27 releases (7 breaking)
| 0.8.0 | Feb 12, 2025 |
|---|---|
| 0.7.2 | Nov 26, 2024 |
| 0.2.0 | Jul 31, 2024 |
#943 in Web programming
976 downloads per month
46KB
638 lines
protosocket
Message-oriented, low-abstraction tcp streams.
A protosocket is a non-blocking, bidirectional, message streaming connection. Providing a serializer and deserializer for your messages, you can stream to and from tcp servers.
There is no wrapper encoding - no HTTP, no gRPC, no websockets. You depend on TCP and your serialization strategy.
Dependencies are trim; tokio is the main hard dependency. If you use protocol
buffers, you will also depend on prost. There's no extra underlying framework.
Protosockets avoid too many opinions - you have (get?) to choose your own message ordering and concurrency semantics. You can make an implicitly ordered stream, or a non-blocking out-of-order stream, or anything in between.
Tools to facilitate protocol buffers are provided in protosocket-prost.
You can write an RPC client/server with protosocket-rpc.
You can see an example of protocol buffers RPC in example-proto.
Case study
Background
(Full disclosure: I work at Momento at time of writing this): Momento
has historically been a gRPC company. In a particular backend service with a
fairly high message rate, the synchronization in h2 under tonic was seen
to be blocking threads in the tokio request runtime too much. This was causing
task starvation and long polls.
The starvation was tough to see, but it happens with lock_contended stacks
underneath the std::sync::Mutex while trying to work with h2 buffers. That
mutex is okay, but when the futex syscall parks a thread, it takes hundreds
of microseconds to get the thread going again on Momento's servers. It causes
extra latency that you can't easily measure, because tasks are also not picked
up promptly in these cases.
