2 stable releases
| 1.0.14 | Feb 22, 2024 |
|---|
#651 in Programming languages
2.5MB
6K
SLoC
Contains (ELF exe/lib, 6.5MB) bench/work/main.bin
Higher-order Virtual Machine (HVM)
Higher-order Virtual Machine (HVM) is a pure functional runtime that is lazy, non-garbage-collected and massively parallel. It is also beta-optimal, meaning that, for higher-order computations, it can, in some cases, be exponentially (in the asymptotical sense) faster than alternatives, including Haskell's GHC.
That is possible due to a new model of computation, the Interaction Net, which supersedes the Turing Machine and the Lambda Calculus. Previous implementations of this model have been inefficient in practice, however, a recent breakthrough has drastically improved its efficiency, resulting in the HVM. Despite being relatively new, it already beats mature compilers in some cases, and is being continuously improved.
Welcome to the massively parallel future of computers!
Production Ready Soon!
The code here is a prototype, but the first production ready version is coming soon, with tons of optimizations and - most importantly - correctness work. Follow the progress here: HVM-Core.
Examples
Essentially, HVM is a minimalist functional language that is compiled to a novel runtime based on Interaction Nets. This approach is not only memory-efficient (no GC needed), but also has two significant advantages: automatic parallelism and beta-optimality. The idea is that you write a simple functional program, and HVM will turn it into a massively parallel, beta-optimal executable. The examples below highlight these advantages in action.
Bubble Sort
| From: HVM/examples/sort/bubble/main.hvm | From: HVM/examples/sort/bubble/main.hs |
|
|
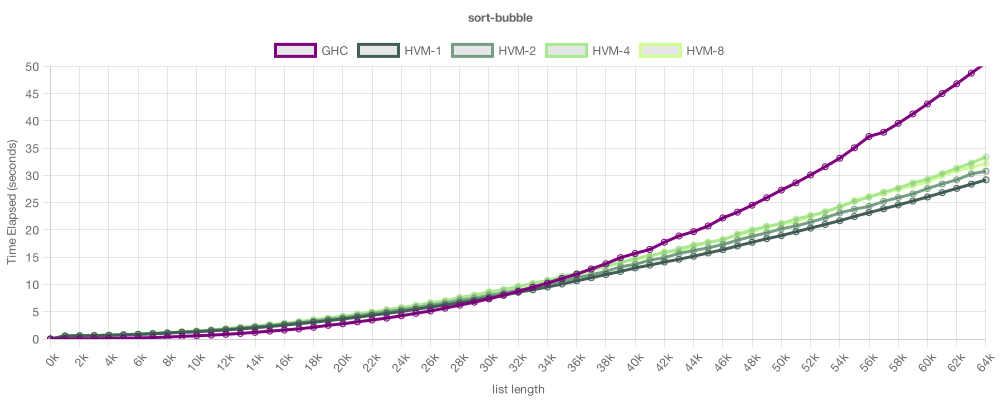
On this example, we run a simple, recursive Bubble Sort on both HVM and GHC (Haskell's compiler). Notice the algorithms are identical. The chart shows how much time each runtime took to sort a list of given size (the lower, the better). The purple line shows GHC (single-thread), the green lines show HVM (1, 2, 4 and 8 threads). As you can see, both perform similarly, with HVM having a small edge. Sadly, here, its performance doesn't improve with added cores. That's because this implementation of Bubble Sort is inherently sequential, so HVM can't improve it.
Radix Sort
| From: HVM/examples/sort/radix/main.hvm | From: HVM/examples/sort/radix/main.hs |
|
|
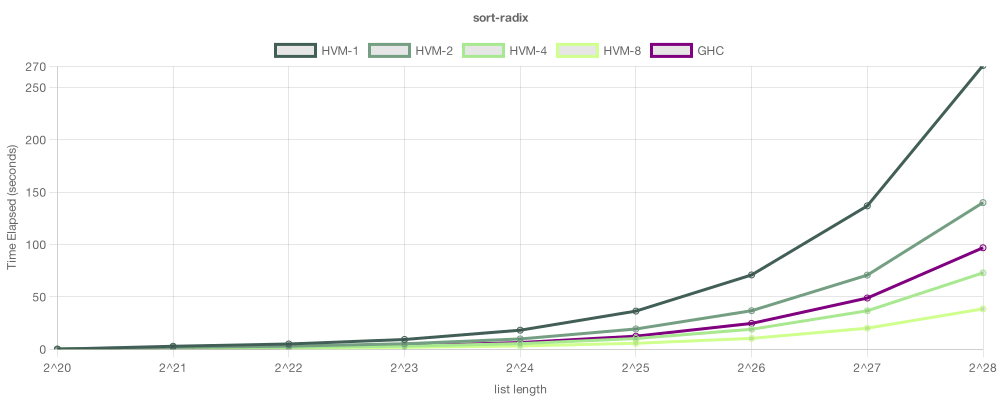
On this example, we try a Radix Sort, based on merging immutable trees. In this test, for now, single-thread performance was superior on GHC - and this is often the case, since GHC is much older and has astronomically more micro-optimizations - yet, since this algorithm is inherently parallel, HVM was able to outperform GHC given enough cores. With 8 threads, HVM sorted a large list 2.5x faster than GHC.
