5 releases
| 0.1.0 | Aug 1, 2022 |
|---|---|
| 0.0.4-alpha | Jul 24, 2022 |
| 0.0.0 |
|
#451 in Concurrency
1,054 downloads per month
565KB
1.5K
SLoC
A lock-free, partially wait-free, eventually consistent, concurrent hashmap.
This map implementation allows reads to always be wait-free on certain platforms, and almost as
cheap as reading from an Arc<HashMap<K, V>>. Moreover, writes (when executed from a single thread
only) will effectively be wait-free if performed sufficiently infrequently, and readers do not hold
onto guards for extended periods of time.
The trade-offs for extremely cheap reads are that a write can only be exectued from one thread at a time, and eventual consistency. In other words, when a write is performed, all reading threads will only observe the write once they complete their last read and begin a new one.
How is flashmap different?
The underlying algorithm used here is, in principle, the same as that used by
evmap. However the implementation of that algorithm has been
modified to significantly improve reader performance, at the cost of some necessary API
changes and a different performance profile for the writer. More information on the implementation
details of the algorithm can be found in the algorithm module.
When to use flashmap
flashmap is optimized for read-heavy to almost-read-only workloads where a single writer is
acceptable. Good use-cases include:
- High frequency reads with occational insertion/removal
- High frequency modification of existing entries with low contention via interior mutability with occasional insertion/removal
- High frequency reads with another thread executing a moderate write workload
Situations when not to use flashmap include:
- Frequent, small writes which cannot be batched
- Concurrent write access from multiple threads
Examples
use flashmap;
// Create a new map; this function returns a write handle and a read handle
// For more advanced options, see the `Builder` type
let (mut write, read) = flashmap::new::<String, String>();
// Create a write guard to modify the map
let mut write_guard = write.guard();
write_guard.insert("foo".to_owned(), "bar".to_owned());
write_guard.insert("fizz".to_owned(), "buzz".to_owned());
write_guard.insert("baz".to_owned(), "qux".to_owned());
// Publish all previous changes, making them visible to new readers. This has
// the same effect as dropping the guard.
write_guard.publish();
// You must also create a guard from a read handle to read the map, but this
// operation is cheap
assert_eq!(read.guard().get("fizz").unwrap(), "buzz");
// You can clone read handles to get multiple handles to the same map...
let read2 = read.clone();
use std::thread;
// ...and do concurrent reads from different threads
let t1 = thread::spawn(move || {
assert_eq!(read.guard().get("foo").unwrap(), "bar");
read
});
let t2 = thread::spawn(move || {
assert_eq!(read2.guard().get("baz").unwrap(), "qux");
read2
});
let read = t1.join().unwrap();
