29 stable releases (6 major)
| 7.0.4 | Dec 8, 2024 |
|---|---|
| 7.0.2 | Sep 25, 2024 |
| 6.1.1 | May 18, 2022 |
| 6.1.0 | Mar 10, 2022 |
| 0.0.1 |
|
#18 in Parser implementations
813,863 downloads per month
Used in 552 crates
(42 directly)
110KB
350 lines
lexical
High-performance numeric conversion routines for use in a no_std environment. This does not depend on any standard library features, nor a system allocator. Comprehensive benchmarks can be found at lexical-benchmarks.
Similar Projects
If you want a minimal, performant float parser, recent versions of the Rust standard library should be sufficient. For high-performance integer formatters, look at itoa. The metrics section contains a detailed comparison of various crates and their performance in comparison to lexical. Lexical is the currently fastest Rust number formatter and parser, and is tested against:
Table of Contents
- Getting Started
- Partial/Complete Parsers
- no_std
- Features
- Customization
- Documentation
- Validation
- Metrics
- Safety
- Platform Support
- Versioning and Version Support
- Changelog
- License
- Contributing
Getting Started
Add lexical to your Cargo.toml:
[dependencies]
lexical-core = "^1.0"
And get started using lexical:
// Number to string
use lexical_core::BUFFER_SIZE;
let mut buffer = [b'0'; BUFFER_SIZE];
lexical_core::write(3.0, &mut buffer); // "3.0", always has a fraction suffix,
lexical_core::write(3, &mut buffer); // "3"
// String to number.
let i: i32 = lexical_core::parse("3")?; // Ok(3), auto-type deduction.
let f: f32 = lexical_core::parse("3.5")?; // Ok(3.5)
let d: f64 = lexical_core::parse("3.5")?; // Ok(3.5), error checking parse.
let d: f64 = lexical_core::parse("3a")?; // Err(Error(_)), failed to parse.
In order to use lexical in generic code, the trait bounds FromLexical (for parse) and ToLexical (for to_string) are provided.
/// Multiply a value in a string by multiplier, and serialize to string.
fn mul_2<T>(value: &str, multiplier: T)
-> Result<String, lexical_core::Error>
where
T: lexical_core::ToLexical + lexical_core::FromLexical,
{
let value: T = lexical_core::parse(value.as_bytes())?;
let mut buffer = [b'0'; lexical_core::BUFFER_SIZE];
let bytes = lexical_core::write(value * multiplier, &mut buffer);
Ok(std::str::from_utf8(bytes).unwrap())
}
Partial/Complete Parsers
Lexical has both partial and complete parsers: the complete parsers ensure the entire buffer is used while parsing, without ignoring trailing characters, while the partial parsers parse as many characters as possible, returning both the parsed value and the number of parsed digits. Upon encountering an error, lexical will return an error indicating both the error type and the index at which the error occurred inside the buffer.
Complete Parsers
// This will return Err(Error::InvalidDigit(3)), indicating
// the first invalid character occurred at the index 3 in the input
// string (the space character).
let x: i32 = lexical_core::parse(b"123 456")?;
Partial Parsers
// This will return Ok((123, 3)), indicating that 3 digits were successfully
// parsed, and that the returned value is `123`.
let (x, count): (i32, usize) = lexical_core::parse_partial(b"123 456")?;
no_std
lexical-core does not depend on a standard library, nor a system allocator. To use lexical-core in a no_std environment, add the following to Cargo.toml:
[dependencies.lexical-core]
version = "1.0.0"
default-features = false
# Can select only desired parsing/writing features.
features = ["write-integers", "write-floats", "parse-integers", "parse-floats"]
And get started using lexical:
// A constant for the maximum number of bytes a formatter will write.
use lexical_core::BUFFER_SIZE;
let mut buffer = [b'0'; BUFFER_SIZE];
// Number to string. The underlying buffer must be a slice of bytes.
let count = lexical_core::write(3.0, &mut buffer);
assert_eq!(buffer[..count], b"3.0");
let count = lexical_core::write(3i32, &mut buffer);
assert_eq!(buffer[..count], b"3");
// String to number. The input must be a slice of bytes.
let i: i32 = lexical_core::parse(b"3")?; // Ok(3), auto-type deduction.
let f: f32 = lexical_core::parse(b"3.5")?; // Ok(3.5)
let d: f64 = lexical_core::parse(b"3.5")?; // Ok(3.5), error checking parse.
let d: f64 = lexical_core::parse(b"3a")?; // Err(Error(_)), failed to parse.
