13 releases
| 0.4.0 | Jan 13, 2025 |
|---|---|
| 0.3.6 | Nov 28, 2024 |
| 0.3.4 | Aug 12, 2024 |
| 0.3.3 | Dec 23, 2023 |
| 0.2.1 | Mar 30, 2023 |
#119 in Machine learning
818 downloads per month
455KB
9K
SLoC
![]()
MiniBoosts is a library for boosting algorithm researchers.
What is Boosting?
Boosting is a repeated game between a Booster and a Weak Learner.
For each round of the game,
- The Booster chooses a distribution over training examples,
- Then the Weak Learner chooses a hypothesis (function) whose accuracy w.r.t. the distribution is slightly better than random guessing.
After sufficient rounds, the Booster outputs a hypothesis that performs significantly better on training examples.
How to use this library
Write the following in your cargo.toml.
[dependencies]
minibosts = { version = "0.4.0" }
All boosting algorithms are implemented without Gurobi. but, if you have a Gurobi license, you can use the Gurobi version of the algorithms by setting:
[dependencies]
minibosts = { version = "0.4.0", features = ["gurobi"] }
[!CAUTION] Since I am no longer a student, I cannot check whether the compilation succeeded with the
"gurobi"flag.
Currently, following boosting algorithms are available:
BOOSTER |
FEATURE FLAG |
|---|---|
| AdaBoost by Freund and Schapire, 1997 |
|
| MadaBoost by Domingo and Watanabe, 2000 |
|
| GBM (Gradient Boosting Machine) by Jerome H. Friedman, 2001 |
|
| LPBoost by Demiriz, Bennett, and Shawe-Taylor, 2002 |
gurobi |
| SmoothBoost by Servedio, 2003 |
|
| AdaBoostV by Rätsch and Warmuth, 2005 |
|
| TotalBoost by Warmuth, Liao, and Rätsch, 2006 |
gurobi |
| SoftBoost by Warmuth, Glocer, and Rätsch, 2007 |
gurobi |
| ERLPBoost by Warmuth and Glocer, and Vishwanathan, 2008 |
gurobi |
| CERLPBoost (Corrective ERLPBoost) by Shalev-Shwartz and Singer, 2010 |
gurobi |
| MLPBoost by Mitsuboshi, Hatano, and Takimoto, 2022 |
gurobi |
| GraphSepBoost (Graph Separation Boosting) by Alon, Gonen, Hazan, and Moran, 2023 |
If you invent a new boosting algorithm,
you can introduce it by implementing Booster trait.
See cargo doc -F gurobi --open for details.
WEAK LEARNER |
|---|
| Decision Tree |
| Regression Tree |
| A worst-case weak learner for LPBoost |
| Gaussian Naive Bayes |
| Neural Network (Experimental) |
Why MiniBoosts?
If you write a paper about boosting algorithms, you need to compare your algorithm against others. At this point, some issues arise.
- Some boosting algorithms, such as LightGBM or XGBoost, are implemented and available for free. These are very easy to use in Python3 but hard to compare to other algorithms since they are implemented in C++ internally. Implementing your algorithm in Python3 makes the running time comparison unfair (Python3 is significantly slow compared to C++). However, implementing it in C++ is extremely hard (based on my experience).
- Most boosting algorithms are designed for a decision-tree weak learner even though the boosting protocol does not demand.
- There is no implementation for margin optimization boosting algorithms. Margin optimization is a better goal than empirical risk minimization in binary classification.
MiniBoosts is a crate to address the above issues.
This crate provides the followings.
- Two main traits, named
BoosterandWeakLearner.- If you invent a new Boosting algorithm,
all you need is to implement
Booster. - If you invent a new Weak Learning algorithm,
all you need is to implement
WeakLearner.
- If you invent a new Boosting algorithm,
all you need is to implement
- Some famous boosting algorithms, including AdaBoost, LPBoost, ERLPBoost, etc.
- Some weak learners, including Decision-Tree, Regression-Tree, etc.
MiniBoosts for reasearch
Sometimes, one wants to log each step of boosting procedure.
You can use Logger struct to output log to .csv file,
while printing the status like this:
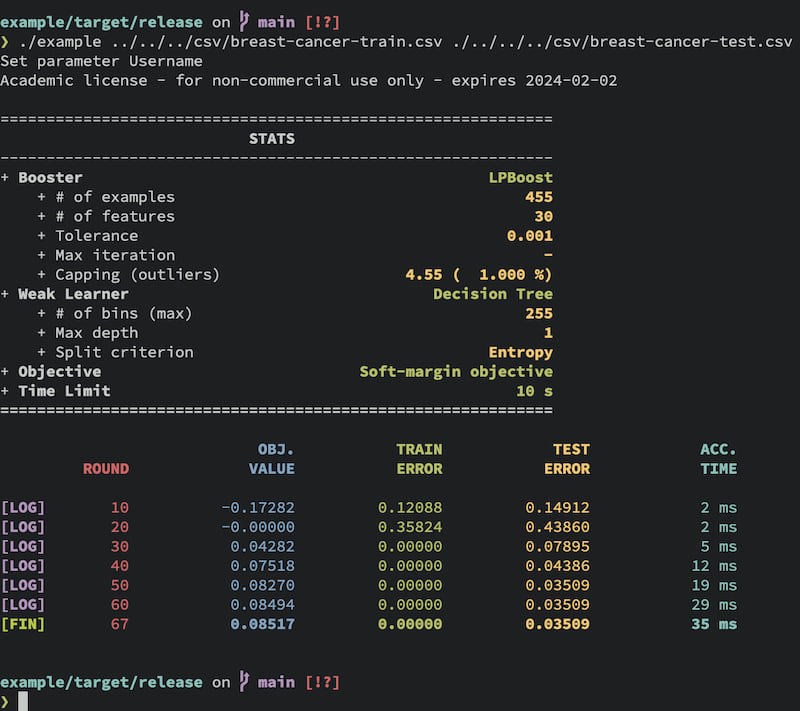
See Research feature section for detail.
