10 releases
| 0.2.1 | Jun 2, 2023 |
|---|---|
| 0.2.0 | May 9, 2023 |
| 0.1.9 | May 9, 2023 |
| 0.1.6 | Apr 30, 2023 |
#498 in Hardware support
110 downloads per month
37KB
579 lines
fath 
fa(st ma)th
A math library written in Rust, built for speed.
Includes configurable-precision approximations and exact functions for both ints and floats. Uses cross-platform intrinsics and SIMD whenever possible.
This library heavily relies on unsafe and nightly features to achieve the best performance. The primary use case for this library is in games or graphics development, where speed matters more than precision
When using SIMD functions in this package, compile with lto="fat" or lto="thin" and opt-level=3 to ensure that auto-vectorization takes place. All SIMD functions have a feature cap at AVX2, and nothing in this library utilizes anything from AVX512. If certain functions vectorize on lower requirements, that's a bonus.
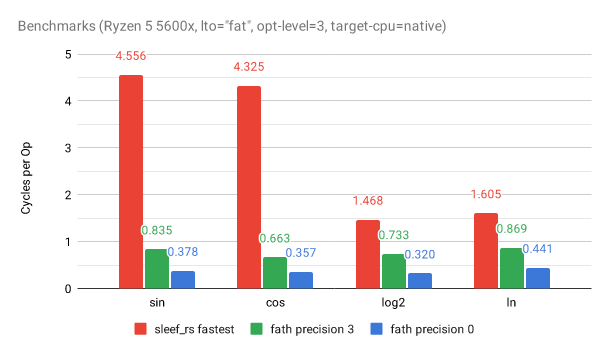
Comparison to sleef-rs
Most of the functions in here are faster than equivalent functions in sleef, at the expense of safety.
Sleef's sin_fast and cos_fast are slightly less precise than fath's sin_fast_approx::<3>. The main performance detriment to sleef's is the branch that happens in it when it's outside the range of being within 350 ULPs. However, fath also includes additional optimizations for it. Sleef's log2_u35 and ln_u35 functions are its fastest implementations, and are much more accurate than fath's, being withing 3.5 ULPs. Fath is much less accurate, but achieves much better performance due to additional optimizations and less strict precision requirements.
"Cycles per Op" in this chart is calculated from the average cycles per 8-lane function iteration, divided by 8. This simulates a best-case scenario of maximum throughput.
Currently Implemented Functions
Approximate f32 Functions:
Allows setting a variable precision level as a const generic.
sinandcos- Does include wrapping with a range reduction, but will become less accurate as the input gets larger.
- Includes equivalent functions without a range reduction
log(constbase and variable base)- This is based on a log base 2 approximation, and is scaled for other bases. The fastest version of this is
constbase 2.0.
- This is based on a log base 2 approximation, and is scaled for other bases. The fastest version of this is
Exact Unsigned Integer Functions:
ilogwithconstbase- Has multiple implementations depending on the base to achieve maximum performance. The fastest impl is for log base 2.
expwithconstcoefficient- Similar to previous function, but calculates
COEFF^xinstead.
- Similar to previous function, but calculates
Contributing
Any help on the library is greatly appreciated. If you'd like to contribute, just submit a PR and I'll respond to it as soon as I can. For development, I'd recommend looking at the genertated assembly often. For development of individual functions, I would recommend using a tool like Compiler Explorer, and using something like llvm-mca (available in CE under "tools") often to get an idea of performance on different platforms.