Keep in mind one could parallelize the Haskell version with par annotations, but that would demand time-consuming,
expensive refactoring - and, in some cases, it isn't even possible to use all the available parallelism with par
alone. HVM, on the other hands, will automatically distribute parallel workloads through all available cores, achieving
horizontal scalability. As HVM matures, the single-thread gap will decrease significantly.
Lambda Multiplication
| From: HVM/examples/lambda/multiplication/main.hvm | From: HVM/examples/lambda/multiplication/main.hs |
|
|
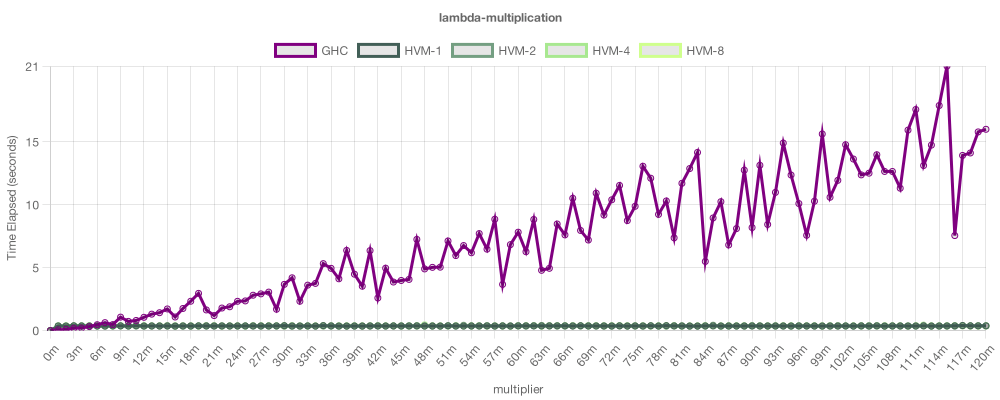
This example implements bitwise multiplication using λ-encodings. Its
purpose is to show yet another important advantage of HVM: beta-optimality. This chart isn't wrong: HVM multiplies
λ-encoded numbers exponentially faster than GHC, since it can deal with very higher-order programs with optimal
asymptotics, while GHC can not. As esoteric as this technique may look, it can actually be very useful to design
efficient functional algorithms. One application, for example, is to implement runtime
deforestation for immutable datatypes. In general,
HVM is capable of applying any fusible function 2^n times in linear time, which sounds impossible, but is indeed true.
Charts made on plotly.com.
Getting Started
-
Install Rust nightly:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh rustup toolchain install nightly -
Install HVM:
cargo +nightly install hvm -
Run an HVM expression:
hvm run "(@x(+ x 1) 41)"
That's it! For more advanced usage, check the complete guide.
More Information
-
To learn more about the underlying tech, check guide/HOW.md.
-
To ask questions and join our community, check our Discord Server.
-
To contact the author directly, send an email to taelin@higherorderco.com.
FAQ
Is HVM faster than GHC in a single core today?
No. For now, HVM seems to be from 50% faster to 3x slower in single thread performance, to even worse if the Haskell code exploits optimizations that HVM doesn't have yet (ST Monad, mutable arrays, inlining, loops).
Is HVM faster than Rust today?
No.
Is HVM faster than C today?
No!
Can HVM be faster than these one day?
Hard question. Perhaps! The underlying model is very efficient. HVM shares the same initial core as Rust (an affine λ-calculus), has great memory management (no thunks, no garbage-collection). Some people think interaction nets are an overhead, but that's not the case - they're the lack of overhead. For example, a lambda on HVM uses only 2 64-bit pointers, which is about as lightweight as it gets. Furthermore, every reduction rule of HVM is a lightweight, constant-time operation that can be compiled to very fast machine code. As such, given enough optimizations, from proper inlining, to real loops, to inner mutability (FBIP-like?), I believe HVM could one day compare to GHC and even Rust or C. But we're still far from that.
