1 unstable release
| 0.1.1 | Aug 13, 2024 |
|---|
#1177 in Text processing
760KB
1K
SLoC
BlitzText
BlitzText is a high-performance library for efficient keyword extraction and replacement in strings. It is based on the FlashText and Aho-Corasick algorithm. There are both Rust and Python implementations. Main difference form Aho-Corasick is that BlitzText only matches the longest pattern in a greedy manner.
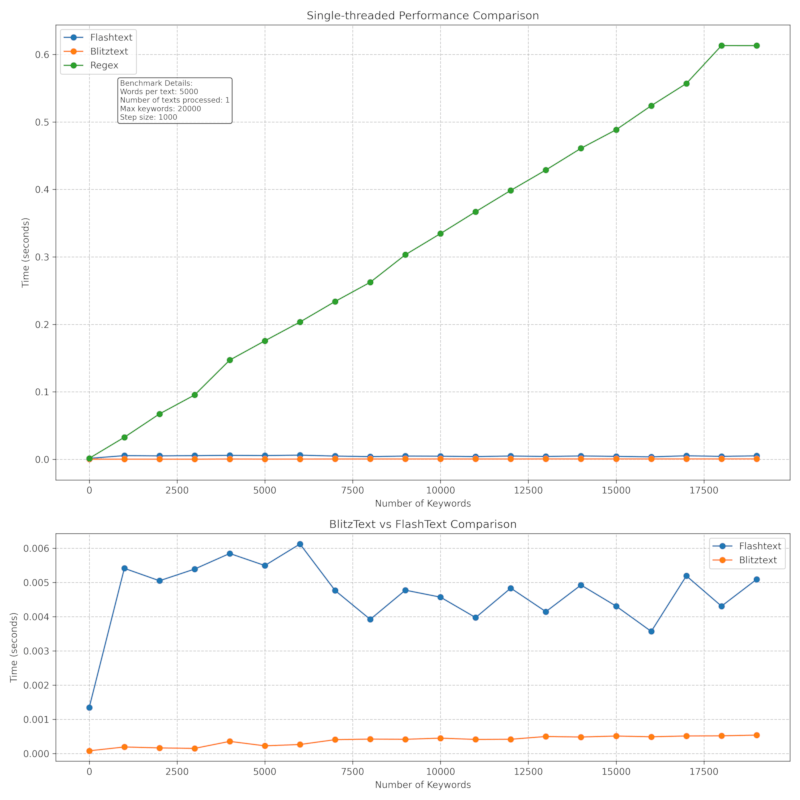
Table of Contents
Installation
Rust
Add this to your Cargo.toml:
[dependencies]
blitztext = "0.1.0"
or
cargo add blitztext
Python
Install the library using pip:
pip install blitztext
Usage
Rust Usage
use blitztext::KeywordProcessor;
fn main() {
let mut processor = KeywordProcessor::new();
processor.add_keyword("rust", Some("Rust Lang"));
processor.add_keyword("programming", Some("Coding"));
let text = "I love rust programming";
let matches = processor.extract_keywords(text, None);
for m in matches {
println!("Found '{}' at [{}, {}]", m.keyword, m.start, m.end);
}
let replaced = processor.replace_keywords(text, None);
println!("Replaced text: {}", replaced);
// Output: "I love Rust Lang Coding"
}
Python Usage
from blitztext import KeywordProcessor
processor = KeywordProcessor()
processor.add_keyword("rust", "Rust Lang")
processor.add_keyword("programming", "Coding")
text = "I love rust programming"
matches = processor.extract_keywords(text)
for m in matches:
print(f"Found '{m.keyword}' at [{m.start}, {m.end}]")
replaced = processor.replace_keywords(text)
// Output: "I love Rust Lang Coding"
print(f"Replaced text: {replaced}")
Features
1. Parallel Processing
For processing multiple texts in parallel:
// Rust
let texts = vec!["Text 1", "Text 2", "Text 3"];
let results = processor.parallel_extract_keywords_from_texts(&texts, None);
# Python
texts = ["Text 1", "Text 2", "Text 3"]
results = processor.parallel_extract_keywords_from_texts(texts)
2. Fuzzy Matching
Both Rust and Python implementations support fuzzy matching:
// Rust
let matches = processor.extract_keywords(text, Some(0.8));
# Python
matches = processor.extract_keywords(text, threshold=0.8)
3. Case Sensitivity
You can enable case-sensitive matching:
// Rust
let mut processor = KeywordProcessor::with_options(true, false);
processor.add_keyword("Rust", Some("Rust Lang"));
let matches = processor.extract_keywords("I love Rust and rust", None);
// Only "Rust" will be matched, not "rust"
# Python
processor = KeywordProcessor(case_sensitive=True)
processor.add_keyword("Rust", "Rust Lang")
matches = processor.extract_keywords("I love Rust and rust")
# Only "Rust" will be matched, not "rust"
4. Overlapping Matches
Enable overlapping matches:
// Rust
let mut processor = KeywordProcessor::with_options(false, true);
processor.add_keyword("word", None);
processor.add_keyword("sword", None);
let matches = processor.extract_keywords("I have a sword", None);
// "word" will be matched
# Python
processor = KeywordProcessor(allow_overlaps=True)
processor.add_keyword("word")
matches = processor.extract_keywords("I have a sword")
# "word" will be matched
5. Custom Non-Word Boundaries
This library uses the concept of non-word boundaries to determine where words begin and end. By default, alphanumeric characters and underscores are considered part of a word. You can customize this behavior to fit your specific needs.
