52 releases (11 breaking)
Uses new Rust 2024
| 0.12.21 | Mar 27, 2025 |
|---|---|
| 0.12.17 | Feb 15, 2025 |
| 0.12.3 | Dec 21, 2024 |
| 0.11.0 | Nov 28, 2024 |
| 0.1.12 | Mar 25, 2024 |
#21 in Database implementations
170 downloads per month
6.5MB
20K
SLoC
![]()
![]()
![]()
![]()
![]()
Website | Benchmark | Demo | Library Docs | Server Docs | Server Readme | Roadmap | Blog | Twitter
SeekStorm is an open-source, sub-millisecond full-text search library & multi-tenancy server implemented in Rust.
Development started in 2015, in production since 2020, Rust port in 2023, open sourced in 2024, work in progress.
SeekStorm is open source licensed under the Apache License 2.0
Blog Posts: SeekStorm is now Open Source and SeekStorm gets Faceted search, Geo proximity search, Result sorting
SeekStorm high-performance search library
- Full-text lexical search
- True real-time search, with negligible performance impact
- Incremental indexing
- Multithreaded indexing & search
- Unlimited field number, field length & index size
- Compressed document store: ZStandard
- Boolean queries: AND, OR, PHRASE, NOT
- BM25F and BM25F_Proximity ranking
- Field filtering
- Faceted search: Counting & filtering of String & Numeric range facets (with Histogram/Bucket & Min/Max aggregation)
- Result sorting by any field, ascending or descending, multiple fields combined by "tie-breaking".
- Geo proximity search, filtering and sorting.
- Tokenizer with Chinese word segmentation
- Stemming for 18 languages
- KWIC snippets, highlighting
- One-way and multi-way synonyms
- Billion-scale index
- Language independent
- API keys
- RESTful API with CORS
- Index either in RAM or memory mapped files
- Cross-platform (Windows, Linux, MacOS)
- SIMD (Single Instruction, Multiple Data) hardware acceleration support,
both for x86-64 (AMD64 and Intel 64) and AArch64 (ARM, Apple Silicon). - Single-machine scalability: serving thousands of concurrent queries with low latency from a single commodity server without needing clusters or proprietary hardware accelerators.
Query types
- OR disjunction union
- AND conjunction intersection
- "" phrase
- - NOT
Result types
- TopK
- Count
- TopKCount
SeekStorm multi-tenancy search server
- Index and search via RESTful API.
- Ingest local data files in JSON, Newline-delimited JSON (ndjson), and Concatenated JSON formats via console command.
- Ingest local PDF files via console command (single file or all files in a directory).
- Multi-tenancy index management.
- API-key management.
- Embedded web server and web UI to search and display results from any index without coding.
- Code first OpenAPI generated REST API documentation
- Cross-platform: runs on Linux, Windows, and macOS (other OS untested).
- Docker file and container image at Docker Hub
Why SeekStorm?
Performance
Lower latency, higher throughput, lower cost & energy consumption, esp. for multi-field and concurrent queries.
Low tail latencies ensure a smooth user experience and prevent loss of customers and revenue.
While some rely on proprietary hardware accelerators (FPGA/ASIC) or clusters to improve performance,
SeekStorm achieves a similar boost algorithmically on a single commodity server.
Consistency
No unpredictable query latency during and after large-volume indexing as SeekStorm doesn't require resource-intensive segment merges.
Stable latencies - no cold start costs due to just-in-time compilation, no unpredictable garbage collection delays.
Scaling
Maintains low latency, high throughput, and low RAM consumption even for billion-scale indices.
Unlimited field number, field length & index size.
Relevance
Term proximity ranking provides more relevant results compared to BM25.
Real-time
True real-time search, as opposed to NRT: every indexed document is immediately searchable, even before and during commit.
