69 releases
| 0.28.0 | Mar 10, 2025 |
|---|---|
| 0.27.2 | Nov 19, 2024 |
| 0.26.0 | Jun 16, 2024 |
| 0.25.5 | Feb 28, 2024 |
| 0.8.0 | Oct 29, 2020 |
#20 in Game dev
1,244 downloads per month
Used in 5 crates
(4 directly)
705KB
17K
SLoC
![]()
![]()
![]()
Jomini
A low level, performance oriented parser for save and game files from Paradox Development Studio titles (eg: Europa Universalis (EU4), Hearts of Iron (HOI4), and Crusader Kings (CK3), Imperator, Stellaris, and Victoria).
For an in-depth look at the Paradox Clausewitz format and the pitfalls that come trying to support all variations, consult the write-up. In short, it's extremely difficult to write a robust and fast parser that abstracts over the format difference between games as well as differences between game patches. Jomini hits the sweet spot between flexibility while still being ergonomic.
Jomini is the cornerstone of the online EU4 save file analyzer. This library also powers the Paradox Game Converters and pdxu.
Features
- ✔ Versatile: Handle both plaintext and binary encoded data
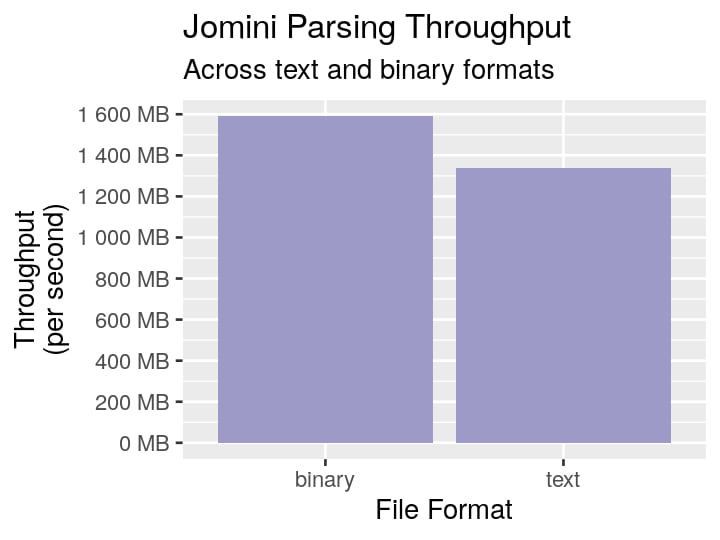
- ✔ Fast: Parse data at over 1 GB/s
- ✔ Small: Compile with zero dependencies
- ✔ Safe: Extensively fuzzed against potential malicious input
- ✔ Ergonomic: Use serde-like macros to have parsing logic automatically implemented
- ✔ Embeddable: Cross platform native apps, statically compiled services, or in the browser via Wasm
Quick Start
Below is a demonstration of deserializing plaintext data using serde. Several additional serde-like attributes are used to reconcile the serde data model with structure of these files.
use jomini::{
text::{Operator, Property},
JominiDeserialize,
};
#[derive(JominiDeserialize, PartialEq, Debug)]
pub struct Model {
human: bool,
first: Option<u16>,
third: Property<u16>,
#[jomini(alias = "forth")]
fourth: u16,
#[jomini(alias = "core", duplicated)]
cores: Vec<String>,
names: Vec<String>,
#[jomini(take_last)]
checksum: String,
}
let data = br#"
human = yes
third < 5
forth = 10
core = "HAB"
names = { "Johan" "Frederick" }
core = FRA
checksum = "first"
checksum = "second"
"#;
let expected = Model {
human: true,
first: None,
third: Property::new(Operator::LessThan, 5),
fourth: 10,
cores: vec!["HAB".to_string(), "FRA".to_string()],
names: vec!["Johan".to_string(), "Frederick".to_string()],
checksum: "second".to_string(),
};
let actual: Model = jomini::text::de::from_windows1252_slice(data)?;
assert_eq!(actual, expected);
Binary Deserialization
Deserializing data encoded in the binary format is done in a similar fashion but with a couple extra steps for the caller to supply:
- How text should be decoded (typically Windows-1252 or UTF-8)
- How rational (floating point) numbers are decoded
- How tokens, which are 16 bit integers that uniquely identify strings, are resolved
Implementors be warned, not only does each Paradox game have a different binary format, but the binary format can vary between patches!
