3 releases
| 0.1.2 | Jan 17, 2023 |
|---|---|
| 0.1.1 | Jan 15, 2023 |
| 0.1.0 | Jan 15, 2023 |
#538 in Machine learning
34KB
810 lines
🧠 mindflow 🌊
The ChatGPT-powered swiss army knife for the modern developer! We provide an AI-powered CLI git wrapper, boilerplate code generator, code search engine, a conversation history manager, and much more!

Features
- Using the CLI Chat bot
- Code Generator
- Managing Chat History
- Git Diff Summaries
- Automatic Git Commits
- Automatic Pull Requests
- Use-case showcase
Demo
Join Our Community!
- Follow us on Twitter
- Join our discord
- BONUS: Consider becoming a patron ❤️
Getting Started
Pre-requisite:
- You'll need to create an OpenAI account.
- Also, create a Pinecone account to use their vector database if you would like to use the
chat with documentsfeature.
- Install Mindflow:
- If you are on Mac OS and have brew, run:
brew tap mindflowai/homebrew-mindflow && brew install mindflow
- Otherwise run:
pip install mindflow
- Or you can clone this repo and run:
pip install -e path/to/mindflow
- Note: if you are not install in a conda environment, you may need to add the package to your path. Please ask for help in our discord if you run into any issues!
- Run
mf login: - Now, you're ready to start using MindFlow!
Basic Usage
Configuration (Optional)
Configure the model used for generating responses by running mf config and selecting either GPT 3.5 Turbo (default) or GPT 4. In order to use GPT 4, you'll need to have special access to the API. If you have access, you can run mf config and select GPT 4. If you don't have access, you'll get an error message.
- Sign up for GPT 4 access here. uest
Chats
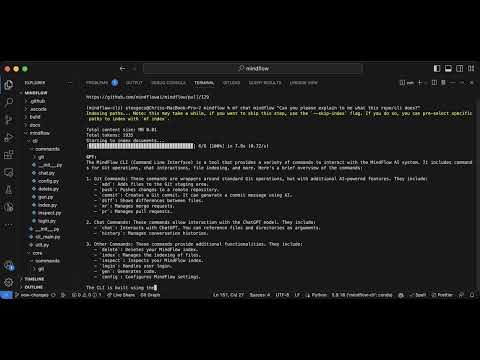
There are multiple levels to using mindflow's chat feature.
- Simplest
mf chat "explain what a programming language is"- Interact with chatGPT directly just like on the chatGPT website. We also have chat persistence, so it will remember the previous chat messages.
- With File Context
mf chat path/to/code.py "please summarize what this code does"- You can provide single or multi-file context to chatGPT by passing in any number of files as a separate argument in the
mf chatcall. For sufficiently small files (see: chatGPT token limits), this will work and also maintain chat history.
- You can provide single or multi-file context to chatGPT by passing in any number of files as a separate argument in the
- With Directory Context
mf chat path/to/submodule1/ path/to/submodule2/ "what are these submodules responsible for?"- Providing directories will actually run an indexer over your code subdirectories/files recursively. So it may take a while to fully index everything -- don't worry; we'll warn you if the cost becomes a concern! Right now the warning triggers if the index job costs >$0.50USD.
- Custom pre-indexed context
mf index path/to/subdir/file1.txt path/to/file2.txtmf chat -s ./ "How do all of my classes relate to one another?"- If you pre-index your repository, you can narrow the scope for the context provided to the chat. Passing
-swill skip the auto-indexing, and instead will defer to the currently existing index. This index is generated in the first stepmf indexwhere only those files/subdirs will be included. - This can save you time and money if your repository is significantly large.
- If you pre-index your repository, you can narrow the scope for the context provided to the chat. Passing
Code Generator
You can use mindflow to generate boilerplate code in an instant using mf gen! It should only generate code and comments, and will save the file in the path given.
