9 releases
| 0.1.8 | Nov 13, 2022 |
|---|---|
| 0.1.7 | Nov 5, 2022 |
| 0.1.1 | Oct 24, 2022 |
#1162 in HTTP server
44 downloads per month
500KB
11K
SLoC
☁ Puff ☁
Python with an async runtime built-in Rust for GraphQL, ASGI, WSGI, Postgres, PubSub, Redis, Distributed Tasks, and HTTP2 Client.
![]()
![]()
![]()
What is Puff?
Puff is a batteries included "deep stack" for Python. It's an experiment to minimize the barrier between Python and Rust to unlock the full potential of high level languages. Build your own Runtime using standard CPython and extend it with Rust. Imagine if GraphQL, Postgres, Redis and PubSu, Distributed Tasks were part of the standard library. That's Puff.
The old approach for integrating Rust in Python would be to make a Python package that uses rust and import it from Python. This approach has some flaws as the rust packages can't cooperate. Puff gives Rust its own layer, so you can build a cohesive set of tools in Rust that all work flawlessly together without having to re-enter Python.
High level overview is that Puff gives Python
- Greenlets on Rust's Tokio.
- High performance HTTP Server - combine Axum with Python WSGI apps (Flask, Django, etc.)
- Rust / Python natively in the same process, no sockets or serialization.
- AsyncIO / uvloop / ASGI integration with Rust
- An easy-to-use GraphQL service
- Multi-node pub-sub
- Rust level Redis Pool
- Rust level Postgres Pool
- Websockets
- HTTP Client
- Distributed, at-least-once, priority and scheduled task queue
- semi-compatible with Psycopg2 (hopefully good enough for most of Django)
- A safe convenient way to drop into rust for maximum performance
The idea is Rust and Python are near perfect complements to each other and building a framework to let them talk leads to greater efficiency in terms of productivity, scalability and performance.
| Python | Rust |
|---|---|
| ✅ High-Level | ✅ Low-Level |
| ✅ Lots of tools and packages | ✅ Lots of tools and packages |
| ✅ Easy to get started | ✅ Easy to get started |
| 🟡 Interpreted (productivity at the cost of speed) | 🟡 Compiled (speed at the cost of productivity) |
| ✅ Easy to get master | ❌ The learning curve gets steep quickly. |
| ✅ Fast iteration to prototype | ❌ Requires planning for correctness |
| ✅ Google a problem, copy paste, it works. | ❌ Less examples floating in the wild |
| ❌ Weak type system | ✅ Great Type System |
| ❌ GIL prevents threading | ✅ High Performance |
| ❌ Not-so safe | ✅ Safe |
The Zen of deepstack is recognizing that no language is the ultimate answer. Seek progress instead of perfection by using Python for rapid development and Rust to optimize the most critical paths once you find them later. Find the balance.
Quick Start
Install Rust to compile Puff for your platform.
Install Rust
Follow the instructions to install Cargo for your platform.
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Install Puff
Use cargo to install Puff.
cargo install puff-rs
Puff requires Python >= 3.10. Python's Poetry is optional.
Your Puff Project needs to find your Python project. Even if they are in the same folder, they need to be added to the PYTHONPATH.
One way to set up a Puff project is like this:
poetry new my_puff_proj_py
cd my_puff_proj_py
poetry add puff-py
Now from my_puff_proj_py you can run your project with poetry run puff to access cargo from poetry and expose the virtual environment to Puff.
The Python project doesn't need to be inside off your Rust package. It only needs to be on the PYTHONPATH or inside an virtualenv. If you don't want to use poetry, you will have to set up a virtual environment when running Puff.
Puff ♥ Python
Python programs in Puff are run by building a Program in Rust and registering the Python function there.
The Python method is bootstrapped and run as a greenlet in the Puff runtime.
