34 releases
Uses new Rust 2024
| 0.12.0 | Apr 19, 2025 |
|---|---|
| 0.11.0 | Feb 19, 2025 |
| 0.10.0 | Dec 21, 2024 |
| 0.9.5 | Dec 22, 2023 |
| 0.1.0 | Dec 31, 2020 |
#10 in Graphics APIs
2,181 downloads per month
Used in 36 crates
(9 directly)
320KB
6K
SLoC
opencl3
![]()
![]()
![]()
![]()
![]()
A Rust implementation of the Khronos OpenCL API.
Description
A relatively simple, object based model of the OpenCL 3.0
API.
It is built upon the cl3 crate, which
provides a functional interface to the OpenCL C API.
OpenCL (Open Computing Language) is framework for general purpose parallel programming across heterogeneous devices including: CPUs, GPUs, DSPs, FPGAs and other processors or hardware accelerators. It is often considered as an open-source alternative to Nvidia's proprietary Compute Unified Device Architecture CUDA for performing General-purpose computing on GPUs, see GPGPU.
OpenCL 3.0
is a unified specification that adds little new functionality to previous OpenCL versions.
It specifies that all OpenCL 1.2 features are mandatory, while all
OpenCL 2.x and 3.0 features are now optional.
Features
This library has:
- A simple API, enabling most OpenCL objects to be created with a single function call.
- Automatic OpenCL resource management using the Drop trait to implement RAII.
- Support for directed acyclic graph OpenCL control flow execution using event wait lists.
- Support for Shared Virtual Memory (SVM) with an SvmVec object that can be serialized and deserialized by serde.
- Support for OpenCL extensions, see OpenCL Extensions.
- Support for multithreading with Send and Sync traits.
Design
The library is object based with most OpenCL objects represented by rust structs.
For example, an OpenCL cl_device_id is represented by Device with methods to get information about the device instead of calling clGetDeviceInfo with the relevant cl_device_info value.
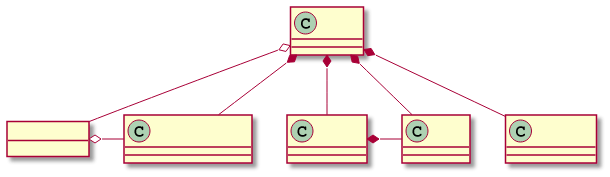
OpenCL Context Class Diagram
The struct methods are simpler to use than their equivalent standalone functions in cl3 because they convert the InfoType enum into the correct underlying type returned by the clGetDeviceInfo call for the cl_device_info value.
Nearly all the structs implement the Drop trait to release their corresponding
OpenCL objects. The exceptions are Platform and Device which don't need to be released. See the crate documentation.
The API for OpenCL versions and extensions are controlled by Rust features such as "CL_VERSION_2_0" and "cl_khr_gl_sharing". To enable an OpenCL version, the feature for that version and all previous OpenCL versions must be enabled, e.g. for "CL_VERSION_2_0"; "CL_VERSION_1_1" and "CL_VERSION_1_2" must also be enabled.
The default features are "CL_VERSION_1_1", "CL_VERSION_1_2" and "CL_VERSION_2_0".
Rust deprecation warnings are given for OpenCL API functions that are deprecated by an enabled OpenCL version e.g., clCreateCommandQueue is deprecated whenever "CL_VERSION_2_0" is enabled.
Use
Ensure that an OpenCL Installable Client Driver (ICD) and the appropriate OpenCL hardware driver(s) are installed, see OpenCL Installation.
opencl3 supports OpenCL 1.2 and 2.0 ICD loaders by default. If you have an
OpenCL 2.0 ICD loader then just add the following to your project's Cargo.toml:
[dependencies]
opencl3 = "0.11"
If your OpenCL ICD loader supports higher versions of OpenCL then add the
appropriate features to opencl3, e.g. for an OpenCL 3.0 ICD loader add the
following to your project's Cargo.toml instead:
[dependencies.opencl3]
version = "0.11"
features = ["CL_VERSION_2_1", "CL_VERSION_2_2", "CL_VERSION_3_0"]
OpenCL extensions and serde support can also be enabled by adding their features, e.g.:
[dependencies.opencl3]
version = "0.11"
features = ["cl_khr_gl_sharing", "cl_khr_dx9_media_sharing", "serde"]
See the OpenCL Guide and OpenCL Description for background on using OpenCL.
Examples
There are examples in the examples directory. The tests also provide examples of how the crate may be used, e.g. see: platform, device, context, integration_test and opencl2_kernel_test.
The library is designed to support events and OpenCL 2 features such as Shared Virtual Memory (SVM) and kernel built-in work-group functions.
