16 releases (9 breaking)
| 0.10.1 | Feb 24, 2024 |
|---|---|
| 0.10.0 | Feb 7, 2023 |
| 0.9.0 | Jan 19, 2023 |
| 0.8.3 | Dec 20, 2022 |
| 0.5.1 | Jul 13, 2022 |
#603 in Algorithms
1,040 downloads per month
Used in 14 crates
(4 directly)
220KB
2.5K
SLoC
turborand
![]()
![]()
![]()
![]()
Fast random number generators.
turborand's internal implementations use Wyrand, a simple and fast
generator but not cryptographically secure, and also ChaCha8, a cryptographically
secure generator tuned to 8 rounds of the ChaCha algorithm in order to increase throughput considerably without sacrificing
too much security, as per the recommendations set out in the Too Much Crypto paper.
Examples
use turborand::prelude::*;
let rand = Rng::new();
if rand.bool() {
println!("Success! :D");
} else {
println!("Failure... :(");
}
Sample a value from a list:
use turborand::prelude::*;
let rand = Rng::new();
let values = [1, 2, 3, 4, 5];
let value = rand.sample(&values);
Generate a vector with random values:
use turborand::prelude::*;
use std::iter::repeat_with;
let rand = Rng::new();
let values: Vec<_> = repeat_with(|| rand.f32()).take(10).collect();
no-std Compatibility
turborand can be exposed to no-std environments, however only with reduced capability and feature sets. There'll be no Default implementations, and no new() constructors, so Rng/ChaChaRng seeds must be provided by the user from whatever source available on the platform. Some TurboRand methods will also not be available unless the alloc feature is enabled, which necessitates having a global allocator.
Compiling for WASM
For suppporting WASM builds, you'll need to add the following to your Cargo.toml:
[target.'cfg(target_arch = "wasm32")'.dependencies]
instant = { version = "0.1", features = ["wasm-bindgen"] }
instant needs either the wasm-bindgen or stdweb feature active on WASM in order to compile. stdweb however is unmaintained, but to support future alternatives and features, toggling on WASM support is left to the user of this crate.
Performance
Wyrand is a pretty fast PRNG, and is a good choice when speed is needed while still having decent statistical properties. Currently, the turborand implementation benches extremely well against similar rand algorithms. Below is a chart of the fill_bytes method performance, tested on Windows 10 x64 on an AMD Ryzen 1700 clocked at 3.7Ghz with 32GB RAM at 3066Mhz.
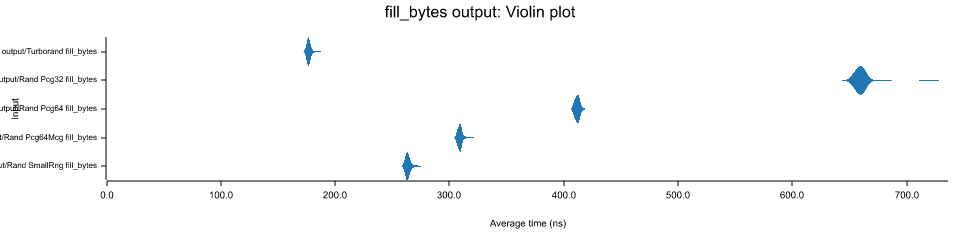
For filling 2048 byte array buffers, turborand's Rng is able to do so in around 170-180ns, whereas SmallRng does it between 260-268ns, and Pcg64Mcg (the fastest PCG impl on 64bit systems) does it in 305-312ns.
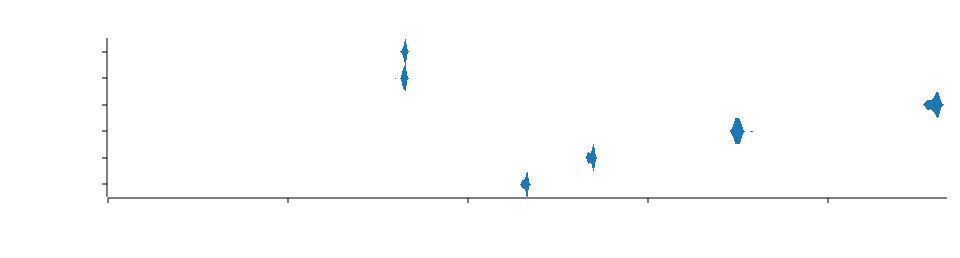
For generating unbound u64 values, turborand and fastrand are equal in performance, which is expected given they both implement the Wyrand algorithm, consistently performing around 820-830ps for generating a u64 value. SmallRng performs around 1.16ns, while Pcg64Mcg is at 1.35ns.
Migrating between versions
Check out MIGRATION.md to get all the notes needed to migrate between major versions of turborand.
License
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Dependencies
~0–480KB