Create a puff.toml
[[commands]]
function = "my_puff_proj_py.hello_world"
command_name = "hello_world"
Python:
import puff
# Standard python functions run on Puff greenlets. You can only use special Puff async functions without pausing other greenlets.
def hello_world():
fn = "my_file.zip"
result_bytes = puff.read_file_bytes(fn) # Puff async function that runs in Tokio.
result_py_bytes = do_some_blocking_work(fn) # Python blocking that spawns a thread to prevent pausing the greenlet thread.
print(f"Hello from python!! Zip is {len(result_bytes)} bytes long from rust and {len(result_py_bytes)} bytes from Python.")
# 100% of python packages are compatible by wrapping them in blocking decorator.
@puff.blocking
def do_some_blocking_work(fn):
with open(fn, "rb") as f:
return f.read()
Puff ♥ Django
While it can run any WSGI app, Puff has a special affection for Django. Puff believes that business logic should be implemented on a higher level layer and Rust should be used as an optimization. Django is a perfect high level framework to use with Puff as it handles migrations, admin, etc. Puff mimics the psycopg2 drivers and cache so that Django uses the Puff Database and Redis pool.
Transform your sync Django project into a highly concurrent Puff program with a few lines of code. Puff wraps the management commands so migrate, etc. all work as expected. Simply run poetry run run_cargo django [command] instead of using ./manage.py [command]. For example poetry run run_cargo django migrate. Don't use django's dev server, instead use Puff's with poetry run run_cargo serve.
Create a puff.toml
django = true
wsgi = "my_django_application.wsgi.application"
[[postgres]]
name = "default"
[[redis]]
name = "default"
Use Puff everywhere in your Django app. Even create Django management commands that use Rust!
See puff-py repo for a more complete Django example.
Puff ♥ Graphql
Puff exposes Graphql Mutations, Queries and Subscriptions based on Python Class definitions. A core "killer feature" of the Puff Graphql engine is that it works on a "layer base" instead of a Node base. This allows each step of Graphql to gather the complete data necessary to query all data it needs at once. This avoids the dreaded n+1 and dataloader overhead traditionally associated with GraphQL.
GrapqhQL python functions can pass off Pure SQL queries to Puff and puff will render and transform the query without needing to return to python. This allows the Python Graphql interface to be largely IO free, but still flexible to have access to Puff resources when needed.
from dataclasses import dataclass
from typing import Optional, Tuple, List, Any
from puff.pubsub import global_pubsub
pubsub = global_pubsub
CHANNEL = "my_puff_chat_channel"
@dataclass
class SomeInputObject:
some_count: int
some_string: str
@dataclass
class SomeObject:
field1: int
field2: str
@dataclass
class DbObject:
was_input: int
title: str
@classmethod
def child_sub_query(cls, context, /) -> Tuple[DbObject, str, List[Any], List[str], List[str]]:
# Extract column values from the previous layer to use in this one.
parent_values = [r[0] for r in context.parent_values(["field1"])]
sql_q = "SELECT a::int as was_input, $2 as title FROM unnest($1::int[]) a"
# returning a sql query along with 2 lists allow you to correlate and join the parent with the child.
return ..., sql_q, [parent_values, "from child"], ["field1"], ["was_input"]
@dataclass
class Query:
@classmethod
def hello_world(cls, parents, context, /, my_input: int) -> Tuple[List[DbObject], str, List[Any]]:
# Return a Raw query for Puff to execute in Postgres.
# The ellipsis is a placeholder allowing the Python type system to know which Field type it should transform into.
return ..., "SELECT $1::int as was_input, \'hi from pg\'::TEXT as title", [my_input]
@classmethod
def hello_world_object(cls, parents, context, /, my_input: List[SomeInputObject]) -> Tuple[List[SomeObject], List[SomeObject]]:
objs = [SomeObject(field1=0, field2="Python object")]
if my_input:
for inp in my_input:
objs.append(SomeObject(field1=inp.some_count, field2=inp.some_string))
# Return some normal Python objects.
return ..., objs
@classmethod
def new_connection_id(cls, context, /) -> str:
# Get a new connection identifier for pubsub.
return pubsub.new_connection_id()
@dataclass
class Mutation:
@classmethod
def send_message_to_channel(cls, context, /, connection_id: str, message: str) -> bool:
print(context.auth_token) # Authoritzation bearer token passed in the context
return pubsub.publish_as(connection_id, CHANNEL, message)
@dataclass
class MessageObject:
message_text: str
from_connection_id: str
num_processed: int
@dataclass
class Subscription:
@classmethod
def read_messages_from_channel(cls, context, /, connection_id: Optional[str] = None) -> Iterable[MessageObject]:
if connection_id is not None:
conn = pubsub.connection_with_id(connection_id)
else:
conn = pubsub.connection()
conn.subscribe(CHANNEL)
num_processed = 0
while msg := conn.receive():
from_connection_id = msg.from_connection_id
# Filter out messages from yourself.
if connection_id != from_connection_id:
yield MessageObject(message_text=msg.text, from_connection_id=from_connection_id, num_processed=num_processed)
num_processed += 1
@dataclass
class Schema:
query: Query
mutation: Mutation
subscription: Subscription
Rust:
django = true
pytest = true
[[postgres]]
enable = true
[[redis]]
enable = true
[[pubsub]]
enable = true
[[graphql]]
schema = "my_python_gql_app.Schema"
url = "/graphql/"
subscriptions_url = "/subscriptions/"
playground_url = "/playground/"
[[commands]]
function = "my_puff_proj_py.hello_world"
command_name = "hello_world"
Produces a Graphql Schema like so:
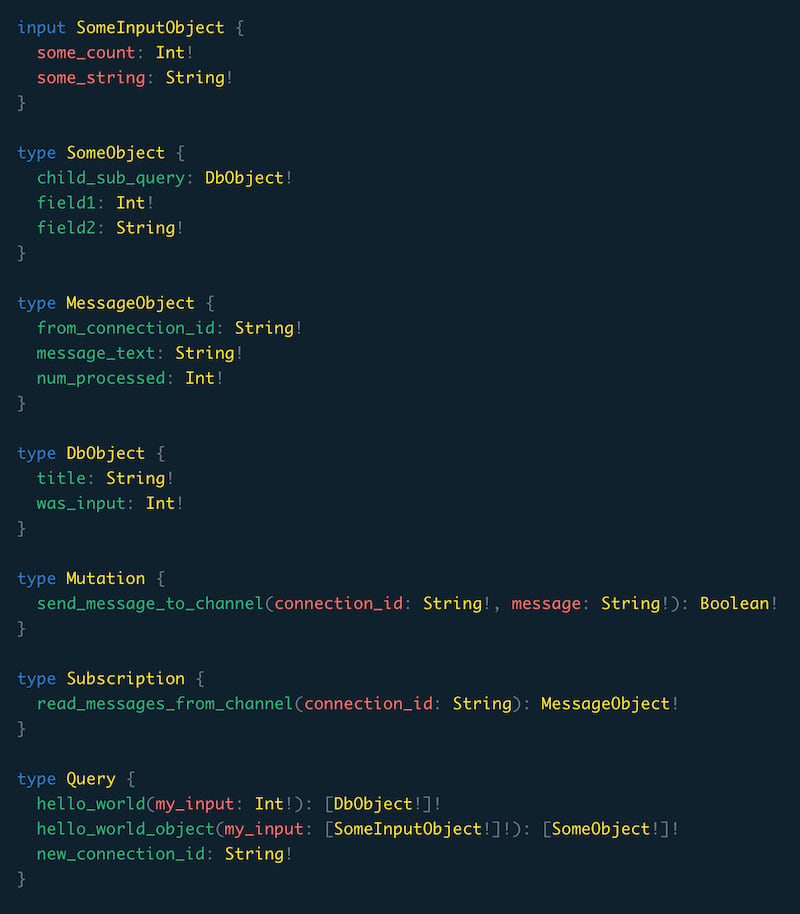
In addition to making it easier to write the fastest queries, a layer based design allows Puff to fully exploit the multithreaded async Rust runtime and solve branches independently. This gives you a performance advantages out of the box.