Below is an example that defines a sample binary format and uses a hashmap token lookup.
use jomini::{Encoding, JominiDeserialize, Windows1252Encoding, binary::BinaryFlavor};
use std::{borrow::Cow, collections::HashMap};
#[derive(JominiDeserialize, PartialEq, Debug)]
struct MyStruct {
field1: String,
}
#[derive(Debug, Default)]
pub struct BinaryTestFlavor;
impl jomini::binary::BinaryFlavor for BinaryTestFlavor {
fn visit_f32(&self, data: [u8; 4]) -> f32 {
f32::from_le_bytes(data)
}
fn visit_f64(&self, data: [u8; 8]) -> f64 {
f64::from_le_bytes(data)
}
}
impl Encoding for BinaryTestFlavor {
fn decode<'a>(&self, data: &'a [u8]) -> Cow<'a, str> {
Windows1252Encoding::decode(data)
}
}
let data = [ 0x82, 0x2d, 0x01, 0x00, 0x0f, 0x00, 0x03, 0x00, 0x45, 0x4e, 0x47 ];
let mut map = HashMap::new();
map.insert(0x2d82, "field1");
let actual: MyStruct = BinaryTestFlavor.deserialize_slice(&data[..], &map)?;
assert_eq!(actual, MyStruct { field1: "ENG".to_string() });
When done correctly, one can use the same structure to represent both the plaintext and binary data without any duplication.
One can configure the behavior when a token is unknown (ie: fail immediately or try to continue).
Direct identifier deserialization with token attribute
There may be some performance loss during binary deserialization as
tokens are resolved to strings via a TokenResolver and then matched against the
string representations of a struct's fields.
We can fix this issue by directly encoding the expected token value into the struct:
#[derive(JominiDeserialize, PartialEq, Debug)]
struct MyStruct {
#[jomini(token = 0x2d82)]
field1: String,
}
// Empty token to string resolver
let map = HashMap::<u16, String>::new();
let actual: MyStruct = BinaryDeserializer::builder_flavor(BinaryTestFlavor)
.deserialize_slice(&data[..], &map)?;
assert_eq!(actual, MyStruct { field1: "ENG".to_string() });
Couple notes:
- This does not obviate need for the token to string resolver as tokens may be used as values.
- If the
tokenattribute is specified on one field on a struct, it must be specified on all fields of that struct.
Caveats
Before calling any Jomini API, callers are expected to:
- Determine the correct format (text or binary) ahead of time.
- Strip off any header that may be present (eg:
EU4txt/EU4bin) - Provide the token resolver for the binary format
- Provide the conversion to reconcile how, for example, a date may be encoded as an integer in the binary format, but as a string when in plaintext.
The Mid-level API
If the automatic deserialization via JominiDeserialize is too high level, there is a mid-level
api where one can easily iterate through the parsed document and interrogate fields for
their information.
use jomini::TextTape;
let data = b"name=aaa name=bbb core=123 name=ccc name=ddd";
let tape = TextTape::from_slice(data).unwrap();
let reader = tape.windows1252_reader();
for (key, _op, value) in reader.fields() {
println!("{:?}={:?}", key.read_str(), value.read_str().unwrap());
}
For even lower level of parisng, see the respective binary and text documentation.
The mid-level API also provides the excellent utility of converting the
plaintext Clausewitz format to JSON when the json feature is enabled.
use jomini::TextTape;
let tape = TextTape::from_slice(b"foo=bar")?;
let reader = tape.windows1252_reader();
let actual = reader.json().to_string()?;
assert_eq!(actual, r#"{"foo":"bar"}"#);
Write API
There are two targeted use cases for the write API. One is when a text tape is on hand. This is useful when one needs to reformat a document (note that comments are not preserved):
use jomini::{TextTape, TextWriterBuilder};
let tape = TextTape::from_slice(b"hello = world")?;
let mut out: Vec<u8> = Vec::new();
let mut writer = TextWriterBuilder::new().from_writer(&mut out);
writer.write_tape(&tape)?;
assert_eq!(&out, b"hello=world");
The writer normalizes any formatting issues. The writer is not able to losslessly write all parsed documents, but these are limited to truly esoteric situations and hope to be resolved in future releases.
The other use case is geared more towards incremental writing that can be found in melters or those crafting documents by hand. These use cases need to manually drive the writer:
use jomini::TextWriterBuilder;
let mut out: Vec<u8> = Vec::new();
let mut writer = TextWriterBuilder::new().from_writer(&mut out);
writer.write_unquoted(b"hello")?;
writer.write_unquoted(b"world")?;
writer.write_unquoted(b"foo")?;
writer.write_unquoted(b"bar")?;
assert_eq!(&out, b"hello=world\nfoo=bar");
Unsupported Syntax
Due to the nature of Clausewitz being closed source, this library can never guarantee compatibility with Clausewitz. There is no specification of what valid input looks like, and we only have examples that have been collected in the wild. From what we do know, Clausewitz is recklessly flexible: allowing each game object to potentially define its own unique syntax.
We can only do our best and add support for new syntax as it is encountered.
Benchmarks
Benchmarks are ran with the following command:
cargo clean
cargo bench -- parse
find ./target -wholename "*/new/raw.csv" -print0 | xargs -0 xsv cat rows > assets/jomini-benchmarks.csv
And can be analyzed with the R script found in the assets directory.
Below is a graph generated from benchmarking on an arbitrary computer.