Benchmarks

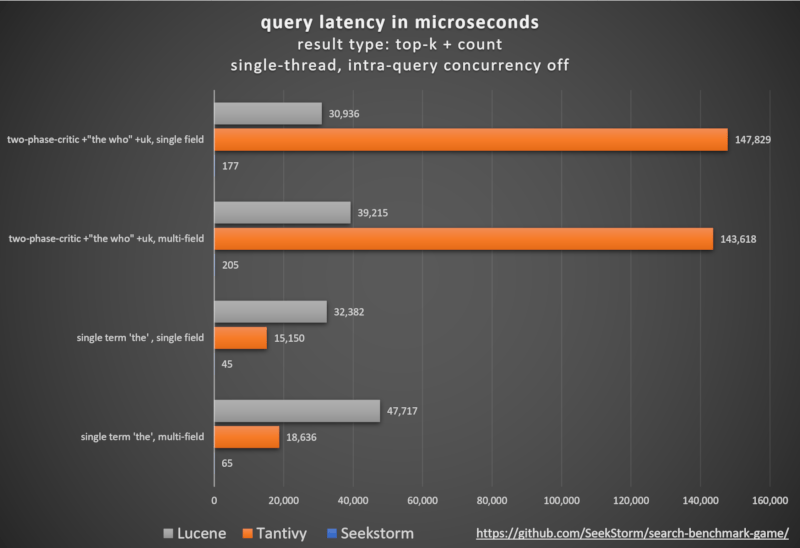

the who: vanilla BM25 ranking vs. SeekStorm proximity ranking
Methodology
Comparing different open-source search engine libraries (BM25 lexical search) using the open-source search_benchmark_game developed by Tantivy and Jason Wolfe.
Benefits
- using a proven open-source benchmark used by other search libraries for comparability
- adapters written mostly by search library authors themselves for maximum authenticity and faithfulness
- results can be replicated by everybody on their own infrastructure
- detailed results per query, per query type and per result type to investigate optimization potential
Detailed benchmark results https://seekstorm.github.io/search-benchmark-game/
Benchmark code repository https://github.com/SeekStorm/search-benchmark-game/
See our blog posts for more detailed information: SeekStorm is now Open Source and SeekStorm gets Faceted search, Geo proximity search, Result sorting
Why latency matters
- Search speed might be good enough for a single search. Below 10 ms people can't tell latency anymore. Search latency might be small compared to internet network latency.
- But search engine performance still matters when used in a server or service for many concurrent users and requests for maximum scaling, throughput, low processor load, and cost.
- With performant search technology, you can serve many concurrent users at low latency with fewer servers, less cost, less energy consumption, and a lower carbon footprint.
- It also ensures low latency even for complex and challenging queries: instant search, fuzzy search, faceted search, and union/intersection/phrase of very frequent terms.
- Local search performance matters, e.g. when many local queries are spawned for reranking, fallback/refinement queries, fuzzy search, data mining or RAG befor the response is transferred back over the network.
- Besides average latencies, we also need to reduce tail latencies, which are often overlooked but can cause loss of customers, revenue, and a bad user experience.
- It is always advisable to engineer your search infrastructure with enough performance headroom to keep those tail latencies in check, even during periods of high concurrent load.
- Also, even if a human user might not notice the latency, it still might make a big difference in autonomous stock markets, defense applications or RAG which requires multiple queries.
Keyword search remains a core building block in the advent of vector search and LLMs
Despite what the hype-cycles https://www.bitecode.dev/p/hype-cycles want you to believe, keyword search is not dead, as NoSQL wasn't the death of SQL.
You should maintain a toolbox, and choose the best tool for your task at hand. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
Keyword search is just a filter for a set of documents, returning those where certain keywords occur in, usually combined with a ranking metric like BM25. A very basic and core functionality is very challenging to implement at scale with low latency. Because the functionality is so basic, there is an unlimited number of application fields. It is a component, to be used together with other components. There are use cases which can be solved better today with vector search and LLMs, but for many more keyword search is still the best solution. Keyword search is exact, lossless, and it is very fast, with better scaling, better latency, lower cost and energy consumption. Vector search works with semantic similarity, returning results within a given proximity and probability.