Features
Lexical feature-gates each numeric conversion routine, resulting in faster compile times if certain numeric conversions. These features can be enabled/disabled for both lexical-core (which does not require a system allocator) and lexical. By default, all conversions are enabled.
- parse-floats: Enable string-to-float conversions.
- parse-integers: Enable string-to-integer conversions.
- write-floats: Enable float-to-string conversions.
- write-integers: Enable integer-to-string conversions.
Lexical is highly customizable, and contains numerous other optional features:
- std: Enable use of the Rust standard library (enabled by default).
- power-of-two: Enable conversions to and from non-decimal strings.
With power_of_two enabled, the radixes
{2, 4, 8, 10, 16, and 32}are valid, otherwise, only 10 is valid. This enables common conversions to/from hexadecimal integers/floats, without requiring large pre-computed tables for other radixes. - radix: Allow conversions to and from non-decimal strings.
With radix enabled, any radix from 2 to 36 (inclusive) is valid, otherwise, only 10 is valid.
- format: Customize acceptable number formats for number parsing and writing.
With format enabled, the number format is dictated through bitflags and masks packed into a
u128. These dictate the valid syntax of parsed and written numbers, including enabling digit separators, requiring integer or fraction digits, and toggling case-sensitive exponent characters. - compact: Optimize for binary size at the expense of performance.
This minimizes the use of pre-computed tables, producing significantly smaller binaries.
- f16: Add support for numeric conversions to-and-from 16-bit floats.
Adds
f16, a half-precision IEEE-754 floating-point type, andbf16, the Brain Float 16 type, and numeric conversions to-and-from these floats. Note that since these are storage formats, and therefore do not have native arithmetic operations, all conversions are done using an intermediatef32.
To ensure memory safety, we extensively fuzz the all numeric conversion routines. See the Safety section below for more information.
Lexical also places a heavy focus on code bloat: with algorithms both optimized for performance and size. By default, this focuses on performance, however, using the compact feature, you can also opt-in to reduced code size at the cost of performance. The compact algorithms minimize the use of pre-computed tables and other optimizations at a major cost to performance.
Customization
Lexical is extensively customizable to support parsing numbers from a wide variety of programming languages, such as 1_2_3. However, lexical takes the concept of "you don't pay for what you don't use" seriously: enabling the format feature does not affect the performance of parsing regular numbers: only those with digit separators.
⚠ WARNING: When changing the number of significant digits written, disabling the use of exponent notation, or changing exponent notation thresholds,
BUFFER_SIZEmay be insufficient to hold the resulting output.WriteOptions::buffer_sizewill provide a correct upper bound on the number of bytes written. If a buffer of insufficient length is provided, lexical-core will panic.
Every language has competing specifications for valid numerical input, meaning a number parser for Rust will incorrectly accept or reject input for different programming or data languages. For example:
// Valid in Rust strings.
// Not valid in JSON.
let f: f64 = lexical_core::parse(b"3.e7")?; // 3e7
// Let's only accept JSON floats.
const JSON: u128 = lexical_core::format::JSON;
let options = ParseFloatOptions::new();
let f: f64 = lexical_core::parse_with_options::<JSON>(b"3.0e7", &options)?; // 3e7
let f: f64 = lexical_core::parse_with_options::<JSON>(b"3.e7", &options)?; // Errors!
Due the high variability in the syntax of numbers in different programming and data languages, we provide 2 different APIs to simplify converting numbers with different syntax requirements.
- Number Format API (feature-gated via
formatorpower-of-two).This is a packed struct contained flags to specify compile-time syntax rules for number parsing or writing. This includes features such as the radix of the numeric string, digit separators, case-sensitive exponent characters, optional base prefixes/suffixes, and more.
- Options API.
This contains run-time rules for parsing and writing numbers. This includes exponent break points, rounding modes, the exponent and decimal point characters, and the string representation of NaN and Infinity.