Understanding Non-Word Boundaries
- Characters defined as non-word boundaries are considered part of a word.
- Characters not defined as non-word boundaries are treated as word separators.
Example
// Rust
let mut processor = KeywordProcessor::new();
processor.add_keyword("rust", None);
processor.add_keyword("programming", Some("coding"));
let text = "I-love-rust-programming-and-1coding2";
// Default behavior: '-' is a word separator
let matches = processor.extract_keywords(text, None);
assert_eq!(matches.len(), 2);
// Matches: "rust" and "coding"
// Add '-' as a non-word boundary
processor.add_non_word_boundary('-');
// Now '-' is considered part of words
let matches = processor.extract_keywords(text, None);
assert_eq!(matches.len(), 0);
// No matches, because "rust" and "programming" are now part of larger "words"
# Python
processor = KeywordProcessor()
processor.add_keyword("rust")
processor.add_keyword("programming", "coding")
text = "I-love-rust-programming-and-1coding2"
# Default behavior: '-' is a word separator
matches = processor.extract_keywords(text)
assert len(matches) == 2
# Matches: "rust" and "coding"
# Add '-' as a non-word boundary
processor.add_non_word_boundary('-')
# Now '-' is considered part of words
matches = processor.extract_keywords(text)
assert len(matches) == 0
# No matches, because "rust" and "programming" are now part of larger "words"
Setting a whole new set of non-word boundaries
// Rust
processor.set_non_word_boundaries(&['-', '_', '@']);
# Python
processor.set_non_word_boundaries(['-', '_', '@'])
Performance
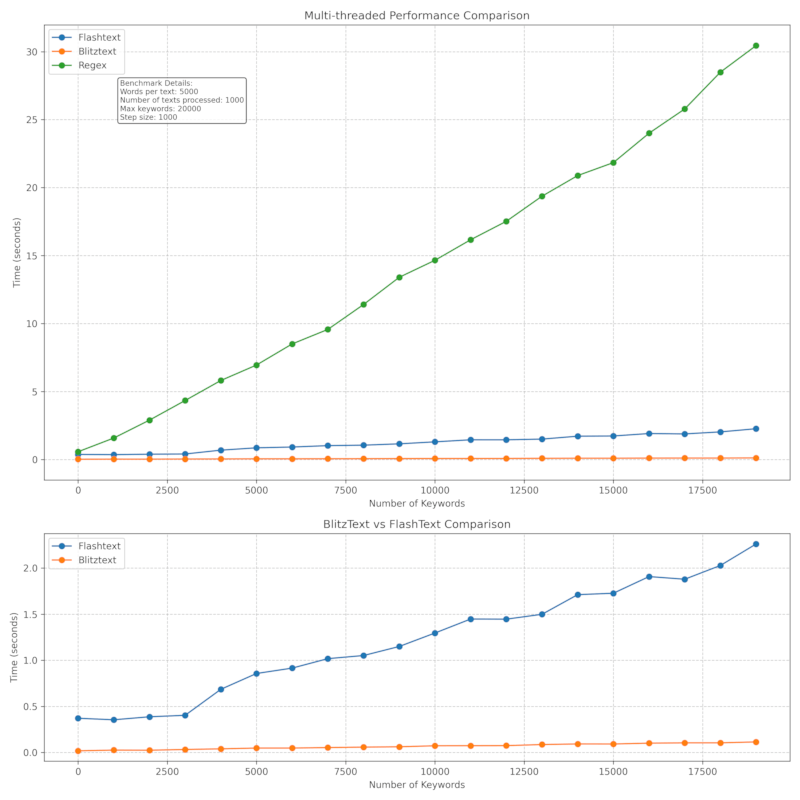
BlitzText is designed for high performance, making it suitable for processing large volumes of text. Benchmark details here.
Mult-threaded performance:
Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
Issues
If you encounter any problems, please file an issue along with a detailed description.
License
This project is licensed under the MIT License.
Dependencies
~9MB
~171K SLoC