Puff ♥ Pytest
Integrate with pytest to easily test your Graphql and Puff apps. Simply add the PytestCommand to your Program and write tests as normal only run them with puff pytest
pytest = true
from hello_world_py_app import __version__
from puff.graphql import global_graphql
gql = global_graphql
def test_version():
assert __version__ == '0.1.0'
def test_gql():
QUERY = """
query {
hello_world(my_input: 3) {
title
was_input
}
}
"""
result = gql.query(QUERY, {})
assert 'data' in result
assert 'errors' not in result
assert result['data']["hello_world"][0]["title"] == "hi from pg"
assert result['data']["hello_world"][0]["was_input"] == 3
Puff ♥ AsyncIO
Puff has built in integrations for ASGI and asyncio. You first need to configure the RuntimeConfig to use it. Puff will automatically use uvloop if installed when starting the event loop.
asgiref.sync.async_to_sync and asgiref.sync.sync_to_async have both been patched so that you can call puff greenlets from async or async from puff greenlets easily.
from fastapi import FastAPI
from puff import global_state, wrap_async
state = global_state
app = FastAPI()
@app.get("/fast-api")
async def read_root():
result = await wrap_async(lambda r: state.hello_from_rust_async(r, "hello from asyncio"))
return {"Hello": "World", "from": "Fast API", "rust_value": result}
puff.toml
asyncio = true
asgi = "my_python_app.app"
Puff ♥ Django + Graphql
Puff GraphQL integrates seamlessly with Django. Convert Django querysets to SQL to offload all computation to Rust. Or decorate with borrow_db_context and let Django have access to the GraphQL connection, allowing you fallback to the robustness of django for complicated lookups.
from dataclasses import dataclass
from puff import graphql
from polls.models import Question, Choice
from django.utils import timezone
from puff.contrib.django import query_and_params
@dataclass
class ChoiceObject:
id: int
question_id: int
choice_text: str
votes: int
@dataclass
class QuestionObject:
id: int
pub_date: str
question_text: str
@classmethod
def choices(cls, context, /) -> Tuple[List[ChoiceObject], str, List[Any], List[str], List[str]]:
# Extract column values from the previous layer to use in this one.
parent_values = [r[0] for r in context.parent_values(["id"])]
# Convert a Django queryset to sql and params to pass off to Puff. This function does 0 IO in Python.
qs = Choice.objects.filter(question_id__in=parent_values)
sql_q, params = query_and_params(qs)
return ..., sql_q, params, ["id"], ["question_id"]
@dataclass
class Query:
@classmethod
def questions(cls, context, /) -> Tuple[List[QuestionObject], str, List[Any]]:
# Convert a Django queryset to sql and params to pass off to Puff. This function does 0 IO in Python.
qs = Question.objects.all()
sql_q, params = query_and_params(qs)
return ..., sql_q, params
@classmethod
@graphql.borrow_db_context # Decorate with borrow_db_context to use same DB connection in Django as the rest of GQL
def question_objs(cls, context, /) -> Tuple[List[QuestionObject], List[Any]]:
# You can also compute the python values with Django and hand them off to Puff.
# This version of the same `questions` field, is slower since Django is constructing the objects.
objs = list(Question.objects.all())
return ..., objs
@dataclass
class Mutation:
@classmethod
@graphql.borrow_db_context # Decorate with borrow_db_context to use same DB connection in Django as the rest of GQL
def create_question(cls, context, /, question_text: str) -> QuestionObject:
question = Question.objects.create(question_text=question_text, pub_date=timezone.now())
return question
@dataclass
class Subscription:
pass
@dataclass
class Schema:
query: Query
mutation: Mutation
subscription: Subscription
Puff ♥ Distributed Tasks
Sometimes you need to execute a function in the future, or you need to execute it, but you don't care about the result right now. For example, you might have a webhook or an email to send.