A limited subset of functionality is documented in examples below, however, the complete specification can be found in the API reference documentation (parse-float, parse-integer, and write-float).
Number Format API
The number format class provides numerous flags to specify number syntax when parsing or writing. When the power-of-two feature is enabled, additional flags are added:
- The radix for the significant digits (default
10). - The radix for the exponent base (default
10). - The radix for the exponent digits (default
10).
When the format feature is enabled, numerous other syntax and digit separator flags are enabled, including:
- A digit separator character, to group digits for increased legibility.
- Whether leading, trailing, internal, and consecutive digit separators are allowed.
- Toggling required float components, such as digits before the decimal point.
- Toggling whether special floats are allowed or are case-sensitive.
Many pre-defined constants therefore exist to simplify common use-cases, including:
- JSON, XML, TOML, YAML, SQLite, and many more.
- Rust, Python, C#, FORTRAN, COBOL literals and strings, and many more.
An example of building a custom number format is as follows:
const FORMAT: u128 = lexical_core::NumberFormatBuilder::new()
// Disable exponent notation.
.no_exponent_notation(true)
// Disable all special numbers, such as Nan and Inf.
.no_special(true)
.build();
// Due to use in a `const fn`, we can't panic or expect users to unwrap invalid
// formats, so it's up to the caller to verify the format. If an invalid format
// is provided to a parser or writer, the function will error or panic, respectively.
debug_assert!(lexical_core::format_is_valid::<FORMAT>());
Options API
The options API allows customizing number parsing and writing at run-time, such as specifying the maximum number of significant digits, exponent characters, and more.
An example of building a custom options struct is as follows:
use std::num;
let options = lexical_core::WriteFloatOptions::builder()
// Only write up to 5 significant digits, IE, `1.23456` becomes `1.2345`.
.max_significant_digits(num::NonZeroUsize::new(5))
// Never write less than 5 significant digits, `1.1` becomes `1.1000`.
.min_significant_digits(num::NonZeroUsize::new(5))
// Trim the trailing `.0` from integral float strings.
.trim_floats(true)
// Use a European-style decimal point.
.decimal_point(b',')
// Panic if we try to write NaN as a string.
.nan_string(None)
// Write infinity as "Infinity".
.inf_string(Some(b"Infinity"))
.build()
.unwrap();
Documentation
Lexical's API reference can be found on docs.rs, as can lexical-core's. Detailed descriptions of the algorithms used can be found here:
In addition, descriptions of how lexical handles digit separators and implements big-integer arithmetic are also documented.
Validation
Float-Parsing
Float parsing is difficult to do correctly, and major bugs have been found in implementations from libstdc++'s strtod to Python. In order to validate the accuracy of the lexical, we employ the following external tests:
- Hrvoje Abraham's strtod test cases.
- Rust's test-float-parse unittests.
- Testbase's stress tests for converting from decimal to binary.
- Nigel Tao's tests extracted from test suites for Freetype, Google's double-conversion library, IBM's IEEE-754R compliance test, as well as numerous other curated examples.
- Various difficult cases reported on blogs.
Lexical is extensively used in production, the same float parsing algorithm has been adopted by Golang's and Rust's standard libraries, and is unlikely to have correctness issues.
Metrics
Various benchmarks, binary sizes, and compile times are shown here. All the benchmarks can be found on lexical-benchmarks. All benchmarks used a black box to avoid optimizing out the result and leading to misleading metrics.
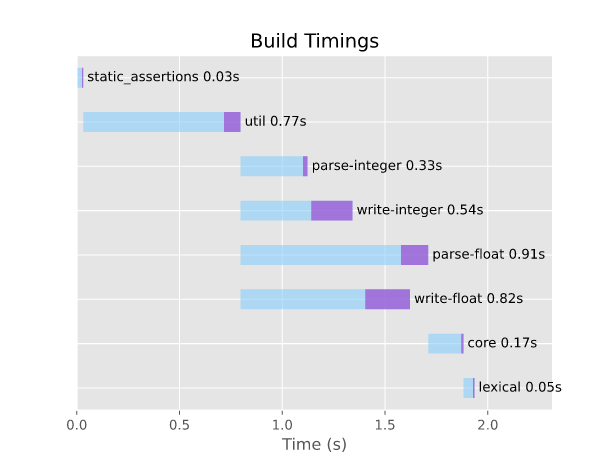
Build Timings
The compile-times when building with all numeric conversions enabled. For a more fine-tuned breakdown, see build timings.