Here's a couple examples:
mf gen setup.py "write me a setup.py file for my python package 'foobar'"mf gen main.py "write me a python script with a main if block that prints the first 10 fibonacci numbers"
Chat History
By default, simple chat messages (when referencing no files or very small files) will be stored locally so that you can retain chat persistence.
To see stats about your chat history, you can run mf history stats.
If you want to clear your chat history, you can run mf history clear and it will forget all previous messages that you've sent.
If you try adding directories to your chat messages, chat persistence will be disabled, and no previous context will be used. This will change as MindFlow matures, and the openAI API supports more token levels/conversation histories natively.
Git Diff Summaries
Note: Git diff summaries do not support chat persistence yet.
Make some changes to your git repo without staging/committing them. Then, run mf diff! You should get a response that looks like this:
`mindflow/commands/diff.py` changes:
- Added import statement for `List` and `Tuple` from the `typing` module.
- Added a function `parse_git_diff` that takes in the output of a `git diff` command and returns a list of tuples containing the file name and the diff content.
- Added a function `batch_git_diffs` that takes in the list of tuples returned by `parse_git_diff` and batches them into smaller chunks of diffs that are less than 3000 characters long.
- Modified the `diff` function to use the new `parse_git_diff` and `batch_git_diffs` functions to batch the diffs and send them to the GPT model for processing.
`mindflow/commands/inspect.py` changes:
- Removed the `print` statement used to output the result of a database query. The git diff shows changes in two files: `mindflow/commands/diff.py` and `mindflow/commands/inspect.py`.
`mindflow/commands/diff.py` changes:
- Added import statement for `List` and `Tuple` from the `typing` module.
- Added a function `parse_git_diff` that takes in the output of a `git diff` command and returns a list of tuples containing the file name and the diff content.
- Added a function `batch_git_diffs` that takes in the list of tuples returned by `parse_git_diff` and batches them into smaller chunks of diffs that are less than 3000 characters long.
