4 releases
| 0.1.4 | Jan 1, 2024 |
|---|---|
| 0.1.2 | Jan 1, 2024 |
| 0.1.1 | Jan 1, 2024 |
| 0.1.0 | Dec 30, 2023 |
#723 in Database interfaces
58KB
942 lines
SteelDB
This is a study repository. This is mostly for personal use. Building a Database from scratch in Rust. Why not? :)
Source code: https://github.com/paolorechia/steeldb/
Current version documentation: latest
*Database: https://docs.rs/steeldb/latest/steeldb *Parser: https://docs.rs/steeldb-parser/latest/steeldb_parser/
Architecture
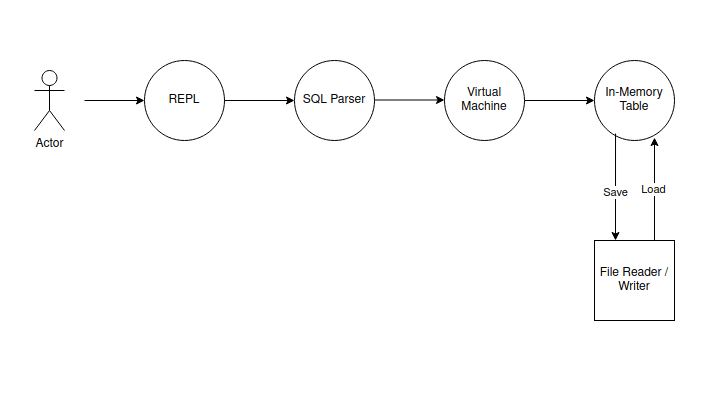
How to use this version
Should be as simple:
cargo add steeldb
cargo run
This should start a REPL:
------------------------------------------------
| |
| SteelDB |
| version: 0.1.0 |
| |
------------------------------------------------
Type 'exit;' to leave this shell
Current supported commands: [select]
>>
The only implemented clause is select, which selects columns of a previously constructed table. For example:
>> select name, annual_salary;
|---------------------------------|
| name | annual_salary |
|---------------------------------|
| John Man | 60000 |
| Lenon | 200000 |
| Mary | 3012000 |
|---------------------------------|
>>
Commands should always add with a ;.
If you simply try the command above, you will instead see:
>> select name;
"Os { code: 2, kind: NotFound, message: \"No such file or directory\" }"
<------------------ COMMAND FAILED ------------------>
"TableNotFound"
<---------------------------------------------------->
>>
This is because the table must be pre-created. You can either create one using cargo test and copying it,
or copying and pasting this into the file .steeldb/data/test_table.columnar:
TABLE COLUMNAR FORMAT HEADER
Field name: final_grade; Type: f32; Number of elements: 3
4.0
3.2
5
Field name: name; Type: String; Number of elements: 3
John Man
Lenon
Mary
Field name: annual_salary; Type: i32; Number of elements: 3
60000
200000
3012000
Columnar Format
As you can see, the table format is very naive and verbose. It stores data in ASCII. It's not meant to be efficient and will probably be replaced in the future.
More info
Useful Links:
- https://cstack.github.io/db_tutorial/parts/part1.html
- https://www.sqlite.org/arch.html
- https://build-your-own.org/database/
Roadmap
This is not a binding roadmap.
What do we need to build a Database like SQLite from scratch?
- A REPL shell
- A tokenizer
- A parser
- A code generator
- A virtual machine that interprets the generated code
- A B+ Tree
- Pager
- OS Interface
For the first iteration: the bare bones (v0.1.0)
We can simplify some components in the first iteration, so we have first a working end-to-end system. We can then tweak the individual components to have more capabilities.
Here are some simplifications we can do for our first iteration:
- Support only a subset of the SQL Syntax, for instance, start with only insert and select operations.
- Do not implement a B+ tree in the first iteration. Instead, use a vector or list of structs.