Binary Size
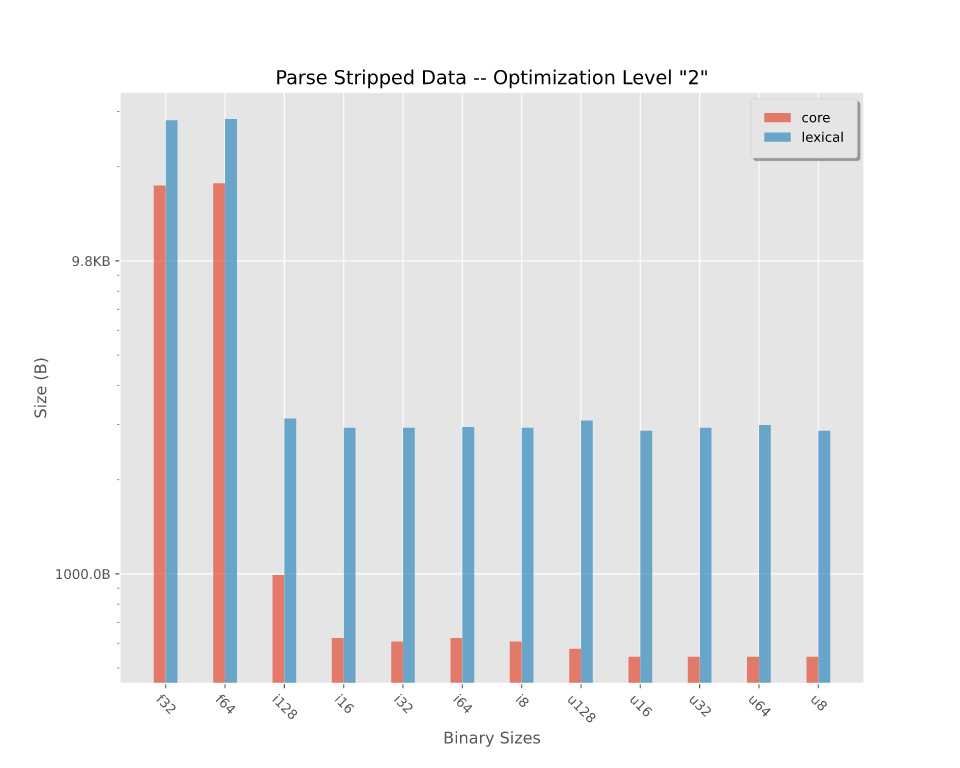
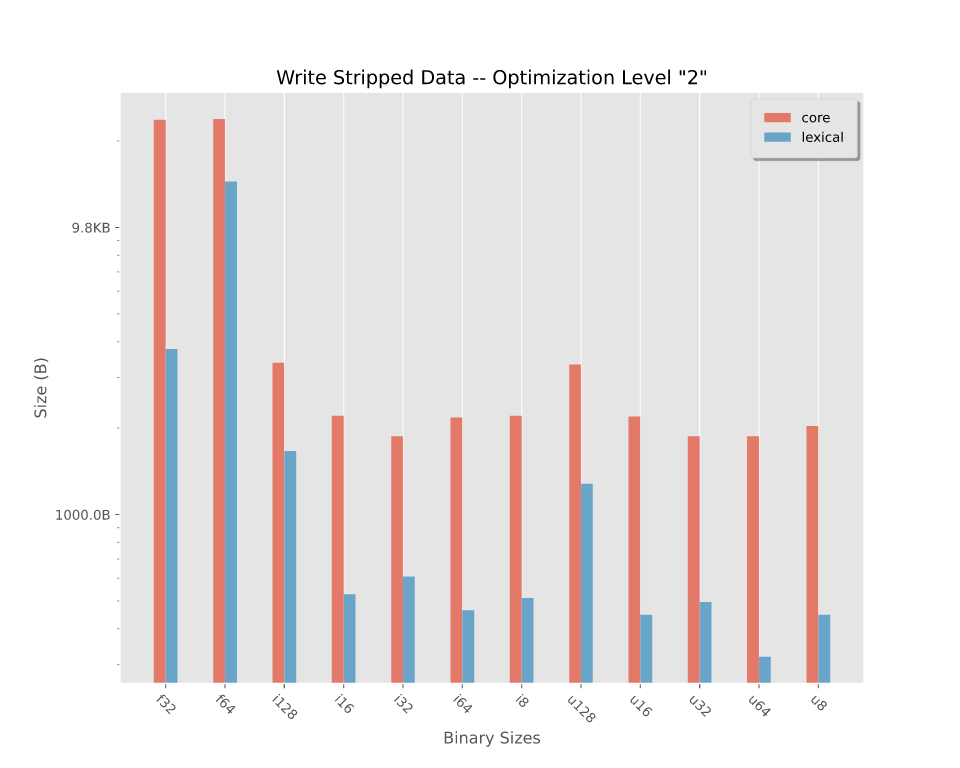
The binary sizes of stripped binaries compiled at optimization level "2". For a more fine-tuned breakdown, see binary sizes.
