72 stable releases
| 2.11.0 | Sep 15, 2024 |
|---|---|
| 2.10.4 | Jun 16, 2024 |
| 2.10.3 | Apr 27, 2024 |
| 2.10.1 | Nov 9, 2023 |
| 0.2.1 | Oct 3, 2020 |
#180 in Web programming
314 downloads per month
1MB
16K
SLoC
A simple, fast, recursive content discovery tool written in Rust
![]()
![]()
🦀 Releases ✨ Example Usage ✨ Contributing ✨ Documentation 🦀
✨🎉👉 NEW DOCUMENTATION SITE 👈🎉✨
🚀 Documentation has moved 🚀
Instead of having a 1300 line README.md (sorry...), feroxbuster's documentation has moved to GitHub Pages. The move to hosting documentation on Pages should make it a LOT easier to find the information you're looking for, whatever that may be. Please check it out for anything you need beyond a quick-start. The new documentation can be found here.
😕 What the heck is a ferox anyway?
Ferox is short for Ferric Oxide. Ferric Oxide, simply put, is rust. The name rustbuster was taken, so I decided on a variation. 🤷
🤔 What's it do tho?
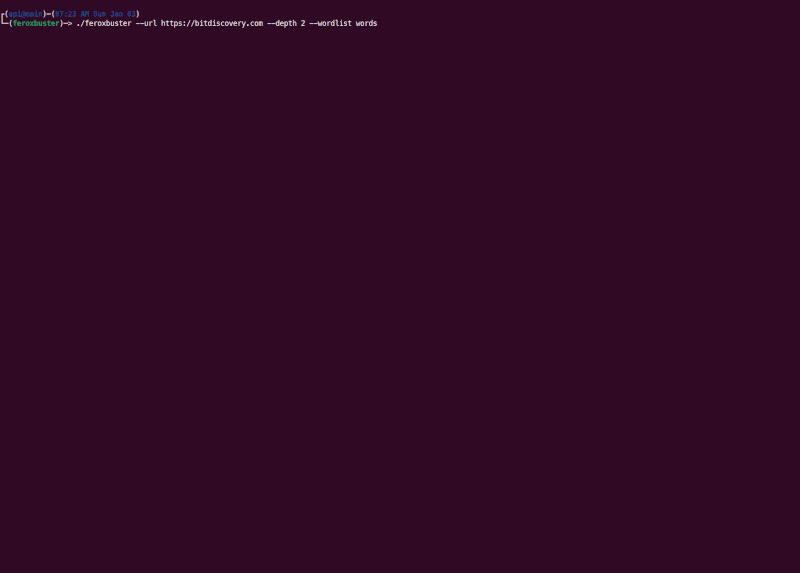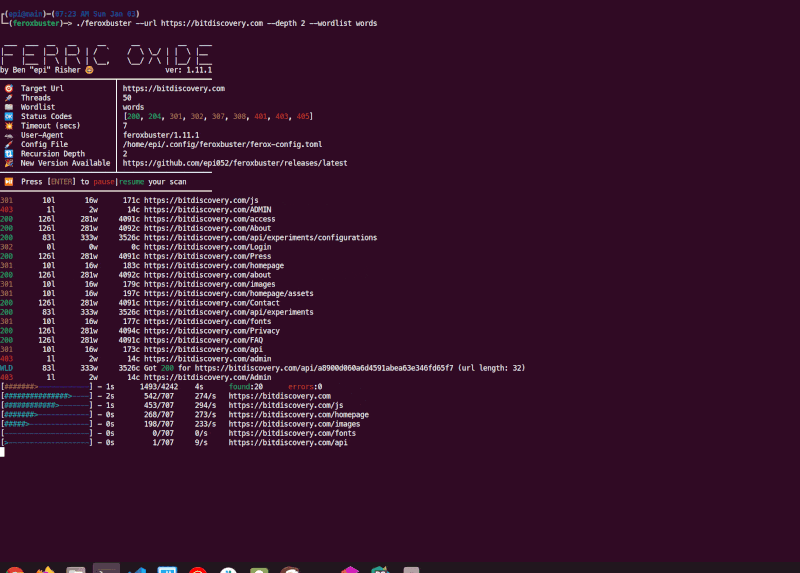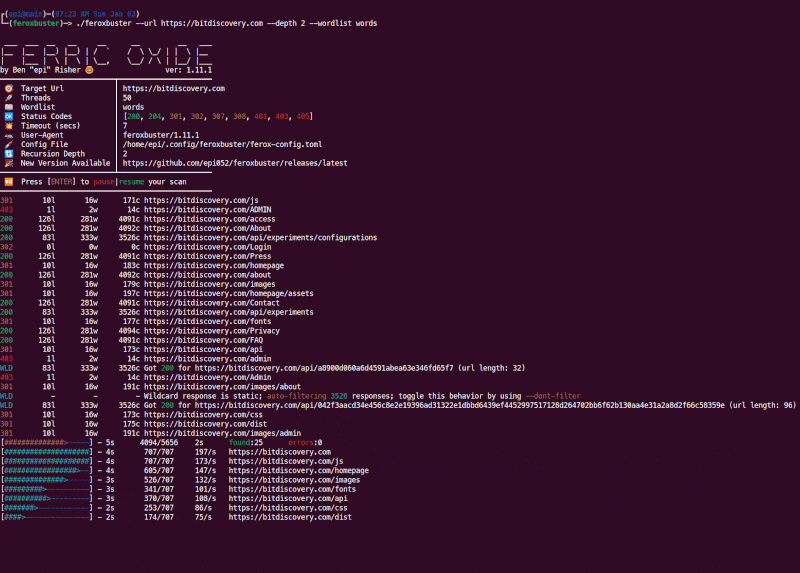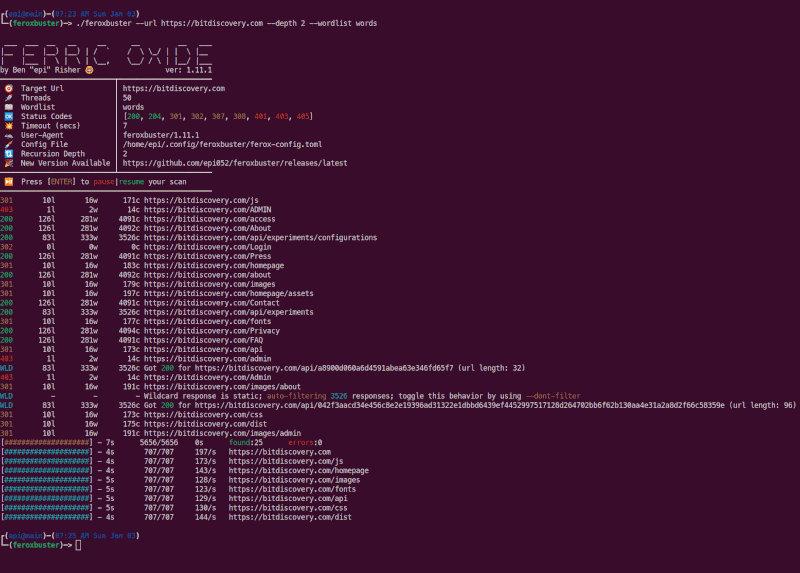
feroxbuster is a tool designed to perform Forced Browsing.
Forced browsing is an attack where the aim is to enumerate and access resources that are not referenced by the web application, but are still accessible by an attacker.
feroxbuster uses brute force combined with a wordlist to search for unlinked content in target directories. These
resources may store sensitive information about web applications and operational systems, such as source code,
credentials, internal network addressing, etc...
This attack is also known as Predictable Resource Location, File Enumeration, Directory Enumeration, and Resource Enumeration.
⏳ Quick Start
This section will cover the minimum amount of information to get up and running with feroxbuster. Please refer the the documentation, as it's much more comprehensive.
💿 Installation
There are quite a few other installation methods, but these snippets should cover the majority of users.