Keyword search (lexical search)
If you search for exact results like proper names, numbers, license plates, domain names, and phrases (e.g. plagiarism detection) then keyword search is your friend. Vector search, on the other hand, will bury the exact result that you are looking for among a myriad of results that are only somehow semantically related. At the same time, if you don’t know the exact terms, or you are interested in a broader topic, meaning or synonym, no matter what exact terms are used, then keyword search will fail you.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.
Vector search
Vector search is perfect if you don’t know the exact query terms, or you are interested in a broader topic, meaning or synonym, no matter what exact query terms are used. But if you are looking for exact terms, e.g. proper names, numbers, license plates, domain names, and phrases (e.g. plagiarism detection) then you should always use keyword search. Vector search will instead bury the exact result that you are looking for among a myriad of results that are only somehow related. It has a good recall, but low precision, and higher latency. It is prone to false positives, e.g., in plagiarism detection as exact words and word order get lost.
Vector search enables you to search not only for similar text, but for everything that can be transformed into a vector: text, images (face recognition, fingerprints), audio, enabling you to do magic things like "queen - woman + man = king."
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generation
Vector search is not a replacement for keyword search, but a complementary addition - best to be used within a hybrid solution where the strengths of both approaches are combined. Keyword search is not outdated, but time-proven.
Why Rust
We have (partially) ported the SeekStorm codebase from C# to Rust
- Factor 2..4x performance gain vs. C# (latency and throughput)
- No slow first run (no cold start costs due to just-in-time compilation)
- Stable latencies (no garbage collection delays)
- Less memory consumption (no ramping up until the next garbage collection)
- No framework dependencies (CLR or JVM virtual machines)
- Ahead-of-time instead of just-in-time compilation
- Memory safe language https://www.whitehouse.gov/oncd/briefing-room/2024/02/26/press-release-technical-report/
Rust is great for performance-critical applications 🚀 that deal with big data and/or many concurrent users. Fast algorithms will shine even more with a performance-conscious programming language 🙂
Architecture
see ARCHITECTURE.md
Building
cargo build --release
⚠ WARNING: make sure to set the MASTER_KEY_SECRET environment variable to a secret, otherwise your generated API keys will be compromised.
Documentation
Build documentation
cargo doc --no-deps
Access documentation locally
SeekStorm\target\doc\seekstorm\index.html
SeekStorm\target\doc\seekstorm_server\index.html
Feature Flags
zh(default): Enables TokenizerType.UnicodeAlphanumericZH that implements Chinese word segmentation to segment continuous Chinese text into tokens for indexing and search.pdf(default): Enables PDF ingestion viapdfiumcrate.
You can disable the SeekStorm default features by using default-features = false in the cargo.toml of your application.
This can be useful to reduce the size of your application or if there are dependency version conflicts.