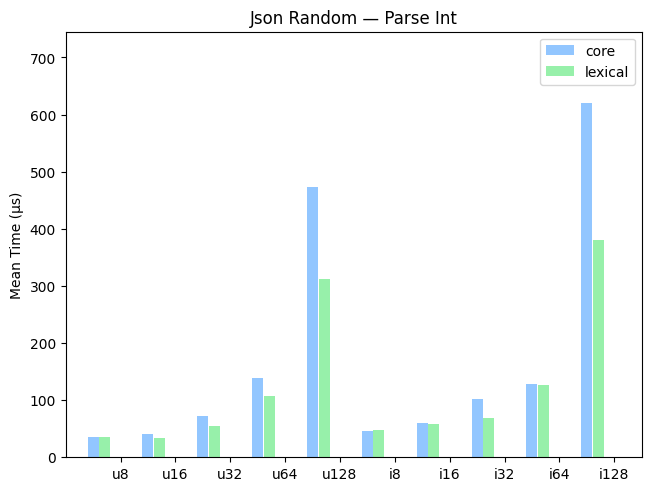
Benchmarks — Parse Integer
Random
A benchmark on randomly-generated integers uniformly distributed over the entire range.
Simple
A benchmark on randomly-generated integers from 1-1000.
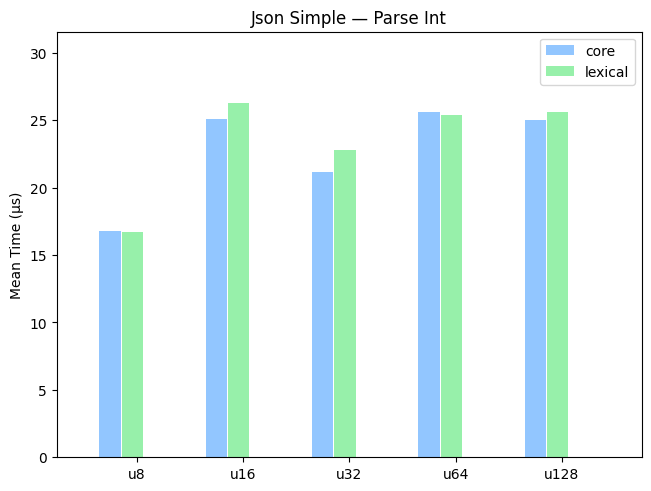
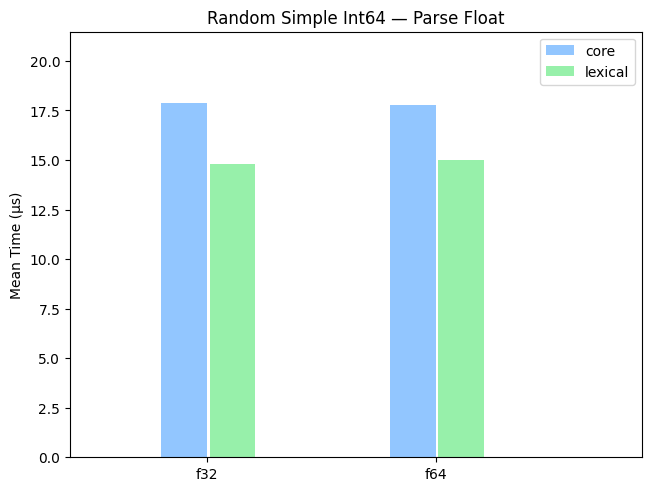
Benchmarks — Parse Float
Real-World Datasets
A benchmark on parsing floats from various real-world data sets, including Canada, Mesh, and astronomical data (earth).
