4 releases
| 0.2.0 | Jun 24, 2024 |
|---|---|
| 0.1.2 | Jan 23, 2024 |
| 0.1.1 | Jan 6, 2024 |
| 0.1.0 | Aug 9, 2023 |
#284 in Science
22 downloads per month
135KB
3K
SLoC
llmvm-codeassist
A LLM-powered code assistant that automatically retrieves context (i.e. type definitions) from a Language Server Protocol server. A frontend for llmvm.
Acts as a middleman between the code editor and the real LSP server. Uses the standard LSP specification for compatibility with various editors.
Only tested with the Helix editor and the Rust language server.
Features
- Code completion commands available in editor code actions menu
- Uses LSP to automatically gather type definitions for context
- Ability to manually add context for code completions
- Ability to select a model for code completion
- Code completion using multiple models simultaneously
Demo
Simple example using the editor code action menu:
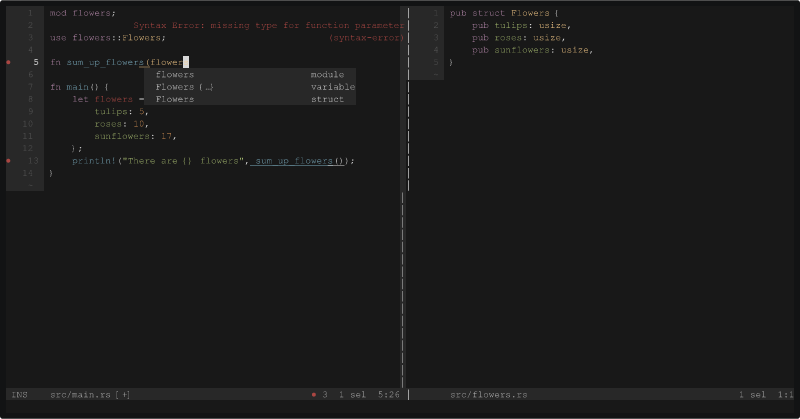
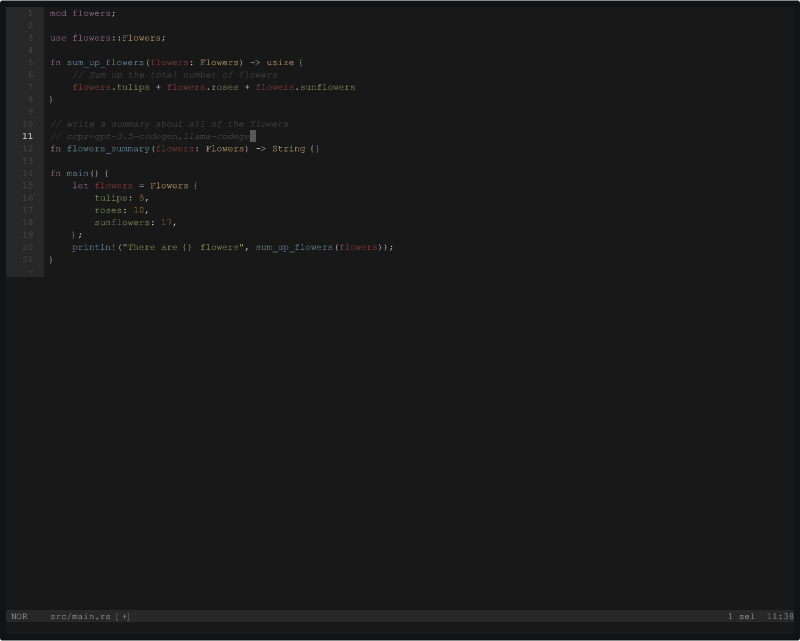
Example generating multiple code completions, via multiple llmvm presets (using the ccpr= directive):
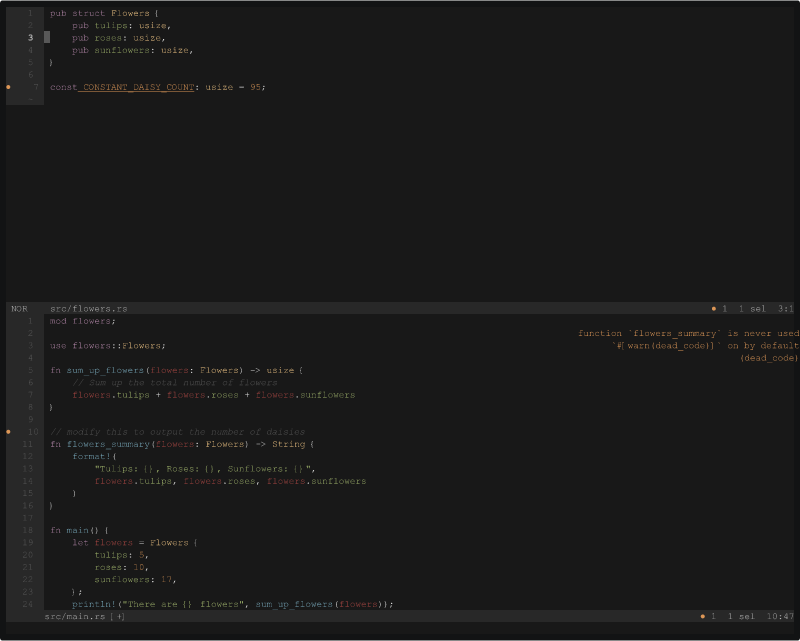
Manually adding context to code completion requests:
Quick start
Install this application using cargo.
cargo install llmvm-codeassist
The llmvm core must be installed. If you have not done so, the core may be installed via
cargo install llmvm-core
A backend must be installed and configured. The llmvm-outsource is recommended for OpenAI/HuggingFace/Ollama requests.
To install the outsource backend, run
cargo install llmvm-outsource
See Configuration in llmvm-outsource for configuring OpenAI/Ollama endpoints/API keys.
Currently, the default model preset is gpt-3.5-codegen which uses the outsource backend.
Usage
Your code editor must be configured to use llmvm-codeassist as the primary LSP server. The command for the real LSP language server must be appended to the arguments of llmvm-codeassist.
Here is an example of a Helix languages.toml configuration for the Rust language:
[language-server.llmvm-codeassist-rust]
command = "llmvm-codeassist"
args = ["rust-analyzer"]
[[language]]
name = "rust"
language-servers = [ "llmvm-codeassist-rust" ]
Code completion commands can be called by selecting uncompleted code, and invoking the code actions menu.
Selecting a model preset / multiple code generation requests
One or more llmvm model presets can be selected by providing the ccpr= directive in a code comment.
For example:
// ccpr=my-model-codegen
Multiple models can be selected by using a comma as a delimiter. See the second demo above for an example.
Manual context selection
Snippets of workspace code can be added to code generation requests manually, if need be. To do so, select the relevant snippet, invoke the code actions menu and select "Manually add...".
The snippet will be appended to the next code generation request.
Configuration
Run the codeassist executable to generate a configuration file at:
- Linux:
~/.config/llmvm/codeassist.toml. - macOS:
~/Library/Application Support/com.djandries.llmvm/codeassist.toml - Windows:
AppData\Roaming\djandries\llmvm\config\codeassist.toml
| Key | Required? | Description |
|---|---|---|
default_preset |
No | Default llmvm model preset to use for code completion. Currently defaults to gpt-3.5-codegen. |
prefer_insert_in_place |
No | If set to true, will replace selected text with completed text if a single-model code completion is performed. |
stream_snippets |
No | Streams each generated token to the editor in real time. |
use_chat_threads |
No | If set to true, chat threads will be used to provide context from previous requests. Note that results from requests that utilize multiple presets (via ccpr) will not be stored in the thread. |
tracing_directive |
No | Logging directive/level for tracing |
stdio_core |
No | Stdio client configuration for communicated with llmvm core. See llmvm-protocol for details. |
http_core |
No | HTTP client configuration for communicating with llmvm core. See llmvm-protocol for details. |
Logging
Logs will be saved to the logs directory of the current llmvm project directory, or global user data directory.
The global logs directory is located at:
- Linux:
~/.local/share/llmvm/logs. - macOS:
~/Library/Application Support/com.djandries.llmvm/logs - Windows:
AppData\Roaming\djandries\llmvm\data\logs
How it works
The code assistant forwards most LSP requests to the real LSP server, and hijacks/edits certain request or response payloads if they are relevant. The code action menu response is modified to show the code completion commands. Actual code completion commands sent by the user are handled by the code assistant, and are not sent to the real LSP server.
Requests are made to the LSP server to retrieve type definition information. Context is automatically retrieved by following this process:
- Assistant asks LSP server for all symbol positions.
- For each symbol, the assistant requests a type definition location.
- A folding range is requested for each type definition location.
- A text snippet is retrieved from the filesystem for each folding range.
License
Dependencies
~21–33MB
~594K SLoC