It also has optional support for serde e.g.:
const PROGRAM_SOURCE: &str = r#"
kernel void inclusive_scan_int (global int* output,
global int const* values)
{
int sum = 0;
size_t lid = get_local_id(0);
size_t lsize = get_local_size(0);
size_t num_groups = get_num_groups(0);
for (size_t i = 0u; i < num_groups; ++i)
{
size_t lidx = i * lsize + lid;
int value = work_group_scan_inclusive_add(values[lidx]);
output[lidx] = sum + value;
sum += work_group_broadcast(value, lsize - 1);
}
}"#;
const KERNEL_NAME: &str = "inclusive_scan_int";
// Create a Context on an OpenCL device
let context = Context::from_device(&device).expect("Context::from_device failed");
// Build the OpenCL program source and create the kernel.
let program = Program::create_and_build_from_source(&context, PROGRAM_SOURCE, CL_STD_2_0)
.expect("Program::create_and_build_from_source failed");
let kernel = Kernel::create(&program, KERNEL_NAME).expect("Kernel::create failed");
// Create a command_queue on the Context's device
let queue = CommandQueue::create_default_with_properties(
&context,
CL_QUEUE_PROFILING_ENABLE,
0,
)
.expect("CommandQueue::create_default_with_properties failed");
// The input data
const ARRAY_SIZE: usize = 8;
const VALUE_ARRAY: &str = "[3,2,5,9,7,1,4,2]";
// Create an OpenCL SVM vector
let mut test_values = SvmVec::<cl_int>::new(&context);
// Handle test_values if device only supports CL_DEVICE_SVM_COARSE_GRAIN_BUFFER
if !test_values.is_fine_grained() {
// SVM_COARSE_GRAIN_BUFFER needs to know the size of the data to allocate the SVM
test_values = SvmVec::<cl_int>::allocate(&context, ARRAY_SIZE).expect("SVM allocation failed");
// Map the SVM for a SVM_COARSE_GRAIN_BUFFER
unsafe { queue.enqueue_svm_map(CL_BLOCKING, CL_MAP_WRITE, &mut test_values, &[])? };
// Clear the SVM for the deserializer
test_values.clear();
}
ExtendSvmVec(&mut test_values)
.deserialize(&mut deserializer)
.expect("Error deserializing the VALUE_ARRAY JSON string.");
// Make test_values immutable
let test_values = test_values;
// Unmap test_values if not a CL_MEM_SVM_FINE_GRAIN_BUFFER
if !test_values.is_fine_grained() {
let unmap_test_values_event = unsafe { queue.enqueue_svm_unmap(&test_values, &[])? };
unmap_test_values_event.wait()?;
}
// The output data, an OpenCL SVM vector
let mut results =
SvmVec::<cl_int>::allocate(&context, ARRAY_SIZE).expect("SVM allocation failed");
// Run the kernel on the input data
let sum_kernel_event = unsafe {
ExecuteKernel::new(&kernel)
.set_arg_svm(results.as_mut_ptr())
.set_arg_svm(test_values.as_ptr())
.set_global_work_size(ARRAY_SIZE)
.enqueue_nd_range(&queue)?
};
// Wait for the kernel to complete execution on the device
kernel_event.wait()?;
// Map results if not a CL_MEM_SVM_FINE_GRAIN_BUFFER
if !results.is_fine_grained() {
unsafe { queue.enqueue_svm_map(CL_BLOCKING, CL_MAP_READ, &mut results, &[])? };
}
// Convert SVM results to json
let json_results = serde_json::to_string(&results).unwrap();
println!("json results: {}", json_results);
// Unmap results if not a CL_MEM_SVM_FINE_GRAIN_BUFFER
if !results.is_fine_grained() {
let unmap_results_event = unsafe { queue.enqueue_svm_unmap(&results, &[])? };
unmap_results_event.wait()?;
}
The example above was taken from: opencl2serde.rs.
Tests
The crate contains unit, documentation and integration tests.
The tests run the platform and device info functions (among others) so they
can provide useful information about OpenCL capabilities of the system.
It is recommended to run the tests in single-threaded mode, since some of them can interfere with each other when run multi-threaded, e.g.:
cargo test -- --test-threads=1 --show-output
The integration tests are marked ignore so use the following command to
run them:
cargo test -- --test-threads=1 --show-output --ignored
Recent changes
The API has changed considerably since version 0.1 of the library, with the
aim of making the library more consistent and easier to use.
SvmVec was changed recently to provide support for serde deserialization.
It also changed in version 0.5.0 to provide better support for
coarse grain buffer Shared Virtual Memory now that Nvidia is supporting it,
see Nvidia OpenCL.
In version 0.6.0 the Info enums were removed from the underlying cl3 crate and this crate so that data can be read from OpenCL devices in the future using new values that are currently undefined.
In version 0.8.0 deprecation warnings are given for OpenCL API functions that are deprecated by an enabled OpenCL version e.g., clCreateCommandQueue is deprecated whenever "CL_VERSION_2_0" is enabled.
In version 0.9.0 many OpenCL API functions are declared unsafe since they may cause undefined behaviour if called incorrectly.
For information on other changes, see Releases.
Contribution
If you want to contribute through code or documentation, the Contributing guide is the best place to start. If you have any questions, please feel free to ask. Just please abide by our Code of Conduct.
License
Licensed under the Apache License, Version 2.0, as per Khronos Group OpenCL.
You may obtain a copy of the License at: http://www.apache.org/licenses/LICENSE-2.0
Any contribution intentionally submitted for inclusion in the work by you shall be licensed as defined in the Apache-2.0 license above, without any additional terms or conditions, unless you explicitly state otherwise.
OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos.
Dependencies
~1.1–1.8MB
~36K SLoC