8 stable releases
| 2.2.0 | Mar 7, 2023 |
|---|---|
| 2.1.0 | Feb 27, 2023 |
| 2.0.0 | Apr 28, 2022 |
| 1.2.2 | Apr 20, 2022 |
| 1.2.0 | Jun 12, 2020 |
#1446 in Command line utilities
130KB
2K
SLoC
Masking tape to help commands "do one thing well"
![]()
![]()
![]()
![]()
Taping

- Convert timestamps in /var/log/secure to UNIX time
$ cat /var/log/secure | teip -c 1-15 -- date -f- +%s
- Replace 'WORLD' to 'EARTH' on lines containing 'HELLO'
$ cat file | teip -g HELLO -- sed 's/WORLD/EARTH/'
- Edit 2nd field of the CSV file
$ cat file.csv | teip --csv -f 2 -- tr a-z A-Z
- Edit 2nd, 3rd and 4th fields of TSV file
$ cat file.tsv | teip -D '\t' -f 2-4 -- tr a-z A-Z
- Edit lines containing 'hello' and the three lines before and after it
$ cat access.log | teip -e 'grep -n -C 3 hello' -- sed 's/./@/g'
Performance enhancement
teip allows a command to focus on its own task.
Here is the comparison of processing time to replace approx 761,000 IP addresses with dummy ones in 100 MiB text file.
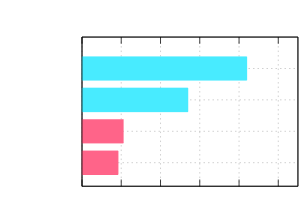
See detail on wiki > Benchmark.
Features
-
Taping: Help the command "do one thing well"
- Bypassing a partial range of standard input to any command whatever you want
- The targeted command just handles bypassed parts of the standard input
- Flexible methods for selecting a range (Select like AWK,
cutorgrep)
-
High performer
- The targeted command's standard input/output are intercepted by multiple
teip's threads asynchronously. - If general UNIX commands on your environment can process a few hundred MB files in a few seconds, then
teipcan do the same or better performance.
- The targeted command's standard input/output are intercepted by multiple
Installation
Linux (x86_64, ARM64)
dpkg
wget https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.deb
sudo dpkg -i ./teip*.deb
apt
wget https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.deb
sudo apt install ./teip*.deb
dnf
sudo dnf install https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.rpm
yum
sudo yum install https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.rpm
If necessary, check the hash value from the latest release page.
Files whose filenames end with sha256 have hash values listed.
macOS (x86_64, ARM64)
Using Homebrew
brew install greymd/tools/teip
Windows (x86_64)
Download installer from here.
See Wiki > Use on Windows in detail.
Other architectures
Check the latest release page for executables for the platform you are using.
If not, please build it from source.
Build from source
With Rust's package manager cargo
cargo install teip
To enable Oniguruma regular expression (-G option), build with --features oniguruma option.
Please make sure libclang shared library is on your environment in advance.
### Ubuntu
$ sudo apt install cargo clang
$ cargo install teip --features oniguruma
### Red Hat base OS
$ sudo dnf install cargo clang
$ cargo install teip --features oniguruma
### Windows (PowerShell) and choco (chocolatey.org)
PS C:\> choco install llvm
PS C:\> cargo install teip --features oniguruma
Usage
USAGE:
teip -g <pattern> [-Gosvz] [--] [<command>...]
teip -c <list> [-svz] [--] [<command>...]
teip -l <list> [-svz] [--] [<command>...]
teip -f <list> [-d <delimiter> | -D <pattern> | --csv] [-svz] [--] [<command>...]
teip -e <string> [-svz] [--] [<command>...]
OPTIONS:
-g <pattern> Bypassing lines that match the regular expression <pattern>
-o -g bypasses only matched parts
-G -g interprets Oniguruma regular expressions.
-c <list> Bypassing these characters
-l <list> Bypassing these lines
-f <list> Bypassing these white-space separated fields
-d <delimiter> Use <delimiter> for field delimiter of -f
-D <pattern> Use regular expression <pattern> for field delimiter of -f
--csv -f interprets <list> as field number of a CSV according to
RFC 4180, instead of white-space separated fields
-e <string> Execute <string> on another process that will receive identical
standard input as the teip, and numbers given by the result
are used as line numbers for bypassing
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-s Execute new command for each bypassed chunk
--chomp Command spawned by -s receives standard input without trailing
newlines
-v Invert the range of bypassing
-z Line delimiter is NUL instead of a newline
ALIASES:
-g <pattern>
-A <number> Alias of -e 'grep -n -A <number> <pattern>'
-B <number> