16 releases
| 0.4.2 | Feb 19, 2024 |
|---|---|
| 0.4.1 | Jan 1, 2024 |
| 0.4.0 | Dec 30, 2023 |
| 0.3.91 | Dec 29, 2023 |
| 0.1.1 | Aug 29, 2023 |
#2 in #dust
1MB
44K
SLoC
Dust
High-level programming language with effortless concurrency, automatic memory management, type safety and strict error handling.
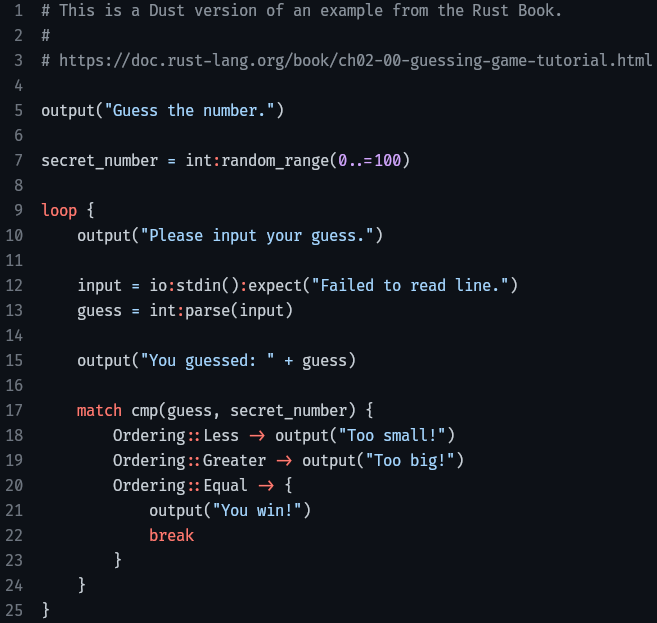
Easy to Read and Write
Dust has simple, easy-to-learn syntax.
output('Hello world!')
Effortless Concurrency
Write multi-threaded code as easily as you would write code for a single thread.
async {
output('Will this one print first?')
output('Or will this one?')
output('Who knows! Each "output" will run in its own thread!')
}
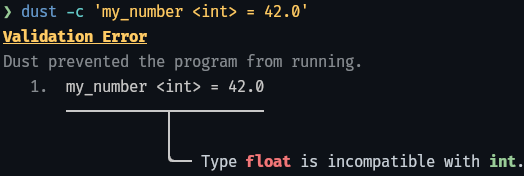
Helpful Errors
Dust shows you exactly where your code went wrong and suggests changes.
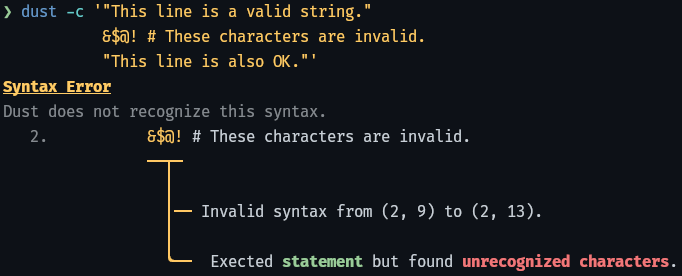
Static analysis
Your code is always validated for safety before it is run.
Dust
Debugging
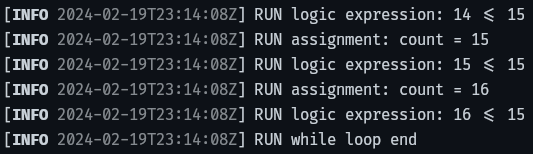
Just set the environment variable DUST_LOG=info and Dust will tell you exactly what your code is doing while it's doing it. If you set DUST_LOG=trace, it will output detailed logs about parsing, abstraction, validation, memory management and runtime. Here are some of the logs from the end of a simple fizzbuzz example.
Automatic Memory Management
Thanks to static analysis, Dust knows exactly how many times each variable is used. This allows Dust to free memory as soon as the variable will no longer be used, without any help from the user.
Error Handling
Runtime errors are no problem with Dust. The Result type represents the output of an operation that might fail. The user must decide what to do in the case of an error.
match io:stdin() {
Result::Ok(input) -> output("We read this input: " + input)
Result::Error(message) -> output("We got this error: " + message)
}
Installation and Usage
There are two ways to compile Dust. It is best to clone the repository and compile the latest code, otherwise the program may be a different version than the one shown on GitHub. Either way, you must have rustup, cmake and a C compiler installed.
To install from the git repository:
git clone https://git.jeffa.io/jeff/dust
cd dust
cargo build --release
To install with cargo:
cargo install dust-lang
Dependencies
~41–58MB
~1M SLoC