Examples
Write the following to Cargo.toml.
miniboosts = { version = "0.4.0" }
If you want to use gurobi features, enable the flag:
miniboosts = { version = "0.4.0", features = ["gurobi"] }
Here is a sample code:
use miniboosts::prelude::*;
fn main() {
// Set file name
let file = "/path/to/input/data.csv";
// Read the CSV file
// The column named `class` corresponds to the labels (targets).
let sample = SampleReader::new()
.file(file)
.has_header(true)
.target_feature("class")
.read()
.unwrap();
// Set tolerance parameter as `0.01`.
let tol: f64 = 0.01;
// Initialize Booster
let mut booster = AdaBoost::init(&sample)
.tolerance(tol); // Set the tolerance parameter.
// Construct `DecisionTree` Weak Learner from `DecisionTreeBuilder`.
let weak_learner = DecisionTreeBuilder::new(&sample)
.max_depth(3) // Specify the max depth (default is 2)
.criterion(Criterion::Twoing) // Choose the split rule.
.build(); // Build `DecisionTree`.
// Run the boosting algorithm
// Each booster returns a combined hypothesis.
let f = booster.run(&weak_learner);
// Get the batch prediction for all examples in `data`.
let predictions = f.predict_all(&sample);
// You can predict the `i`th instance.
let i = 0_usize;
let prediction = f.predict(&sample, i);
// You can convert the hypothesis `f` to `String`.
let s = serde_json::to_string(&f);
}
If you use boosting for soft margin optimization, initialize booster like this:
let n_sample = sample.shape().0; // Get the number of training examples
let nu = n_sample as f64 * 0.2; // Set the upper-bound of the number of outliers.
let lpboost = LPBoost::init(&sample)
.tolerance(tol)
.nu(nu); // Set a capping parameter.
Note that the capping parameter must satisfies 1 <= nu && nu <= n_sample.
Research feature
This crate can output a CSV file for such values in each step.
Here is an example:
use miniboosts::prelude::*;
use miniboosts::{
Logger,
LoggerBuilder,
SoftMarginObjective,
};
// Define a loss function
fn zero_one_loss<H>(sample: &Sample, f: &H) -> f64
where H: Classifier
{
let n_sample = sample.shape().0 as f64;
let target = sample.target();
f.predict_all(sample)
.into_iter()
.zip(target.into_iter())
.map(|(fx, &y)| if fx != y as i64 { 1.0 } else { 0.0 })
.sum::<f64>()
/ n_sample
}
fn main() {
// Read the training data
let path = "/path/to/train/data.csv";
let train = SampleReader::new()
.file(path)
.has_header(true)
.target_feature("class")
.read()
.unwrap();
// Set some parameters used later.
let n_sample = train.shape().0 as f64;
let nu = 0.01 * n_sample;
// Read the test data
let path = "/path/to/test/data.csv";
let test = SampleReader::new()
.file(path)
.has_header(true)
.target_feature("class")
.read()
.unwrap();
let booster = LPBoost::init(&train)
.tolerance(0.01)
.nu(nu);
let weak_learner = DecisionTreeBuilder::new(&train)
.max_depth(2)
.criterion(Criterion::Entropy)
.build();
// Set the objective function.
// One can use your own function by implementing ObjectiveFunction trait.
let objective = SoftMarginObjective::new(nu);
let mut logger = LoggerBuilder::new()
.booster(booster)
.weak_learner(tree)
.train_sample(&train)
.test_sample(&test)
.objective_function(objective)
.loss_function(zero_one_loss)
.time_limit_as_secs(120) // Terminate after 120 seconds
.print_every(10) // Print log every 10 rounds.
.build();
// Each line of `lpboost.csv` contains the following four information:
// Objective value, Train loss, Test loss, Time per iteration
// The returned value `f` is the combined hypothesis.
let f = logger.run("logfile.csv")
.expect("Failed to logging");
}
Others
- Currently, this crate mainly supports boosting algorithms for binary classification.
- Some boosting algorithms use Gurobi optimizer,
so you must acquire a license to use this library.
If you have the license, you can use these boosting algorithms (boosters)
by specifying
features = ["gurobi"]inCargo.toml. The compilation fails if you try to use the gurobi feature without a Gurobi license. - One can log your algorithm by implementing
Researchtrait. - Run
cargo doc -F gurobi --opento see more information. GraphSepBoostonly supports the aggregation rule shown in Lemma 4.2 of their paper.
Future work
-
Boosters
-
Weak Learners
- Bag of words
- TF-IDF
- RBF-Net
Dependencies
~18–27MB
~443K SLoC