I was able to get 20% greater throughput by writing k-lock
and replacing the imports in h2 for std::sync::Mutex with k_lock::Mutex.
This import-replacement for std::sync::Mutex tries to be more appropriate for
tokio servers. Basically, it uses a couple heuristics to both wake and spin
more aggressively than the standard mutex. This is better for tokio servers,
because those threads absolutely must finish poll() asap, and a futex park
blows the poll() budget out the window.
20% wasn't enough, and the main task threads were still getting starved. So I
pulled protosocket out of rmemstore,
to try it out on Momento's servers.
Test setup
Momento has a daily latency and throughput test to monitor how changes are affecting system performance. This test uses a small server setup to more easily stress the service (as opposed to stressing the load generator).
Latency is measured outside of Momento, at the client. It includes a lot of factors that are not directly under Momento control, and offers a full picture of how the service could look to users (if it were deployed in a small setup like the test).
The number Momento looked at historically was at which throughput threshold does the server pass 5 milliseconds at p99.9 tail latency?
Results
| Throughput | Latency | |
|---|---|---|
| gRPC | 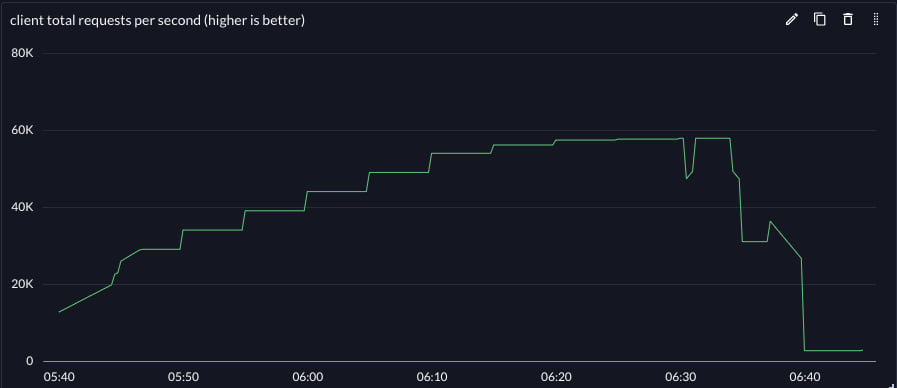 |
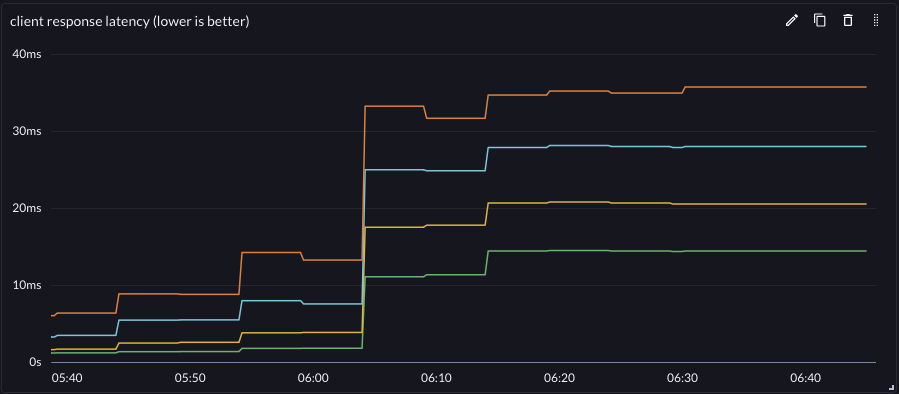 |
| protosockets | 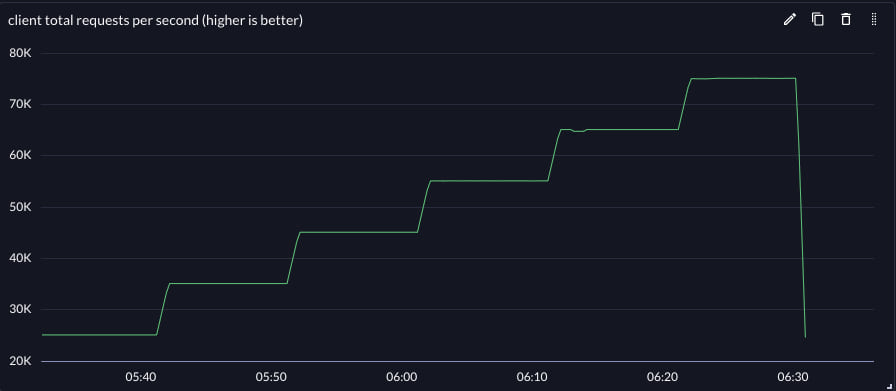 |
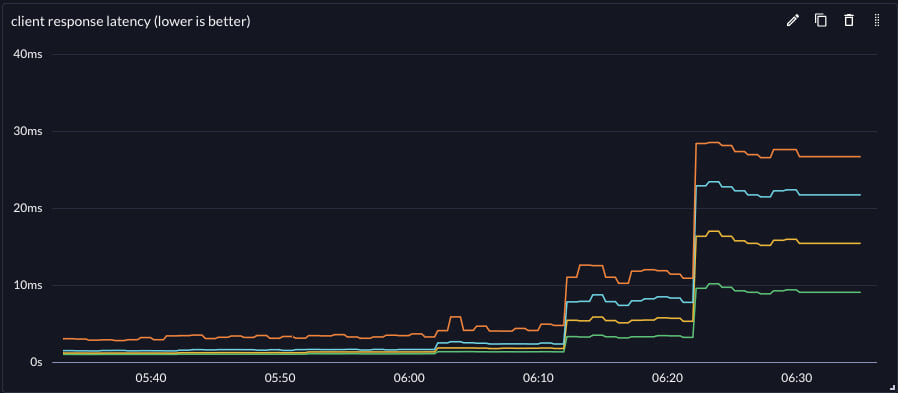 |
Achievable throughput increased, but latency at all throughputs was significantly reduced. This improved the effective vertical scale of the reference workflow.
The effective vertical scale of the small reference server was improved by 2.75x for this workflow by switching the backend protocol from gRPC to protosockets.
Dependencies
~4–13MB
~134K SLoC