39 releases (18 stable)
| 1.10.0 | Feb 21, 2025 |
|---|---|
| 1.9.0 | Sep 28, 2024 |
| 1.6.2 | Jul 23, 2024 |
| 1.0.0 | Mar 30, 2024 |
| 0.2.6 | Oct 22, 2021 |
#51 in Math
50 downloads per month
Used in 6 crates
2MB
35K
SLoC
Russell Sparse - Solvers for large sparse linear systems (wraps MUMPS and UMFPACK)
![]()
This crate is part of Russell - Rust Scientific Library
Contents
Introduction
This library implements tools for handling sparse matrices and functions to solve large sparse systems using the best libraries out there, such as UMFPACK (recommended) and MUMPS (for very large systems).
This library implements three storage formats for sparse matrices:
- COO: COOrdinates matrix, also known as a sparse triplet.
- CSC: Compressed Sparse Column matrix
- CSR: Compressed Sparse Row matrix
Additionally, to unify the handling of the above sparse matrix data structures, this library implements:
- SparseMatrix: Either a COO, CSC, or CSR matrix
The COO matrix is the best when we need to update the values of the matrix because it has easy access to the triples (i, j, aij). For instance, the repetitive access is the primary use case for codes based on the finite element method (FEM) for approximating partial differential equations. Moreover, the COO matrix allows storing duplicate entries; for example, the triple (0, 0, 123.0) can be stored as two triples (0, 0, 100.0) and (0, 0, 23.0). Again, this is the primary need for FEM codes because of the so-called assembly process where elements add to the same positions in the "global stiffness" matrix. Nonetheless, the duplicate entries must be summed up at some stage for the linear solver (e.g., MUMPS, UMFPACK). These linear solvers also use the more memory-efficient storage formats CSC and CSR. See the russell_sparse documentation for further information.
This library also provides functions to read and write Matrix Market files containing (huge) sparse matrices that can be used in performance benchmarking or other studies. The [read_matrix_market()] function reads a Matrix Market file and returns a [CooMatrix]. To write a Matrix Market file, we can use the function [write_matrix_market()], which takes a [SparseMatrix] and, thus, automatically convert COO to CSC or COO to CSR, also performing the sum of duplicates. The write_matrix_market also writes an SMAT file (almost like the Matrix Market format) without the header and with zero-based indices. The SMAT file can be given to the fantastic Vismatrix tool to visualize the sparse matrix structure and values interactively; see the example below.
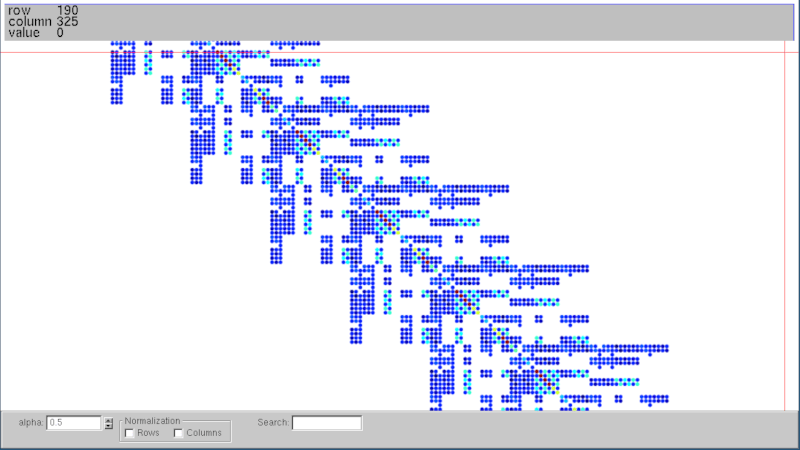
Documentation
 — russell_sparse documentation
— russell_sparse documentation- See also a paper concerning some caveats with the sparse solvers (freely available).
Installation
This crate depends on some non-rust high-performance libraries. See the main README file for the steps to install these dependencies.
Setting Cargo.toml
![]()
👆 Check the crate version and update your Cargo.toml accordingly:
[dependencies]
russell_sparse = "*"
Optional features
The following (Rust) features are available:
intel_mkl: Use Intel MKL instead of OpenBLASlocal_suitesparse: Use a locally compiled version of SuiteSparsewith_mumps: Enable the MUMPS solver (locally compiled)
Note that the main README file presents the steps to compile the required libraries according to each feature.
🌟 Examples
This section illustrates how to use russell_sparse. See also:
Solve a tiny sparse linear system using UMFPACK
use russell_lab::{vec_approx_eq, Vector};
use russell_sparse::prelude::*;
use russell_sparse::StrError;
fn main() -> Result<(), StrError> {
// constants
let ndim = 3; // number of rows = number of columns
let nnz = 5; // number of non-zero values
// allocate solver
let mut umfpack = SolverUMFPACK::new()?;
// allocate the coefficient matrix
let mut coo = CooMatrix::new(ndim, ndim, nnz, Sym::No)?;
coo.put(0, 0, 0.2)?;
coo.put(0, 1, 0.2)?;
coo.put(1, 0, 0.5)?;
coo.put(1, 1, -0.25)?;
coo.put(2, 2, 0.25)?;
// print matrix
let a = coo.as_dense();
let correct = "┌ ┐\n\
│ 0.2 0.2 0 │\n\
│ 0.5 -0.25 0 │\n\
│ 0 0 0.25 │\n\
└ ┘";
assert_eq!(format!("{}", a), correct);
// call factorize
umfpack.factorize(&coo, None)?;
// allocate two right-hand side vectors
let b = Vector::from(&[1.0, 1.0, 1.0]);
// calculate the solution
let mut x = Vector::new(ndim);
umfpack.solve(&mut x, &b, false)?;
let correct = vec![3.0, 2.0, 4.0];
vec_approx_eq(&x, &correct, 1e-14);
Ok(())
}
See russell_sparse documentation for more examples.