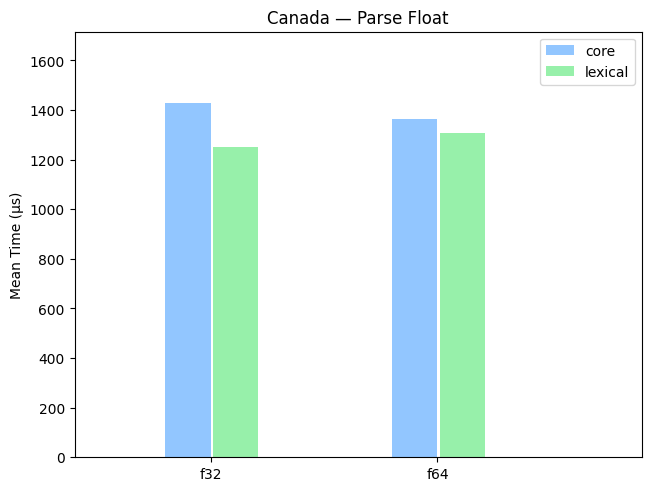
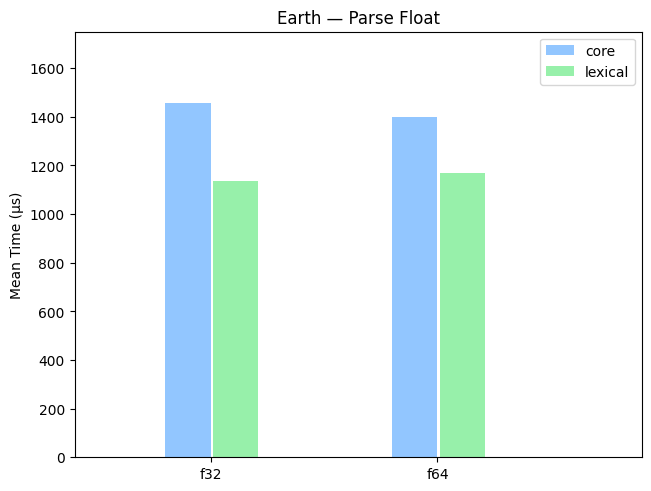
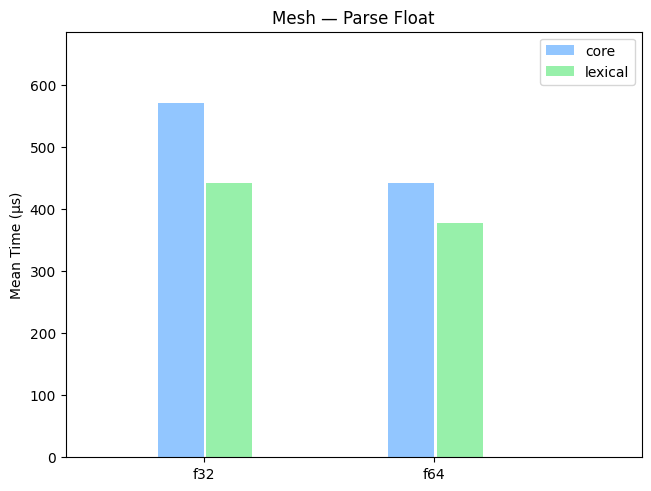
Random
A benchmark on randomly-generated integers uniformly distributed over the entire range.

Simple
A benchmark on randomly-generated integers from 1-1000.