Why do the benchmarks compare single-thread vs multi-core?
They do not! Notice all benchmarks include a line for single-threaded HVM execution, which is usually 3x slower than GHC. We do include multi-core HVM execution to let us visualize how its performance scales with added cores, without any change of the code. We do not include multi-core GHC execution because GHC doesn't support automatic parallelism, so it is not possible to make use of threads without changing the code. Keep in mind, once again, the benchmarks are NOT claiming that HVM is faster than GHC today.
Does HVM support the full λ-Calculus, or System-F?
Not yet! HVM is an impementation of the bookkeeping-free version of the reduction algorithm proposed on TOIOFPL book, up to page 40. As such, it doesn't support some λ-terms, such as:
(λx.(x x) λf.λx.(f (f x)))
HVM is, though, Turing complete, so you could implement a full λ-calculus interpreter on it - that limitation only addresses built-in closures. Keep in mind many popular languages don't include the full λ-calculus closures either; Rust, for example, covers a very restricted subset, due to the borrow system. That said, HVM covers a wide class of λ-terms, including the the Y-combinator, church encodings (even algorithms like addition, multiplication and exponentiation), as well as arbitrary datatypes (both native and scott encoded) and recursion.
Will HVM support the full λ-Calculus, or System-F?
Yes! We plan to, by implementing the full algorithm described on the TOIOFPL, i.e., after page 40. Sadly, this results in an overhead that affects the performance of beta-reduction by about 10x. As such, we want to do so with caution to keep HVM efficient. Currently, the plan is:
-
Split lambdas into full-lambdas and light-lambdas
-
Light lambdas are what HVM has today. They're fast, but don't support the full λ-Calculus.
-
Full lambdas will be slower, but support the full λ-Calculus, via "internal brackets/croissants".
-
-
To decrease the overhead, convert full-lambdas to light-lambdas using EAL inference
Elementary Affine Logic is a substructural logic that rejects the structural rule of contraction, replacing it by a controlled form of duplication. By extending HVM with EAL inference, we'll be able to convert most full-lambdas into lightweight lambdas, greatly reducing the associated slowdown.
Finally, keep in mind this only concerns lambdas. Low-order terms (constructors, trees, recursion) aren't affected.
Are unsupported terms "Undefined Behavior"?
No! Unsupported λ-terms like λx.(x x) λf.λx.(f (f x)) don't cause HVM to
display undefined behavior. HVM will always behave deterministically, and give
you a correct result to any input, except it will be in terms of Interaction
Calculus (IC)
semantics. The IC is an alternative to the Lambda Calculus (LC) which differs
slightly in how non-linear variables are treated. As such, these "unsupported"
terms are just cases where the LC and the IC evaluation disagree. In theory, you
could use the HVM as a Interaction Net runtime, and it would always give you
perfectly correct answers under these semantics - but that's not
usual, so we don't talk about it often.
What is HVM's main innovation, in simple terms?
In complex terms, HVM's main innovation is that it is an efficient implementation of the Interaction Net, which is a concurrent model of computation. But there is a way to translate it to more familiar terms. HVM's performance, parallelism and GC-freedom all come from the fact it is based on a linear core - just like Rust! But, on top of it, instead of adding loops and references (plus a "borrow checker"), HVM adds recursion and a lazy, incremental cloning primitive. For example, the expression below:
let xs = (Cons 1 (Cons 2 (Cons 3 Nil))) in [xs, xs]
Computes to:
let xs = (Cons 2 (Cons 3 Nil)) in [(Cons 1 xs), (Cons 1 xs)]
Notice the first Cons 1 layer was cloned incrementally. This makes cloning
essentially free, for the same reason Haskell's lazy evaluator allows you to
make infinite lists: there is no cost until you actually read the copy! That
lazy-cloning primitive is pervasive, and covers all primitives of HVM's runtime:
constructors, numbers and lambdas. This idea, though, breaks down for lambdas:
how do you incrementally copy a lambda?
let f = λx. (2 + x) in [f, f]
If you try it, you'll realize why that's not possible:
let f = (2 + x) in [λx. f, λx. f]
The solution to that question is the main insight that the Interaction Net model brought to the table, and it is described in more details on the HOW.md document.
Is HVM always asymptotically faster than GHC?