- Modified the `diff` function to use the new `parse_git_diff` and `batch_git_diffs` functions to batch the diffs and send them to the GPT model for processing.
`mindflow/commands/inspect.py` changes:
- Removed the `print` statement used to output the result of a database query.
Automatic Git Commits
Make some changes to your git repo and stage them. Then, run mf commit! You should get a response that looks like this:
[formatting 7770179] Add needs_push() function and check in run_pr() function.
1 file changed, 14 insertions(+)
Automatic Pull Requests
Make some changes to your branch and stage, and then commit them. Then, run mf pr for GitHub or mf mr for GitLab! A pull request/merge request should be created with a title and body generated by GPT, and a link to the PR should be printed to the console.
- To use this feature, you must first install and authenticate the GitHub CLI.
Showcase
Chat Persistence and File Context!
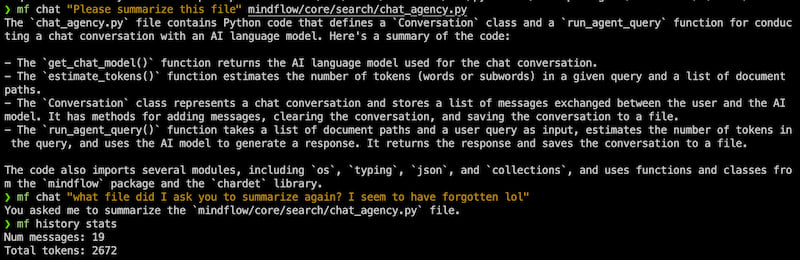
Generating a setup.py
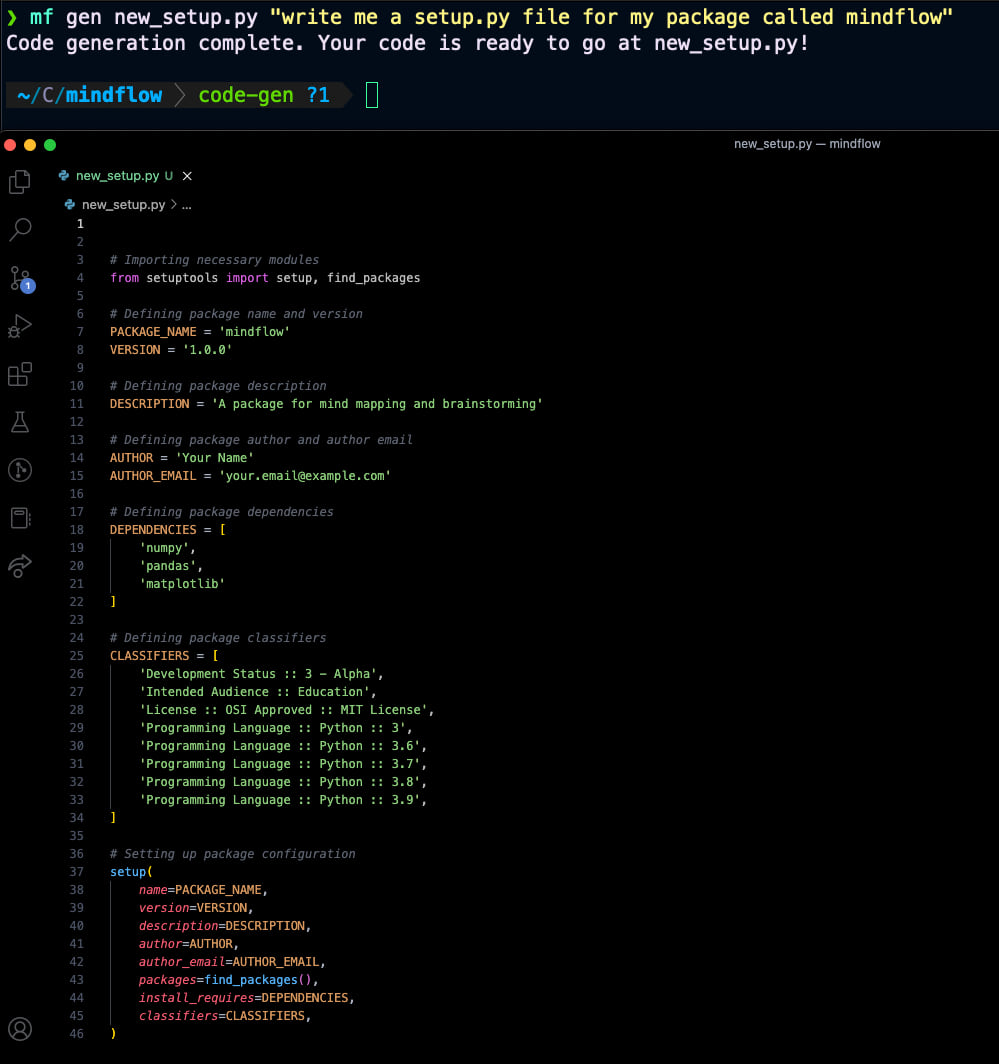
Generating an arbitrary program file
How does it work?
MindFlow uses state-of-the-art methods for high-throughput segmentation, processing, storage, and retrieval of documents using a recursive hierarchical summarization and embedding technique to store embedding vectors for document chunks and then achieve fast, and high-quality responses to questions and tasks by appending similar document chunks based on the hierarchically embedded text and using them as context for you query. Additionally, chat history will persist if it can fit in the context for queries over indexed documents or for regular chat.
What's next for MindFlow
In the future, MindFlow plans on becoming an even more integral part of the modern developer's toolkit. We plan on adding the ability to ditch traditional documentation and instead integrate directly with your private documents and communication channels, allowing for a more seamless and intuitive experience. With MindFlow, you can have a true "stream of consciousness" with your code, documentation, and communication channels, making it easier than ever to stay on top of your projects and collaborate with your team. We are excited to continue pushing the boundaries of what's possible with language models and revolutionizing how developers work.
Dependencies
~15–27MB
~376K SLoC