[dependencies]
seekstorm = { version = "0.12.19", default-features = false }
Usage of the library
Add required crates to your project
cargo add seekstorm
cargo add tokio
cargo add serde_json
use std::{collections::HashSet, error::Error, path::Path, sync::Arc};
use seekstorm::{index::*,search::*,highlighter::*,commit::Commit};
use tokio::sync::RwLock;
use an asynchronous Rust runtime
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
create schema (from JSON)
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"#;
let schema=serde_json::from_str(schema_json).unwrap();
create schema (from SchemaField)
let schema= vec![
SchemaField::new("title".to_owned(), false, false, FieldType::Text, false, 1.0),
SchemaField::new("body".to_owned(),true,true,FieldType::Text,false,1.0),
SchemaField::new("url".to_owned(), false, false, FieldType::Text,false,1.0),
];
create index
let index_path=Path::new("C:/index/");
let meta = IndexMetaObject {
id: 0,
name: "test_index".to_string(),
similarity:SimilarityType::Bm25f,
tokenizer:TokenizerType::AsciiAlphabetic,
stemmer: StemmerType::None,
access_type: AccessType::Mmap,
};
let serialize_schema=true;
let segment_number_bits1=11;
let index=create_index(index_path,meta,&schema,serialize_schema,&Vec::new(),segment_number_bits1,false).unwrap();
let _index_arc = Arc::new(RwLock::new(index));
open index (alternatively to create index)
let index_path=Path::new("C:/index/");
let mut index_arc=open_index(index_path,false).await.unwrap();
index documents (from JSON)
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"#;
let documents_vec=serde_json::from_str(documents_json).unwrap();
index_arc.index_documents(documents_vec).await;
index document (from Document)
let document= Document::from([
("title".to_string(), Value::String("title4 test".to_string())),
("body".to_string(), Value::String("body4 test".to_string())),
("url".to_string(), Value::String("url4".to_string())),
]);
idx.0.index_document(document,FileType::None).await;
commit documents
index_arc.commit().await;
search index
let query="test".to_string();
let offset=0;
let length=10;
let query_type=QueryType::Intersection;
let result_type=ResultType::TopkCount;
let include_uncommitted=false;
let field_filter=Vec::new();
let result_object = index_arc.search(query, query_type, offset, length, result_type,include_uncommitted,field_filter).await;
display results
let highlights:Vec<Highlight>= vec![
Highlight {
field: "body".to_string(),
name:String::new(),
fragment_number: 2,
fragment_size: 160,
highlight_markup: true,
},
];
let highlighter=Some(highlighter(&index_arc,highlights, result_object.query_term_strings));
let return_fields_filter= HashSet::new();
let mut index=index_arc.write().await;
for result in result_object.results.iter() {
let doc=index.get_document(result.doc_id,false,&highlighter,&return_fields_filter).unwrap();
println!("result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get("body"));
}
println!("result counts {} {} {}",result_object.results.len(), result_object.result_count, result_object.result_count_total);
multi-threaded search
let query_vec=vec!["house".to_string(),"car".to_string(),"bird".to_string(),"sky".to_string()];
let offset=0;
let length=10;
let query_type=QueryType::Union;
let result_type=ResultType::TopkCount;
let thread_number = 4;
let permits = Arc::new(Semaphore::new(thread_number));
for query in query_vec {
let permit_thread = permits.clone().acquire_owned().await.unwrap();
let query_clone = query.clone();
let index_arc_clone = index_arc.clone();
let query_type_clone = query_type.clone();
let result_type_clone = result_type.clone();
let offset_clone = offset;
let length_clone = length;
tokio::spawn(async move {
let rlo = index_arc_clone
.search(
query_clone,
query_type_clone,
offset_clone,
length_clone,
result_type_clone,
false,
Vec::new(),
)
.await;
println!("result count {}", rlo.result_count);
drop(permit_thread);
});
}
index JSON file in JSON, Newline-delimited JSON and Concatenated JSON format
let file_path=Path::new("wiki_articles.json");
let _ =index_arc.ingest_json(file_path).await;
index all PDF files in directory and sub-directories
- converts pdf to text and indexes it
- extracts title from metatag, or first line of text, or from filename
- extracts creation date from metatag, or from file creation date (Unix timestamp: the number of seconds since 1 January 1970)
- copies all ingested PDF files to the "files" subdirectory in the index.