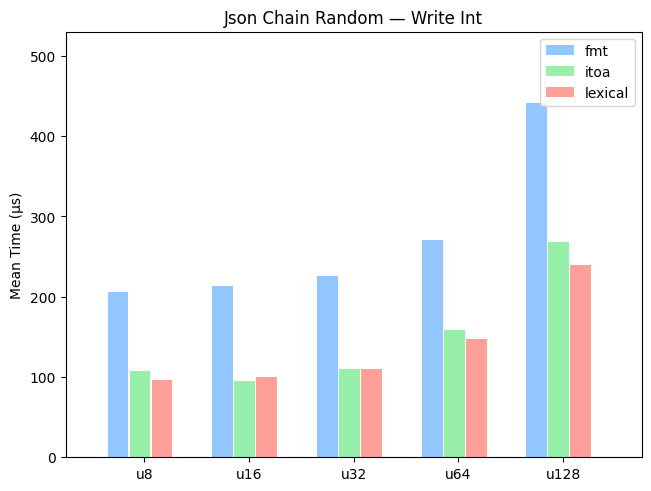
Benchmarks — Write Integer
Random
A benchmark on randomly-generated integers uniformly distributed over the entire range.
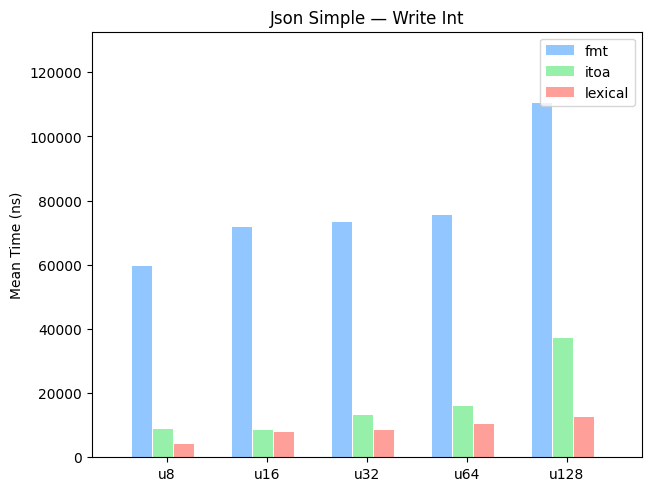
Simple
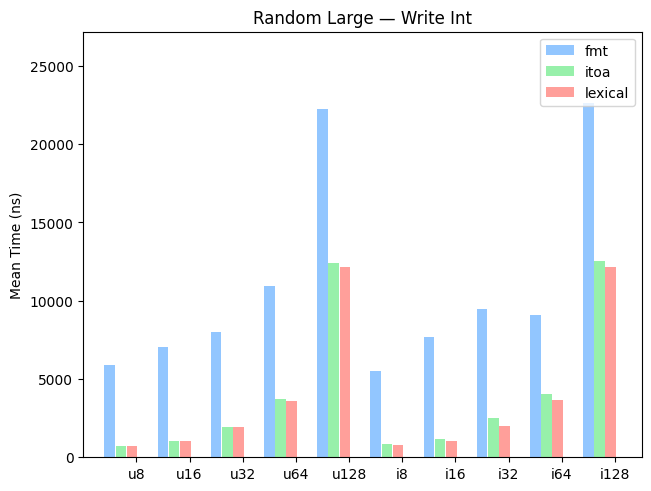
Large
Benchmarks — Write Float
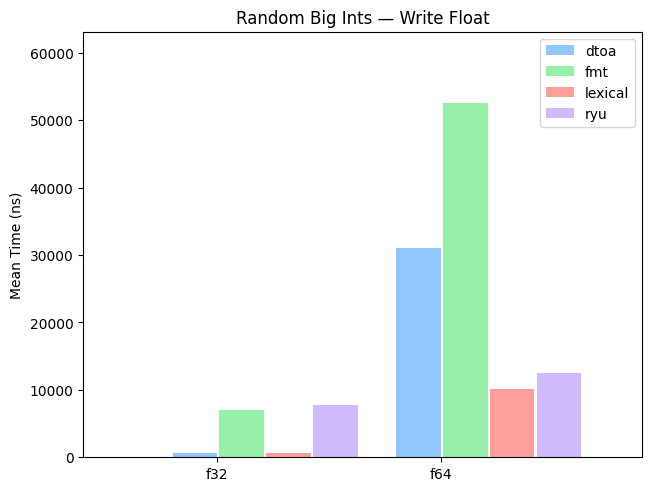
Big Integer
A benchmarks for values with a large integers.
