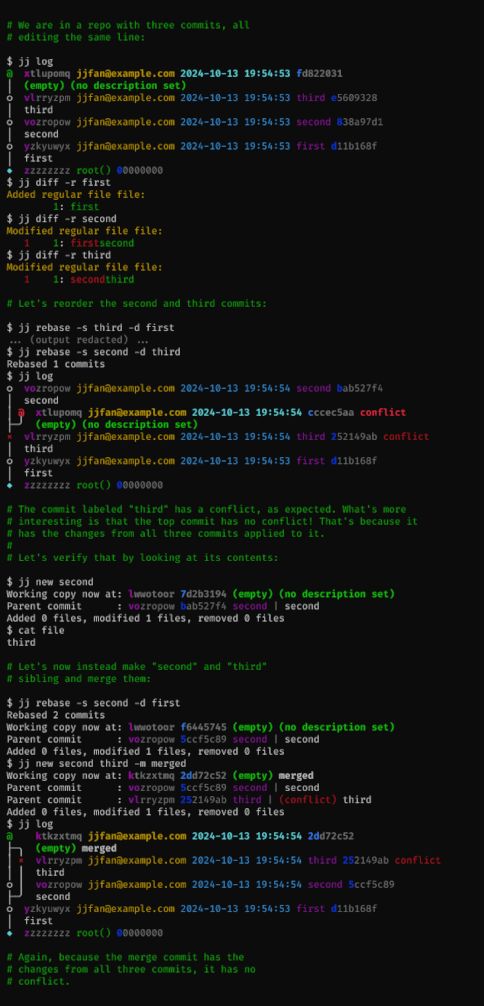
Automatic rebase
Whenever you modify a commit, any descendants of the old commit will be rebased onto the new commit. Thanks to the conflict design described above, that can be done even if there are conflicts. Branches pointing to rebased commits will be updated. So will the working copy if it points to a rebased commit.
Comprehensive support for rewriting history
Besides the usual rebase command, there's jj describe for editing the
description (commit message) of an arbitrary commit. There's also jj diffedit,
which lets you edit the changes in a commit without checking it out. To split
a commit into two, use jj split. You can even move part of the changes in a
commit to any other commit using jj move.
Status
The tool is quite feature-complete, but some important features like (the
equivalent of) git blame are not yet supported. There
are also several performance bugs. It's also likely that workflows and setups
different from what the core developers use are not well supported.
I (Martin von Zweigbergk) have almost exclusively used jj to develop the
project itself since early January 2021. I haven't had to re-clone from source
(I don't think I've even had to restore from backup).
There will be changes to workflows and backward-incompatible changes to the
on-disk formats before version 1.0.0. Even the binary's name may change (i.e.
away from jj). For any format changes, we'll try to implement transparent
upgrades (as we've done with recent changes), or provide upgrade commands or
scripts if requested.
Installation
See below for how to build from source. There are also pre-built binaries for Windows, Mac, or Linux (musl).
If you're installing from source, you need to use Rust version 1.61 or higher, or you will get a cryptic message like this:
error: failed to select a version for the requirement `libgit2-sys = "=0.14.0"``
candidate versions found which didn't match: 0.13.2+1.4.2, 0.13.1+1.4.2, 0.13.0+1.4.1, ...
Linux
On most distributions, you'll need to build from source using cargo directly.
Build using cargo
First make sure that you have the libssl-dev, openssl, and pkg-config
packages installed by running something like this:
sudo apt-get install libssl-dev openssl pkg-config
Now run:
cargo install --git https://github.com/martinvonz/jj.git --locked --bin jj jujutsu
Nix OS
If you're on Nix OS you can use the flake for this repository.
For example, if you want to run jj loaded from the flake, use:
nix run 'github:martinvonz/jj'
You can also add this flake url to your system input flakes. Or you can install the flake to your user profile:
nix profile install 'github:martinvonz/jj'
Homebrew
If you use linuxbrew, you can run:
brew install jj
Mac
Homebrew
If you use Homebrew, you can run:
brew install jj
MacPorts
You can also install jj via MacPorts (as the jujutsu port):
sudo port install jujutsu
From Source
You may need to run some or all of these:
xcode-select --install
brew install openssl
brew install pkg-config
export PKG_CONFIG_PATH="$(brew --prefix)/opt/openssl@3/lib/pkgconfig"
Now run:
cargo install --git https://github.com/martinvonz/jj.git --locked --bin jj jujutsu
Windows
Run:
cargo install --git https://github.com/martinvonz/jj.git --locked --bin jj jujutsu --features vendored-openssl
Initial configuration
You may want to configure your name and email so commits are made in your name.
Create a file at ~/.jjconfig.toml and make it look something like
this:
$ cat ~/.jjconfig.toml
[user]
name = "Martin von Zweigbergk"
email = "martinvonz@google.com"
Command-line completion
To set up command-line completion, source the output of
jj debug completion --bash/--zsh/--fish. Exactly how to source it depends on
your shell.
Bash
source <(jj debug completion) # --bash is the default
Zsh
autoload -U compinit
compinit
source <(jj debug completion --zsh | sed '$d') # remove the last line
compdef _jj jj
Fish
jj debug completion --fish | source
Xonsh
source-bash $(jj debug completion)
Getting started
The best way to get started is probably to go through
the tutorial. Also see the
Git comparison, which includes a table of
jj vs. git commands.
Related work
There are several tools trying to solve similar problems as Jujutsu. See related work for details.
Dependencies
~23–36MB
~650K SLoC