- the following index schema is required (and automatically created by the console
ingestcommand):
[
{
"field": "title",
"stored": true,
"indexed": true,
"field_type": "Text",
"boost": 10
},
{
"field": "body",
"stored": true,
"indexed": true,
"field_type": "Text"
},
{
"field": "url",
"stored": true,
"indexed": false,
"field_type": "Text"
},
{
"field": "date",
"stored": true,
"indexed": false,
"field_type": "Timestamp",
"facet": true
}
]
let file_path=Path::new("C:/Users/johndoe/Downloads");
let _ =index_arc.ingest_pdf(file_path).await;
index PDF file
let file_path=Path::new("C:/test.pdf");
let file_date=Utc::now().timestamp();
let _ =index_arc.index_pdf_file(file_path).await;
index PDF file bytes
let file_date=Utc::now().timestamp();
let document = fs::read(file_path).unwrap();
let _ =index_arc.index_pdf_bytes(file_path, file_date, &document).await;
get PDF file bytes
let doc_id=0;
let file=index.get_file(doc_id).unwrap();
clear index
index.clear_index();
delete index
index.delete_index();
close index
index.close_index();
seekstorm library version string
let version=version();
println!("version {}",version);
Faceted search - Quick start
Facets are defined in 3 different places:
- The facet fields are defined in the schema at create_index.
- The facet field values are set in index_document at index time.
- The query_facets/facet_filter parameters are specified at query time.
Facets are then returned in the search result object.
A minimal working example of faceted indexing & search requires just 60 lines of code. But to puzzle it all together from the documentation alone might be tedious. This is why we provide a quick start example here:
Add required crates to your project
cargo add seekstorm
cargo add tokio
cargo add serde_json
Add use declarations
use std::{collections::HashSet, error::Error, path::Path, sync::Arc};
use seekstorm::{index::*,search::*,highlighter::*,commit::Commit};
use tokio::sync::RwLock;
use an asynchronous Rust runtime
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
create index
let index_path=Path::new("C:/index/");//x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"#;
let schema=serde_json::from_str(schema_json).unwrap();
let meta = IndexMetaObject {
id: 0,
name: "test_index".to_string(),
similarity:SimilarityType::Bm25f,
tokenizer:TokenizerType::AsciiAlphabetic,
stemmer: StemmerType::None,
access_type: AccessType::Mmap,
};
let serialize_schema=true;
let segment_number_bits1=11;
let index=create_index(index_path,meta,&schema,serialize_schema,&Vec::new(),segment_number_bits1,false).unwrap();
let mut index_arc = Arc::new(RwLock::new(index));
index documents
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"#;
let documents_vec=serde_json::from_str(documents_json).unwrap();
index_arc.index_documents(documents_vec).await;
commit documents
index_arc.commit().await;
search index
let query="test".to_string();
let offset=0;
let length=10;
let query_type=QueryType::Intersection;
let result_type=ResultType::TopkCount;
let include_uncommitted=false;
let field_filter=Vec::new();
let query_facets = vec![QueryFacet::String {field: "age".to_string(),prefix: "".to_string(),length:u16::MAX}];
let facet_filter=Vec::new();
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort=Vec::new();
let result_object = index_arc.search(query, query_type, offset, length, result_type,include_uncommitted,field_filter,query_facets,facet_filter).await;
display results
let highlights:Vec<Highlight>= vec![
Highlight {
field: "body".to_owned(),
name:String::new(),
fragment_number: 2,
fragment_size: 160,
highlight_markup: true,
},
];
let highlighter2=Some(highlighter(&index_arc,highlights, result_object.query_terms));
let return_fields_filter= HashSet::new();
let index=index_arc.write().await;
for result in result_object.results.iter() {
let doc=index.get_document(result.doc_id,false,&highlighter2,&return_fields_filter).unwrap();
println!("result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get("body"));
}
println!("result counts {} {} {}",result_object.results.len(), result_object.result_count, result_object.result_count_total);
display facets
println!("{}", serde_json::to_string_pretty(&result_object.facets).unwrap());
end of main function
Ok(())
}
Demo time
Build a Wikipedia search engine with the SeekStorm server
A quick step-by-step tutorial on how to build a Wikipedia search engine from a Wikipedia corpus using the SeekStorm server in 5 easy steps.