Kali
If you're using kali, this is the preferred install method. Installing from the repos adds a ferox-config.toml in /etc/feroxbuster/, adds command completion for bash, fish, and zsh, includes a man page entry, and installs feroxbuster itself.
sudo apt update && sudo apt install -y feroxbuster
Linux (32 and 64-bit) & MacOS
Install to a particular directory
curl -sL https://raw.githubusercontent.com/epi052/feroxbuster/main/install-nix.sh | bash -s $HOME/.local/bin
Install to current working directory
curl -sL https://raw.githubusercontent.com/epi052/feroxbuster/main/install-nix.sh | bash
MacOS via Homebrew
brew install feroxbuster
Windows x86_64
Invoke-WebRequest https://github.com/epi052/feroxbuster/releases/latest/download/x86_64-windows-feroxbuster.exe.zip -OutFile feroxbuster.zip
Expand-Archive .\feroxbuster.zip
.\feroxbuster\feroxbuster.exe -V
Windows via Winget
winget install epi052.feroxbuster
Windows via Chocolatey
choco install feroxbuster
All others
Please refer the the documentation.
Updating feroxbuster (new in v2.9.1)
./feroxbuster --update
🧰 Example Usage
Here are a few brief examples to get you started. Please note, feroxbuster can do a lot more than what's listed below. As a result, there are many more examples, with demonstration gifs that highlight specific features, in the documentation.
Multiple Values
Options that take multiple values are very flexible. Consider the following ways of specifying extensions:
./feroxbuster -u http://127.1 -x pdf -x js,html -x php txt json,docx
The command above adds .pdf, .js, .html, .php, .txt, .json, and .docx to each url
All of the methods above (multiple flags, space separated, comma separated, etc...) are valid and interchangeable. The same goes for urls, headers, status codes, queries, and size filters.
Include Headers
./feroxbuster -u http://127.1 -H Accept:application/json "Authorization: Bearer {token}"
IPv6, non-recursive scan with INFO-level logging enabled
./feroxbuster -u http://[::1] --no-recursion -vv
Read urls from STDIN; pipe only resulting urls out to another tool
cat targets | ./feroxbuster --stdin --silent -s 200 301 302 --redirects -x js | fff -s 200 -o js-files
Proxy traffic through Burp
./feroxbuster -u http://127.1 --insecure --proxy http://127.0.0.1:8080
Proxy traffic through a SOCKS proxy (including DNS lookups)
./feroxbuster -u http://127.1 --proxy socks5h://127.0.0.1:9050
Pass auth token via query parameter
./feroxbuster -u http://127.1 --query token=0123456789ABCDEF
🚀 Documentation has moved 🚀
For realsies, there used to be over 1300 lines in this README, but it's all been moved to the new documentation site. Go check it out!
✨🎉👉 DOCUMENTATION 👈🎉✨
Contributors ✨
Thanks goes to these wonderful people (emoji key):





































































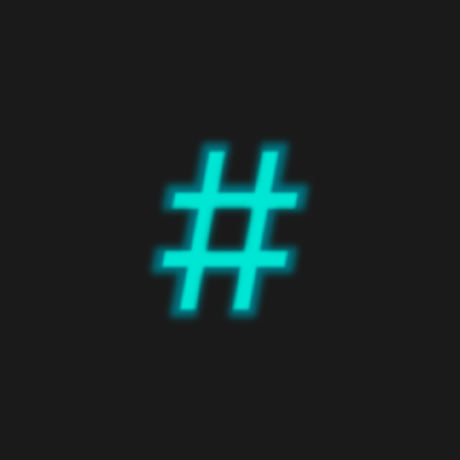























This project follows the all-contributors specification. Contributions of any kind welcome!
Dependencies
~29–54MB
~866K SLoC