18 stable releases (4 major)
Uses old Rust 2015
| 4.1.0 | Jan 16, 2021 |
|---|---|
| 4.0.1 | Jun 27, 2020 |
| 4.0.0 | Jan 31, 2020 |
| 3.0.7 | Jan 28, 2020 |
| 0.2.0 | Nov 20, 2016 |
#64 in Algorithms
3,073,753 downloads per month
Used in 1,586 crates
(115 directly)
44KB
689 lines
SeaHash: A bizarrely fast hash function.
SeaHash is a hash function with performance better than (around 3-20% improvement) xxHash and MetroHash. Furthermore, SeaHash has mathematically provable statistical guarantees.
In action:

lib.rs:
SeaHash: A blazingly fast, portable hash function with proven statistical guarantees.
SeaHash is a hash function with performance better than (around 3-20% improvement) xxHash and MetroHash. Furthermore, SeaHash has mathematically provable statistical guarantees.
SeaHash is a portable hash function, meaning that the output is not dependent on the hosting architecture, and makes no assumptions on endianness or the alike. This stable layout allows it to be used for on-disk/permanent storage (e.g. checksums).
Design, advantages, and features
- High quality: It beats most other general purpose hash functions because it provides full avalanche inbetween state updates.
- Performance: SeaHash beats every high-quality (grading 10/10 in smhasher) hash function that I know of.
- Provable quality guarantees: Contrary to most other non-cryptographic hash function, SeaHash can be proved to satisfy the avalanche criterion as well as BIC.
- Parallelizable: Consists of multiple, independent states to take advantage of ILP and/or software threads.
- Bulk reads: Reads 8 or 4 bytes a time.
- Stable and portable: Does not depend on the target architecture, and produces a stable value, which is only changed in major version bumps.
- Keyed: Designed to not leak the seed/key. Note that it has not gone through cryptoanalysis yet, so the keyed version shouldn't be relied on when security is needed.
- Hardware accelerateable: SeaHash is designed such that ASICs can implement it with really high performance.
A word of warning!
This is not a cryptographic function, and it certainly should not be used as one. If you want a good cryptographic hash function, you should use SHA-3 (Keccak) or BLAKE2.
It is not secure, nor does it aim to be. It aims to have high quality pseudorandom output and few collisions, as well as being fast.
Benchmark
On normal hardware, it is expected to run with a rate around 5.9-6.7 GB/S on a 2.5 GHz CPU. Further improvement can be seen when hashing very big buffers in parallel.
| Function | Quality | Cycles per byte (lower is better) | Author |
|---|---|---|---|
| SeaHash | Excellent | 0.24 | Ticki |
| xxHash | Excellent | 0.31 | Collet |
| MetroHash | Excellent | 0.35 | Rogers |
| Murmur | Excellent | 0.64 | Appleby |
| Rabin | Medium | 1.51 | Rabin |
| CityHash | Excellent | 1.62 | Pike, Alakuijala |
| LoseLose | Terrible | 2.01 | Kernighan, Ritchie |
| FNV | Poor | 3.12 | Fowler, Noll, Vo |
| SipHash | Pseudorandom | 3.21 | Aumasson, Bernstein |
| CRC | Good | 3.91 | Peterson |
| DJB2 | Poor | 4.13 | Bernstein |
Ideal architecture
SeaHash is designed and optimized for the most common architecture in use:
- Little-endian
- 64-bit
- 64 or more bytes cache lines
- 4 or more instruction pipelines
- 4 or more 64-bit registers
Anything that does not hold the above requirements will perform worse by up to 30-40%. Note that this means it is still faster than CityHash (~1 GB/S), MurMurHash (~2.6 GB/S), FNV (~0.5 GB/S), etc.
Achieving the performance
Like any good general-purpose hash function, SeaHash reads 8 bytes at once effectively reducing the running time by an order of ~5.
Secondly, SeaHash achieves the performance by heavily exploiting Instruction-Level Parallelism. In particular, it fetches 4 integers in every round and independently diffuses them. This yields four different states, which are finally combined.
Statistical guarantees
SeaHash comes with certain proven guarantees about the statistical properties of the output:
- Pick some n-byte sequence, s. The number of n-byte sequence colliding with s is independent of the choice of s (all equivalence class have equal size).
- If you flip any bit in the input, the probability for any bit in the output to be flipped is 0.5.
- The hash value of a sequence of uniformly distributed bytes is itself uniformly distributed.
The first guarantee can be derived through deduction, by proving that the diffusion function is bijective (reverse the XORs and find the congruence inverses to the primes).
The second guarantee requires more complex calculations: Construct a matrix of probabilities and set one to certain (1), then apply transformations through the respective operations. The proof is a bit long, but relatively simple.
The third guarantee requires proving that the hash value is a tree, such that:
- Leafs represents the input values.
- Single-child nodes reduce to the diffusion of the child.
- Multiple-child nodes reduce to the sum of the children.
Then simply show that each of these reductions transform uniformly distributed variables to uniformly distributed variables.
Inner workings
In technical terms, SeaHash follows a alternating 4-state length-padded Merkle–Damgård construction with an XOR-diffuse compression function (click to enlarge):
[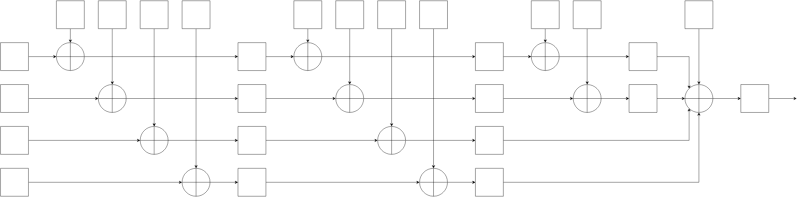 ]
(http://ticki.github.io/img/seahash_construction_diagram.svg)
]
(http://ticki.github.io/img/seahash_construction_diagram.svg)
It starts with 4 initial states, then it alternates between them (increment, wrap on 4) and does XOR with the respective block. When a state has been visited the diffusion function (f) is applied. The very last block is padded with zeros.
After all the blocks have been gone over, all the states are XOR'd to the number of bytes written. The sum is then passed through the diffusion function, which produces the final hash value.
The diffusion function is drawn below.
x ← px
x ← x ⊕ ((x ≫ 32) ≫ (x ≫ 60))
x ← px
The advantage of having four completely segregated (note that there is no mix round, so they're entirely independent) states is that fast parallelism is possible. For example, if I were to hash 1 TB, I can spawn up four threads which can run independently without any intercommunication or synchronization before the last round.
If the diffusion function (f) was cryptographically secure, it would pass cryptoanalysis trivially. This might seem irrelevant, as it clearly isn't cryptographically secure, but it tells us something about the inner semantics. In particular, any diffusion function with sufficient statistical quality will make up a good hash function in this construction.
Read the blog post for more details.
ASIC version
SeaHash is specifically designed such that it can be efficiently implemented in the form of ASIC while only using very few transistors.
Specification
See the reference module.
Credits
Aside for myself (@ticki), there are couple of other people who have helped creating this. Joshua Landau suggested using the PCG family of diffusions, created by Melissa E. O'Neill. Sokolov Yura spotted multiple bugs in SeaHash.