See also the folder examples.
Tools
This crate includes a tool named solve_matrix_market to study the performance of the available sparse solvers (currently MUMPS and UMFPACK).
solve_matrix_market reads a Matrix Market file and solves the linear system:
A ⋅ x = b
where the right-hand side (b) is a vector containing only ones.
The data directory contains an example of a Matrix Market file named bfwb62.mtx, and you may download more matrices from https://sparse.tamu.edu/
For example, run the command:
cargo run --release --bin solve_matrix_market -- ~/Downloads/matrix-market/bfwb62.mtx
Or
cargo run --release --bin solve_matrix_market -- --help
to see the options.
The default solver of solve_matrix_market is UMFPACK. To run with MUMPS, use the --genie (-g) flag:
cargo run --release --bin solve_matrix_market -- -g mumps ~/Downloads/matrix-market/bfwb62.mtx
The output looks like this:
{
"main": {
"platform": "Russell",
"blas_lib": "OpenBLAS",
"solver": "MUMPS-local"
},
"matrix": {
"name": "bfwb62",
"nrow": 62,
"ncol": 62,
"nnz": 202,
"complex": false,
"symmetric": "YesLower"
},
"requests": {
"ordering": "Auto",
"scaling": "Auto",
"mumps_num_threads": 0
},
"output": {
"effective_ordering": "Amf",
"effective_scaling": "RowColIter",
"effective_mumps_num_threads": 1,
"openmp_num_threads": 24,
"umfpack_strategy": "Unknown",
"umfpack_rcond_estimate": 0.0
},
"determinant": {
"mantissa_real": 0.0,
"mantissa_imag": 0.0,
"base": 2.0,
"exponent": 0.0
},
"verify": {
"max_abs_a": 0.0001,
"max_abs_ax": 1.0000000000000004,
"max_abs_diff": 5.551115123125783e-16,
"relative_error": 5.550560067119071e-16
},
"time_human": {
"read_matrix": "43.107µs",
"initialize": "266.59µs",
"factorize": "196.81µs",
"solve": "166.87µs",
"total_ifs": "630.27µs",
"verify": "2.234µs"
},
"time_nanoseconds": {
"read_matrix": 43107,
"initialize": 266590,
"factorize": 196810,
"solve": 166870,
"total_ifs": 630270,
"verify": 2234
},
"mumps_stats": {
"inf_norm_a": 0.0,
"inf_norm_x": 0.0,
"scaled_residual": 0.0,
"backward_error_omega1": 0.0,
"backward_error_omega2": 0.0,
"normalized_delta_x": 0.0,
"condition_number1": 0.0,
"condition_number2": 0.0
}
}
MUMPS + OpenBLAS issue
We found that MUMPS + OpenBLAS becomes very, very slow when the number of OpenMP threads is left automatic, i.e., using the available number of threads. Thus, with OpenBLAS, it is recommended to set LinSolParams.mumps_num_threads = 1 (this is automatically set when using OpenBLAS).
This issue has been discussed in Reference #1 and also in Reference #2, who states (page 72) "We have observed that multi-threading of OpenBLAS library in MUMPS leads to multiple thread conflicts which sometimes result in significant slow-down of the solver."
Therefore, we have to take one of the two approaches:
- If fixing the number of OpenMP threads for MUMPS, set the number of OpenMP threads for OpenBLAS to 1
- If fixing the number of OpenMP threads for OpenBLAS, set the number of OpenMP threads for MUMPS to 1
This issue has not been noticed with MUMPS + Intel MKL.
Command to reproduce the issue:
OMP_NUM_THREADS=20 ~/rust_modules/release/solve_matrix_market -g mumps ~/Downloads/matrix-market/inline_1.mtx -m 0 -v --override-prevent-issue
Also, to reproduce the issue, we need:
- Git hash = e020d9c8486502bd898d93a1998a0cf23c4d5057
- Remove Debian OpenBLAS, MUMPS, and etc.
- Install the compiled MUMPS solver with
02-ubuntu-openblas-compile.bash
References
- Pedroso DM (2024) Caveats of three direct linear solvers for finite element analyses, International Journal for Numerical Methods in Engineering, doi.org/10.1002/nme.7545.
- Dorozhinskii R (2019) Configuration of a linear solver for linearly implicit time integration and efficient data transfer in parallel thermo-hydraulic computations. Master's Thesis in Computational Science and Engineering. Department of Informatics Technical University of Munich.
For developers
- The
c_codedirectory contains a thin wrapper to the sparse solvers (MUMPS, UMFPACK) - The
build.rsfile uses the crateccto build the C-wrappers - The
zscriptsdirectory also contains following:memcheck.bash: Checks for memory leaks on the C-code using Valgrindrun-examples: Runs all examples in theexamplesdirectoryrun-solve-matrix-market.bash: Runs the solve-matrix-market tool from thebindirectory
Dependencies
~4–5MB
~97K SLoC