Download SeekStorm
Download SeekStorm from the GitHub repository
Unzip in a directory of your choice, open in Visual Studio code.
or alternatively
git clone https://github.com/SeekStorm/SeekStorm.git
Build SeekStorm
Install Rust (if not yet present): https://www.rust-lang.org/tools/install
In the terminal of Visual Studio Code type:
cargo build --release
Get Wikipedia corpus
Preprocessed English Wikipedia corpus (5,032,105 documents, 8,28 GB decompressed). Although wiki-articles.json has a .JSON extension, it is not a valid JSON file. It is a text file, where every line contains a JSON object with url, title and body attributes. The format is called ndjson ("Newline delimited JSON").
Decompresss Wikipedia corpus.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Move the decompressed wiki-articles.json to the release directory
Start SeekStorm server
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexing
Type 'ingest' into the command line of the running SeekStorm server:
ingest
This creates the demo index and indexes the local wikipedia file.
Start searching within the embedded WebUI
Open embedded Web UI in browser: http://127.0.0.1
Enter a query into the search box
Testing the REST API endpoints
Open src/seekstorm_server/test_api.rest in VSC together with the VSC extension "Rest client" to execute API calls and inspect responses
interactive API endpoint examples
Set the 'individual API key' in test_api.rest to the api key displayed in the server console when you typed 'index' above.
Remove demo index
Type 'delete' into the command line of the running SeekStorm server:
delete
Shutdown server
Type 'quit' into the commandline of the running SeekStorm server.
quit
Customizing
Do you want to use something similar for your own project? Have a look at the ingest and web UI documentation.
Build a PDF search engine with the SeekStorm server
A quick step-by-step tutorial on how to build a PDF search engine from a directory that contains PDF files using the SeekStorm server.
Make all your scientific papers, ebooks, resumes, reports, contracts, documentation, manuals, letters, bank statements, invoices, delivery notes searchable - at home or in your organisation.

Build SeekStorm
Install Rust (if not yet present): https://www.rust-lang.org/tools/install
In the terminal of Visual Studio Code type:
cargo build --release
Download PDFium
Download and copy the Pdfium library into the same folder as the seekstorm_server.exe: https://github.com/bblanchon/pdfium-binaries
Start SeekStorm server
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexing
Choose a directory that contains PDF files you want to index and search, e.g. your documents or download directory.
Type 'ingest' into the command line of the running SeekStorm server:
ingest C:\Users\JohnDoe\Downloads
This creates the pdf_index and indexes all PDF files from the specified directory, including subdirectories.
Start searching within the embedded WebUI
Open embedded Web UI in browser: http://127.0.0.1
Enter a query into the search box
Remove demo index
Type 'delete' into the command line of the running SeekStorm server:
delete
Shutdown server
Type 'quit' into the commandline of the running SeekStorm server.
quit
Online Demo: DeepHN Hacker News search
Full-text search 30M Hacker News posts AND linked web pages

The DeepHN demo is still based on the SeekStorm C# codebase.
We are currently porting all required missing features.
See roadmap below.
Roadmap
The Rust port is not yet feature complete. The following features are currently ported or added.
Porting
- ✅ Delete document
- ✅ Faceted search
- ✅ Sorting of results by any field
- ✅ Unicode character folding/normalization tokenizer (diacritics, accents, umlauts, bold, italic, full-width ...)
- ✅ Tokenizer with Chinese word segmentation
- Autosuggestion, spelling correction, instant search
- Fuzzy search
- Intra-query concurrency
Improvements
- ✅ Better REST API documentation: integrated OpenAPI generator
- 👷 Faster indexing
- Relevancy benchmarks: BeIR, MS MARCO
New features
- ✅ Docker file and container image
- ✅ Stemming for 18 languages
- More tokenizer types (Japanese, Korean)
- Native vector search (currently PoC)
- Distributed search cluster (currently PoC)
- S3 object storage compatible index: cloud-native split of storage and compute
- WebAssembly (Wasm)
- Wrapper/bindings in JavaScript, Python, Java, C#, C, Go for the SeekStorm Rust library
Dependencies
~29–45MB
~769K SLoC