11 releases
| 0.4.2 | Apr 1, 2021 |
|---|---|
| 0.4.1 | Apr 1, 2021 |
| 0.4.0 | Aug 4, 2020 |
| 0.3.0 | May 28, 2020 |
| 0.1.4 | Jan 8, 2020 |
#903 in Algorithms
1,082 downloads per month
Used in textspan
27KB
270 lines
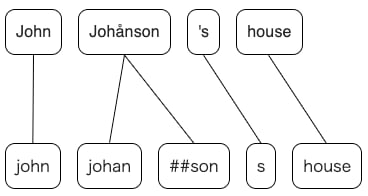
Robust and Fast tokenizations alignment library for Rust and Python
![]()
![]()
![]()
Demo: demo
Rust document: docs.rs
Blog post: How to calculate the alignment between BERT and spaCy tokens effectively and robustly
Usage (Python)
- Installation
$ pip install -U pip # update pip
$ pip install pytokenizations
- Install from source
This library uses maturin to build the wheel.
$ git clone https://github.com/tamuhey/tokenizations
$ cd tokenizations/python
$ pip install maturin
$ maturin build
Now the wheel is created in python/target/wheels directory, and you can install it with pip install *whl.
get_alignments
def get_alignments(a: Sequence[str], b: Sequence[str]) -> Tuple[List[List[int]], List[List[int]]]: ...
Returns alignment mappings for two different tokenizations:
>>> tokens_a = ["å", "BC"]
>>> tokens_b = ["abc"] # the accent is dropped (å -> a) and the letters are lowercased(BC -> bc)
>>> a2b, b2a = tokenizations.get_alignments(tokens_a, tokens_b)
>>> print(a2b)
[[0], [0]]
>>> print(b2a)
[[0, 1]]
a2b[i] is a list representing the alignment from tokens_a to tokens_b.
Usage (Rust)
See here: docs.rs
Related
- Algorithm overview
- Blog post
- seqdiff is used for the diff process.
- textspan
- explosion/spacy-alignments: 💫 A spaCy package for Yohei Tamura's Rust tokenizations library
- Python bindings for this library, maintained by Explosion, author of spaCy. If you feel difficult to install pytokenizations, please try this.
Dependencies
~1MB
~35K SLoC