Puff provides a distributed queue abstraction as part of the standard library. It is powered by Redis and has the ability to distribute tasks across nodes with priorities, delays and retries. Jobs submitted to the queue can be persisted (additionally so if Redis is configured to persist to disk), so you can shut down and restart your server without worrying about losing your queued functions.
The distributed queue runs in the background of every Puff instance. In order to have a worker instance, use the WaitForever command. Your HTTP server can also handle distributing, processing and running background tasks which is handy for small projects and scales out well by using wait_forever to add more processing power if needed.
A task is a python function that takes a JSONable payload that you care executes, but you don't care exactly when or where. JSONable types are simple Python structures (dicts, lists, strings, etc) that can be serialized to JSON. Queues will monitor tasks and retry them if they don't get a result in timeout_ms. Beware that you might have the same task running multiple times if you don't configure timeouts correctly, so if you are sending HTTP requests or other task that might take a while to respond configure timeouts correctly. Tasks should return a JSONable result which will be kept for keep_results_for_ms seconds.
Only pass in top-level functions into schedule_function that can be imported (no lambda's or closures). This function should be accessible on all Puff instances.
Implement priorities by utilizing scheduled_time_unix_ms. The worker sorts all tasks by this value and executes the first one up until the current time. So if you schedule scheduled_time_unix_ms=1, that function will be the next to execute on the first availability. Use scheduled_time_unix_ms=1, scheduled_time_unix_ms=2. scheduled_time_unix_ms=3, etc for different task types that are high priority. Be careful that you don't starve the other tasks if you aren't processing these high priority tasks fast enough. By default, Puff schedules new tasks with the current unix time to be "fair" and provide a sense of "FIFO" order. You can also set this value to a unix timestamp in the future to delay execution of a task.
You can have as many tasks running as you want (use set_task_queue_concurrent_tasks), however there is a small overhead in terms of monitoring and finding new tasks by increasing this value. The default is num_cpu x 4
See additional design patterns in Building RPC with Puff.
from puff.task_queue import global_task_queue
task_queue = global_task_queue
def run_main():
all_tasks = []
for x in range(100):
# Schedule some tasks on any coroutine thread of any Puff instance connected through Redis.
task1 = task_queue.schedule_function(my_awesome_task, {"type": "coroutine", "x": [x]}, timeout_ms=100, keep_results_for_ms=5 * 1000)
# Override `scheduled_time_unix_ms` so that async tasks execute with priority over the coroutine tasks.
# Notice that since all of these tasks have the same priority, they may be executed out of the order they were scheduled.
task2 = task_queue.schedule_function(my_awesome_task_async, {"type": "async", "x": [x]}, scheduled_time_unix_ms=1)
# These tasks will keep their order since their priorities as defined by `scheduled_time_unix_ms` match the order scheduled.
task3 = task_queue.schedule_function(my_awesome_task_async, {"type": "async-ordered", "x": [x]}, scheduled_time_unix_ms=x)
print(f"Put tasks {task1}, {task2}, {task3} in queue")
all_tasks.append(task1)
all_tasks.append(task2)
all_tasks.append(task3)
for task in all_tasks:
result = task_queue.wait_for_task_result(task, 100, 1000)
print(f"{task} returned {result}")
def my_awesome_task(payload):
print(f"In task {payload}")
return payload["x"][0]
async def my_awesome_task_async(payload):
print(f"In async task {payload}")
return payload["x"][0]
puff.toml
asyncio = true
[[task_queue]]
enable = true
Puff ♥ HTTP
Puff has a built-in asynchronous HTTP client based on reqwests that can handle HTTP2 (also served by the Puff WSGI/ASGI integrations) and reuse connections. It uses rust to encode and decode JSON ultra-fast.