- Do not handle Pager in first iteration.
- Keep the database persisted into a single file.
- Use a single statically defined table.
Our roadmap for the first iteration might end up looking like this:
- A REPL shell [x]
- A tokenizer [x]
- A parser [x]
- Add support for the SELECT clause [x]
- A code generator [x]
- A virtual machine that interprets the generated code [x]
- A table struct that stores data in HashMap of Vectors [x]
- A hardcoded table for testing [x]
- Proper error propagation [x]
- Pretty printing of table in REPL [x]
- A serialization / desserialization method to write/read data from file [x]
- Clean up [x]
- Handle select columns properly in read method [x]
- Test that everything is working as expected [x]
- Tag v1.0 [x]
Second iteration: making it usable (v0.2.0)
- Add proper documentation to project []
- Add another API besides the REPL to query the database []
- This can be either a traditional TCP or a HTTP server. It should be as simple as possible, and just receive a string of the SQL command
- Make REPL support both backends: Standalone process or network server
- Adds proper logging strategy to the server []
- Add configuration file []
- Add create table command []
- Add drop table command []
- Add alter table command []
- Multiple tables query support (add FROM clause support) []
- Support filters (add basic WHERE clause support) []
- Add proper documentation to project []
- Update Cargo.toml
Third iteration: making it scalable (v0.3.0)
- Handle concurrency: needs research on approaches to use []
- Implement B+ or similar algorithm.
- Ideally keep support for current columnar support []
- Support both in-memory and persistent
- Adds caching (or pagination) []
- Support for transactions []
Fourth iteration: making it useful (v0.4.0)
- Implement inner join []
- Implement left / right join []
- Implement outer join []
- Implement nested operations, including WHERE IN (SELECT) []
- Implement aggregations []
Fifth iteration: making it time-aware (v0.5.0)
- Implement advanced SQL features
- Window []
- Having []
- Add date and timestamp types []
- Implement more SQL functions []
Sixth iteration: making it complete (v0.6.0)
- Anything important missing in SQL standards
Seventh iteration: making it compatible (v0.7.0)
- Implement the Spark.SQL API in Rust
Eighth iteration: making it attractive (v0.8.0)
- Build a SDK in Rust to use it
Nineth iteration: making it snaky (v0.9.0)
- Build Python bindings for the Rust SDK
Tenth iteration: placeholder (v1.0.0)
If we reached this point, we actually have an impressive system :)
Knowledge base
How do we build each of these components in Rust?
REPL Shell
This is pobably the simplest component. We just need to implement a CLI shell that reads lines of input until the command end symbol is presented (like ';'). It then forwards the parsed string into the next layers of our system, and returns the result.
A Tokenizer and A Parser
One should be able to generate them using https://github.com/lalrpop/lalrpop. Tutorial: http://lalrpop.github.io/lalrpop/tutorial/001_adding_lalrpop.html
A Code Generator
This should be somehow integrated into the parser. It will become clearer once the first parser is built, how this can be written (if possible, avoiding too much coupling).
Virtual Machine
Probably the easiest way is to implement it as a stack, so it can handled nested commands. For each parsed command, we push it to the stack, and the virtual machine pop it, executing it. This works assuming we parse the commands in a depth-first way, e.g., the most inner command is always parsed first, and it's result is available to the next command execution. This should happen naturally using an auto-generated lexer/parser with lalrpop, as long as the grammar is correctly defined.
To keep it simple, however, we should start not supporting nested commands. We can still have the stack in place and ready for extension in the future.
B+ Tree
The B+ Tree is wide-known algorithm, and is described in several places, for instance: https://en.wikipedia.org/wiki/B%2B_tree This will be skipped until much later! The goal is to first get an usable system/product that supports concurrency and possibly exposes an (HTTP) API to query data. This means things like transactions have to be possibly implemented first.
Dependencies
~2.6–5MB
~82K SLoC