No. In most common cases, it will have the same asymptotics. In some cases, it is exponentially faster. In this issue, a user noticed that HVM displays quadratic asymptotics for certain functions that GHC computes in linear time. That was a surprise to me, and, as far as I can tell, despite the "optimal" brand, seems to be a limitation of the underlying theory. That said, there are multiple ways to alleviate, or solve, this problem. One approach would be to implement "safe pointers", also described on the book, which would reduce the cloning overhead and make some quadratic cases linear. But that wouldn't work for all cases. A complimentary approach would be to do linearity analysis, converting problematic quadratic programs in faster, linear versions. Finally, in the worst case, we could add references just like Haskell, but that should be made with a lot of caution, in order not to break the assumptions made by the parallel execution engine. For a more in depth explanation, check read comment on Hacker News.
Is HVM's optimality only relevant for weird, academic λ-encoded terms?
No. HVM's optimality has some very practical benefits. For example, all the "deforesting" techniques that Haskell employs as compile-time rewrite rules, happen naturally, at runtime, on the HVM. For example, Haskell optimizes:
map f . map g
Into:
map (f . g)
This is a hardcoded optimization. On HVM, that occurs naturally, at runtime, in a very general and pervasive way. So, for example, if you have something like:
foldr (.) id funcs :: [Int -> Int]
GHC won't be able to "fuse" the functions on the funcs list, since they're not
known at compile time. HVM will do that just fine. See this
issue for a practical example.
Another practical application for λ-encodings is for monads. On Haskell, the Free Monad library uses Church encodings as an important optimization. Without it, the asymptotics of binding make free monads much less practical. HVM has optimal asymptotics for Church encoded data, making it great for these problems.
Why is HVM so parallelizable?
Because it is fully linear: every piece of data only occurs in one place at the same time, which reduces need for synchronization. Furthermore, it is pure, so there are no global side effects that demand communication. Because of that, reducing HVM expressions in parallel is actually quite simple: we just keep a work strealing queue of redexes, and let a pool of threads computing them. That said, there are two places where HVM needs synchronization:
-
On dup nodes, used by lazy cloning: a lock is needed to prevent threads from passing through, and, thus, accessing the same data
-
On the substitution operation: that's because substitution could send data from one thread to another, so it must be done atomically
In theory, Haskell could be parallelized too, and GHC devs tried it at a point, but I believe the non-linearity of the STG model would make the problem much more complex than it is for the HVM, making it hard to not lose too much performance due to synchronization overhead.
How is the memory footprint of HVM, compared to other runtimes?
It is a common misconception that an "interactional" runtime would somehow consume more memory than a "procedural" runtime like Rust's. That's not the case. Interaction nets, as implemented on HVM, add no overhead, and HVM instantly collects any piece of data that becomes unreachable, just like Rust, so there are no accumulating thunks that result in world-stopping garbage collection, as happens in Haskell currently.
That said, currently, HVM doesn't implement memory-efficient features like references, loops and local mutability. As such, to do anything on HVM today, you need to use immutable datatypes and recursion, which are naturally memory-hungry. Thus, HVM programs today will have increased memory footprint, in relation to C and Rust programs. Thankfully, there is no theoretical limitation preventing us from adding loops and local mutability, and, once/if we do, one can expect the same memory footprint as Rust. The only caveat, though, is shared references: we're not sure if we want to add these, as they might impact parallelism. As such, it is possible that we choose to let lazy clones to be the only form of non-linearity, which would preserve parallelism, at the cost of making some algorithms more memory-hungry.
Is HVM meant to replace GHC?
No! GHC is actually a superb, glorious runtime that is very hard to match. HVM is meant to be a lightweight, massively parallel runtime for functional, and even imperative, languages, from Elm to JavaScript. That said, we do want to support Haskell, but that will require HVM being in a much later stage of maturity, as well as provide support for full lambdas, which it doesn't do yet. Once we do, HVM could be a great alternative for GHC, giving the Haskell community an option to run it in a runtime with automatic parallelism, no slow garbage-collector and beta-optimality. Which will be the best option will likely depend on the type of application you're compiling, but having more choices is generally good and, as such, HVM can be a great tool for the Haskell community.
Is HVM production-ready?
No. HVM is still to be considered a prototype. Right now, I had less than 3 months to work on it directly. It is considerably less mature than other compilers and runtimes like GHC and V8. That said, we're raising funds to have a proper team of engineers working on the HVM. If all goes well, we can expect a production-ready release by Q1 2024.
I've ran an HVM program and it consumed 1950 GB and my computer exploded.
HVM is a prototype. Bugs are expected. Please, open an issue!
I've used HVM in production and now my company is bankrupt.
I quit.
Related Work
Dependencies
~6–14MB
~187K SLoC