from puff.http import global_http_client
http_client = global_http_client
async def do_http_request():
this_response = await http_client.post("http://localhost:7777/", json={"my_data": ["some", "json_data"]})
return await this_response.json()
def do_http_request_greenlet():
"""greenlets can use the same async functions. Puff will automatically handle awaiting and context switching."""
this_response = http_client.post("http://localhost:7777/", json={"my_data": ["some", "json_data"]})
return this_response.json()
You can set the HTTP client options through RuntimeConfig. If your program is only talking to other Puff instances or HTTP2 services, it can make sense to turn on HTTP2 only. You can also configure user-agents as well as many other HTTP options through this method.
asyncio = true
[[http_client]]
http2_prior_knowledge = true
Connect to Everything...
Puff supports multiple pools to services.
[[postgres]]
name = "default"
[[postgres]]
name = "readonly"
[[postgres]]
name = "audit"
[[redis]]
name = "default"
[[redis]]
name = "other"
[[http_client]]
name = "default"
[[http_client]]
name = "internal"
http2_prior_knowledge = true
[[pubsub]]
name = "default"
[[pubsub]]
name = "otherpubsub"
[[graphql]]
schema = "my_python_gql_app.Schema"
url = "/graphql/"
subscriptions_url = "/subscriptions/"
playground_url = "/playground/"
database = "readonly"
[[graphql]]
name = "audit"
schema = "my_python_gql_app.AuditSchema"
url = "/audit/graphql/"
subscriptions_url = "/audit/subscriptions/"
playground_url = "/audit/playground/"
database = "audit"
Produces a Program with the following options:
Options:
--default-postgres-url <DEFAULT_POSTGRES_URL>
Postgres pool configuration for 'default'. [env: PUFF_DEFAULT_POSTGRES_URL=] [default: postgres://postgres:password@localhost:5432/postgres]
--audit-postgres-url <AUDIT_POSTGRES_URL>
Postgres pool configuration for 'audit'. [env: PUFF_AUDIT_POSTGRES_URL=] [default: postgres://postgres:password@localhost:5432/postgres]
--readonly-postgres-url <READONLY_POSTGRES_URL>
Postgres pool configuration for 'readonly'. [env: PUFF_READONLY_POSTGRES_URL=] [default: postgres://postgres:password@localhost:5432/postgres]
--default-redis-url <DEFAULT_REDIS_URL>
Redis pool configuration for 'default'. [env: PUFF_DEFAULT_REDIS_URL=] [default: redis://localhost:6379]
--other-redis-url <OTHER_REDIS_URL>
Redis pool configuration for 'other'. [env: PUFF_OTHER_REDIS_URL=] [default: redis://localhost:6379]
--default-pubsub-url <DEFAULT_PUBSUB_URL>
PubSub configuration for 'default'. [env: PUFF_DEFAULT_PUBSUB_URL=] [default: redis://localhost:6379]
--otherpubsub-pubsub-url <OTHERPUBSUB_PUBSUB_URL>
PubSub configuration for 'otherpubsub'. [env: PUFF_OTHERPUBSUB_PUBSUB_URL=] [default: redis://localhost:6379]
Deepstack
Puff is designed so that you can build your own version using Puff as a library. This allows an incredible depth of performance optimization if necessary for your project.
Architecture
Puff consists of multithreaded Tokio Runtime and a single thread which runs all Python computations on Greenlets. Python offloads the IO to Tokio which schedules it and returns it if necessary.

Status
This is extremely early in development. The scope of the project is ambitious. Expect things to break.
Probably the end game of puff is to have something like gevent's monkeypatch to automatically make existing projects compatible.
Dependencies
~28–43MB
~763K SLoC