let _ = t2.join().unwrap();
// Read guards see a "snapshot" of the underlying map. You need to make a new
// guard to see the latest changes from the writer.
// Make a read guard
let read_guard = read.guard();
// Do some modifications while the read guard is still live
let mut write_guard = write.guard();
write_guard.remove("fizz".to_owned());
write_guard.replace("baz".to_owned(), |old| {
let mut clone = old.clone();
clone.push('!');
clone
});
// Make changes visible to new readers
write_guard.publish();
// Since the read guard was created before the write was published, it will
// see the old version of the map
assert!(read_guard.get("fizz").is_some());
assert_eq!(read_guard.get("baz").unwrap(), "qux");
// Drop and re-make the read guard
drop(read_guard);
let read_guard = read.guard();
// Now we see the new version of the map
assert!(read_guard.get("fizz").is_none());
assert_eq!(read_guard.get("baz").unwrap(), "qux!");
// We can continue to read the map even when the writer is dropped
drop(write);
assert_eq!(read_guard.len(), 2);
// The resources associated with the map are deallocated once all read and
// write handles are dropped
// We need to drop this first since it borrows from `read`
drop(read_guard);
// Deallocates the map
drop(read);
Performance
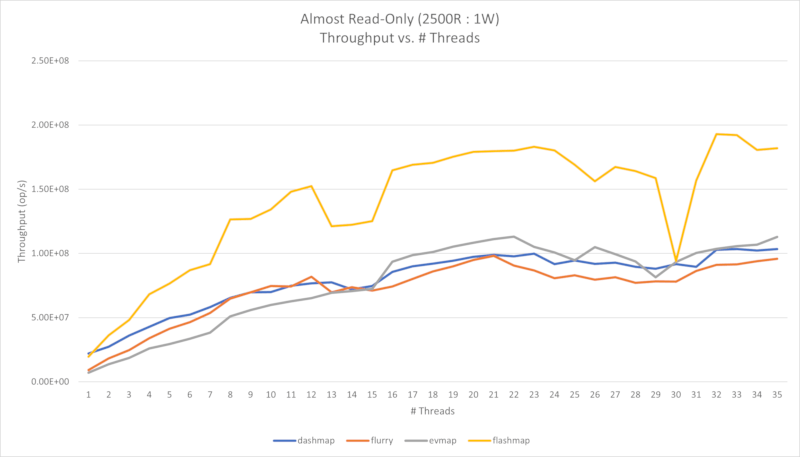
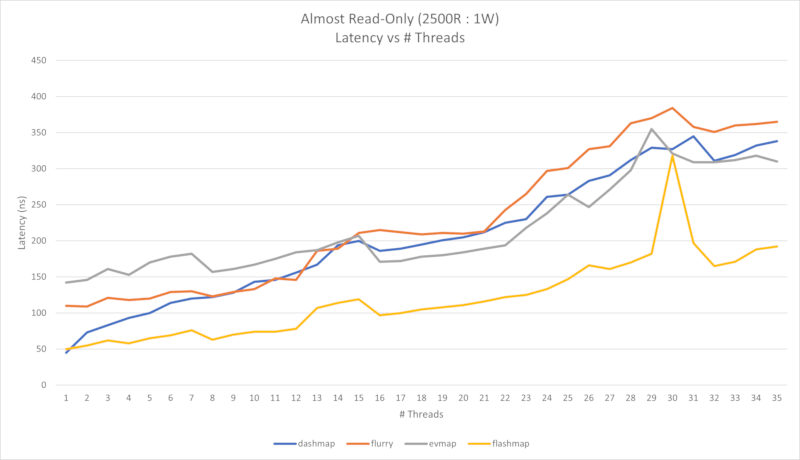
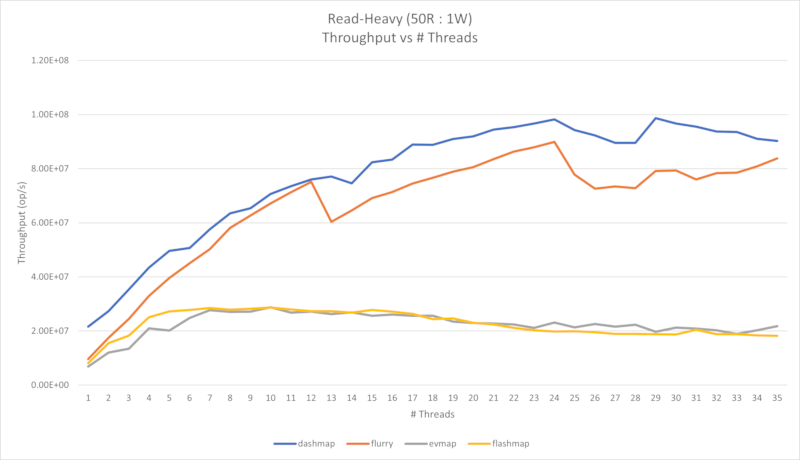
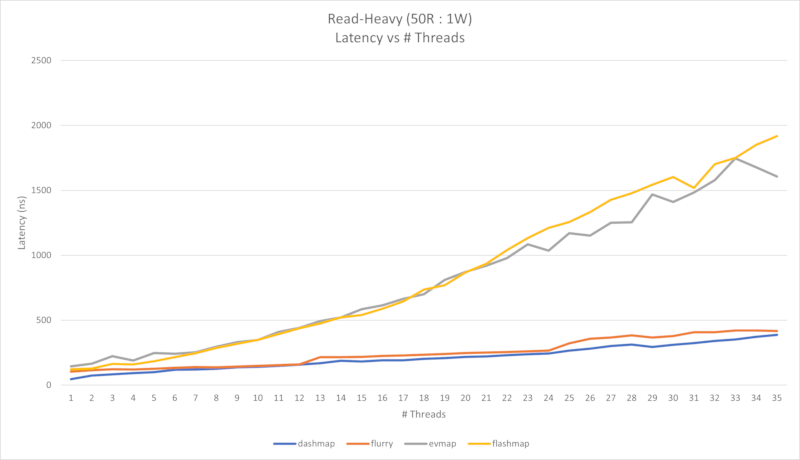
Four performance charts are shown below. First is an almost read-only workload (2500 reads per 1 write), and the second is a read-heavy workload (50 reads per 1 write).
These benchmarks were performed on an AMD 9 Ryzen 5900X 12-core CPU (12 physical cores, 24 logical
cores), which uses the x86-64 architecture. The read-heavy workload was measured using
conc-map-bench, and the almost read-only workload
was measured by using that crate with a modified version of
bustle in order to skew the read percentage above 99%.
In the first case, we can see that throughput scales almost linearly up to the physical core count, and less so up to the logical core count. There seems to be a possibility of extreme latency spikes past the logical core count, but the cause of this has yet to be determined.
In the second use-case, both flashmap and evmap suffer as concurrency increases. This is
because they are single-writer maps, so in order for multiple threads to write concurrently the
writer needs to be wrapped in a mutex. The limiting factor in the read-heavy case is actually the
mutex, since writes are much more expensive when compared to reads. If you need to write to the map
from multiple threads, you should benchmark your code to determine whether or not you fall into the
first case or second case.
Click the text that says "See ... Charts" to see the charts. You can click the text again to collapse the charts as well.
See Almost Read-Only Charts
See Read-Heavy Charts
Dependencies
~0.7–27MB
~309K SLoC