1 unstable release
| 0.7.0-alpha.1 | Dec 22, 2024 |
|---|---|
| 0.6.2-alpha.0 |
|
#674 in Asynchronous
1MB
16K
SLoC
Orengine: The Fastest and Most Memory-Efficient Async Engine in Rust
Orengine is a blazing fast, memory-efficient, and highly flexible asynchronous engine built for the modern age of Rust development. Whether you're building applications with a shared-nothing architecture or a shared-all architecture, Orengine provides you with the tools to reach maximum performance.
Stage
In development. This library is not ready for production use and its API can be changed.
Wait for v1.0.0 and media posts.
Before release
- add more docs;
- add fallback to
asyncifyfor non-Linux OS; - think about fixed buffers and files.
Why Orengine?
-
Speed: Orengine is designed from the ground up to be the fastest async engine available in the Rust ecosystem.
-
Memory Efficiency: Optimized for low-latency and high-throughput workloads, Orengine ensures minimal memory overhead, allowing your application to scale very well.
-
Flexible Architecture: Whether you need to go fully distributed with a shared-nothing architecture or centralize resources with a shared-all approach, Orengine adapts to your requirements.
-
Scalability: Orengine was created to handle millions of asynchronous tasks. As long as you have enough memory, you will not see performance degradation regardless of the number of tasks, and you will have enough of memory for many tasks, because Orengine uses it very efficiently.
-
Modern: Orengine is developed in 2024 and uses the most advanced technologies such as
io-uring. -
No Compromises on Performance: Highly tuned internal code-based optimizations that prioritize performance over unnecessary complexity.
Task execution: local vs shared
Orengine offers two modes of execution of tasks and Futures: local and shared, each suited to different
architectural needs and performance optimizations.
Local Tasks
-
Local tasks and
Futuresare executed strictly within the current thread. They cannot be moved between threads. This allows the use of Shared-Nothing Architecture, where each task is isolated and works with local resources, ensuring that no data needs to be shared between threads. -
With local tasks, you can leverage
Localand local synchronization primitives, which offer significant performance improvements due to reduced overhead from cross-thread synchronization.
Shared Tasks
-
Don't rewrite the 'usual' architecture: where you use Tokio, you can use shared tasks to achieve the same result, but with better performance.
-
Shared tasks and
Futurescan be moved freely between threads, allowing more dynamic distribution of workload across the system.
Work-Sharing: Efficient Shared Tasks Distribution
Orengine also provides a built-in work-sharing mechanism to balance the load across executors dynamically.
When the number of shared tasks in an executor exceeds a configurable threshold-defined
by runtime::Config.work_sharing_level — the executor will share half of its shared tasks
with other available executors.
Conversely, when an executor has no tasks left to run, it will attempt to take shared tasks from other executors
that have excess work, ensuring optimal utilization of all available resources.
This system ensures that no executor is idle while others are overloaded, leading to improved efficiency and balanced execution across multiple threads.
Examples
You can find the Echo Server, test and fs examples in the examples directory.
Benchmarking
Extensive benchmarking has been done to prove Orengine’s superiority.
Echo Server
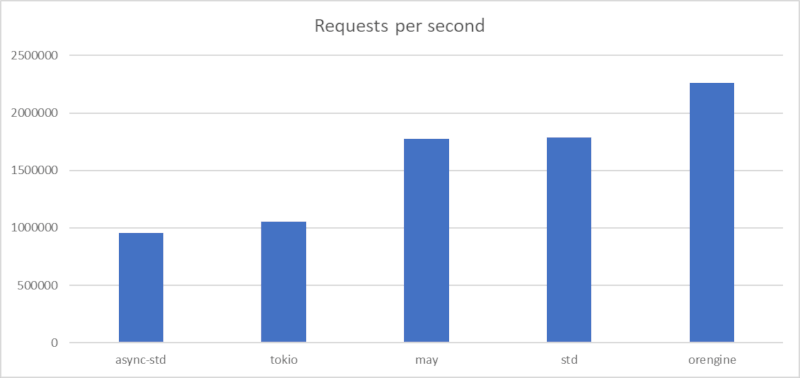
Memory Usage
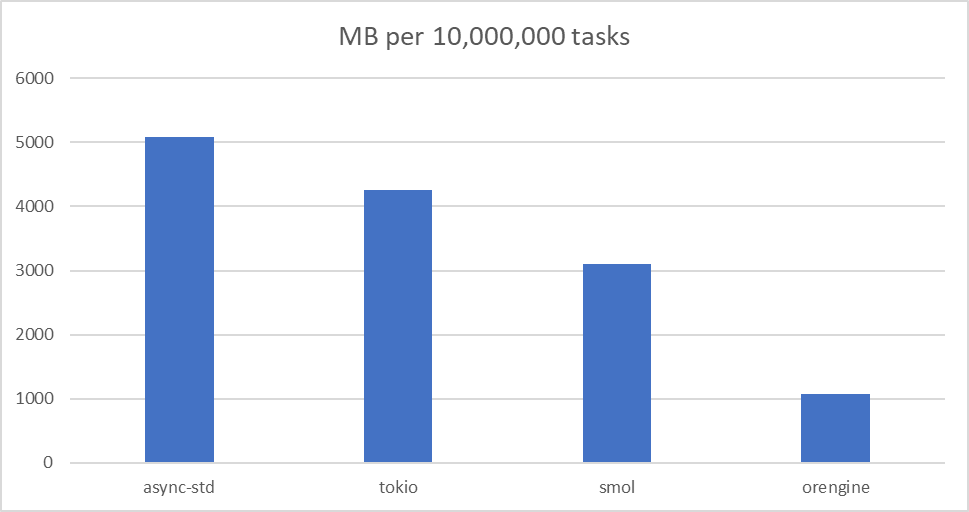
Read more about the benchmarks in the benchmarks directory.
License
This project is licensed under the MIT license.
Contributors
Feel free to offer your ideas, flag bugs, or create new functionality. We welcome any help in development or promotion.
Dependencies
~3–11MB
~113K SLoC