19 releases
| 0.8.12 | May 8, 2025 |
|---|---|
| 0.8.11 | Mar 3, 2024 |
| 0.8.10 | Feb 27, 2024 |
| 0.8.7 | Dec 29, 2023 |
| 0.1.18 |
|
#4 in Data structures
13,521,555 downloads per month
Used in 18,635 crates
(951 directly)
135KB
3K
SLoC
aHash 


AHash is the fastest, DOS resistant hash currently available in Rust. AHash is intended exclusively for use in in-memory hashmaps.
AHash's output is of high quality but aHash is not a cryptographically secure hash.
Design
Because AHash is a keyed hash, each map will produce completely different hashes, which cannot be predicted without knowing the keys. This prevents DOS attacks where an attacker sends a large number of items whose hashes collide that get used as keys in a hashmap.
This also avoids accidentally quadratic behavior by reading from one map and writing to another.
Goals and Non-Goals
AHash does not have a fixed standard for its output. This allows it to improve over time. For example, if any faster algorithm is found, aHash will be updated to incorporate the technique. Similarly, should any flaw in aHash's DOS resistance be found, aHash will be changed to correct the flaw.
Because it does not have a fixed standard, different computers or computers on different versions of the code will observe different hash values.
As such, aHash is not recommended for use other than in-memory maps. Specifically, aHash is not intended for network use or in applications which persist hashed values.
(In these cases HighwayHash would be a better choice)
Additionally, aHash is not intended to be cryptographically secure and should not be used as a MAC, or anywhere which requires a cryptographically secure hash.
(In these cases SHA-3 would be a better choice)
Usage
AHash is a drop in replacement for the default implementation of the Hasher trait. To construct a HashMap using aHash
as its hasher do the following:
use ahash::{AHasher, RandomState};
use std::collections::HashMap;
let mut map: HashMap<i32, i32, RandomState> = HashMap::default();
map.insert(12, 34);
For convenience, wrappers called AHashMap and AHashSet are also provided.
These do the same thing with slightly less typing.
use ahash::AHashMap;
let mut map: AHashMap<i32, i32> = AHashMap::new();
map.insert(12, 34);
map.insert(56, 78);
Flags
The aHash package has the following flags:
std: This enables features which require the standard library. (On by default) This includes providing the utility classesAHashMapandAHashSet.serde: Enablesserdesupport for the utility classesAHashMapandAHashSet.runtime-rng: To obtain a seed for Hashers will obtain randomness from the operating system. (On by default) This is done using the getrandom crate.compile-time-rng: For OS targets without access to a random number generator,compile-time-rngprovides an alternative. Ifgetrandomis unavailable andcompile-time-rngis enabled, aHash will generate random numbers at compile time and embed them in the binary.nightly-arm-aes: To use AES instructions on 32-bit ARM, which requires nightly. This is not needed on AArch64. This allows for DOS resistance even if there is no random number generator available at runtime (assuming the compiled binary is not public). This makes the binary non-deterministic. (If non-determinism is a problem see constrandom's documentation)
If both runtime-rng and compile-time-rng are enabled the runtime-rng will take precedence and compile-time-rng will do nothing.
If neither flag is set, seeds can be supplied by the application. Multiple apis
are available to do this.
Comparison with other hashers
A full comparison with other hashing algorithms can be found here
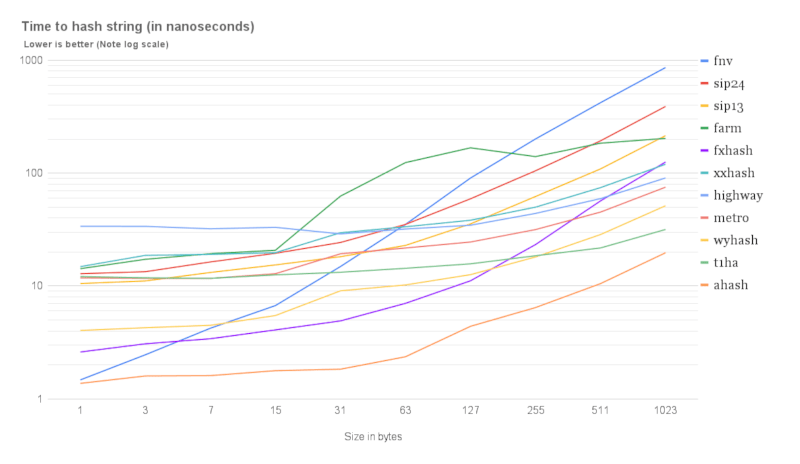
For a more representative performance comparison which includes the overhead of using a HashMap, see HashBrown's benchmarks as HashBrown now uses aHash as its hasher by default.
Hash quality
AHash passes the full SMHasher test suite.
The code to reproduce the result, and the full output are checked into the repo.
Additional FAQ
A separate FAQ document is maintained here. If you have questions not covered there, open an issue here.
License
Licensed under either of:
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
Dependencies
~0.6–1.4MB
~21K SLoC