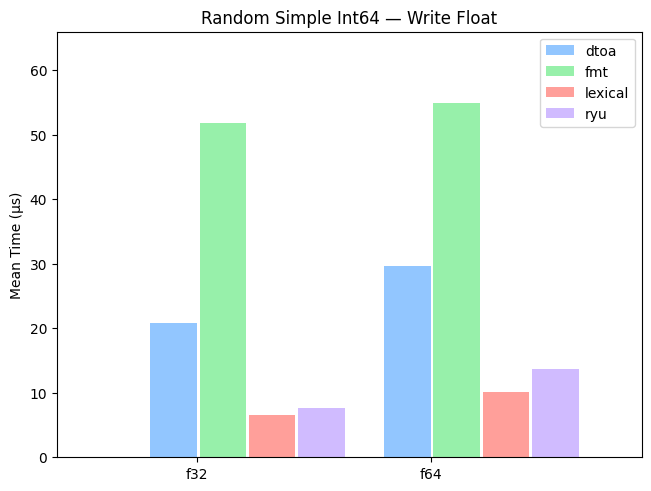
Simple 64-Bit Inteers
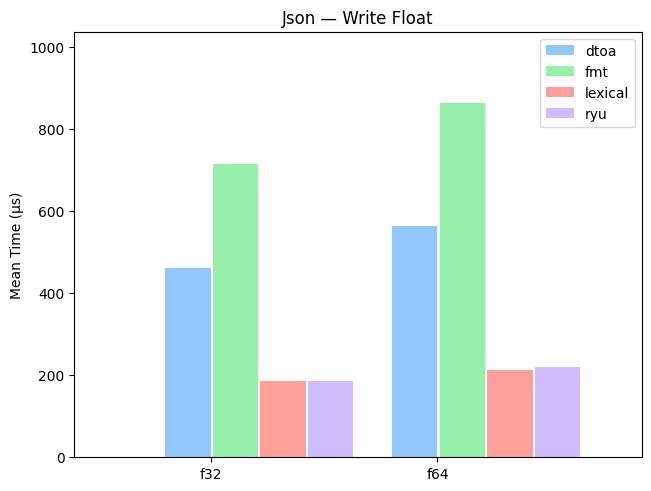
Random
Safety
Due to the use of memory unsafe code in the library, we extensively fuzz our float writers and parsers. The fuzz harnesses may be found under fuzz, and are run continuously. So far, we've parsed and written over 72 billion floats.
Platform Support
lexical-core is tested on a wide variety of platforms, including big and small-endian systems, to ensure portable code. Supported architectures include:
- x86_64 Linux, Windows, macOS, Android, iOS, FreeBSD, and NetBSD.
- x86 Linux, macOS, Android, iOS, and FreeBSD.
- aarch64 (ARM8v8-A) Linux, Android, and iOS.
- armv7 (ARMv7-A) Linux, Android, and iOS.
- arm (ARMv6) Linux, and Android.
- powerpc (PowerPC) Linux.
- powerpc64 (PPC64) Linux.
- powerpc64le (PPC64LE) Linux.
- s390x (IBM Z) Linux.
lexical-core should also work on a wide variety of other architectures and ISAs. If you have any issue compiling lexical-core on any architecture, please file a bug report.
Versioning and Version Support
Version Support
The currently supported versions are:
- v1.0.x
Due to security considerations, all other versions are not supported and security advisories exist for them..
Rustc Compatibility
- v1.0.x supports 1.63+, including stable, beta, and nightly.
Please report any errors compiling a supported lexical-core version on a compatible Rustc version.
Versioning
lexical uses semantic versioning. Removing support for Rustc versions newer than the latest stable Debian or Ubuntu version is considered an incompatible API change, requiring a major version change.
Changelog
All changes are documented in CHANGELOG.
License
Lexical is dual licensed under the Apache 2.0 license as well as the MIT license. See the LICENSE.md file for full license details.
Contributing
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in lexical by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions. Contributing to the repository means abiding by the code of conduct.
For the process on how to contribute to lexical, see the development quick-start guide.
Dependencies
~730KB
~12K SLoC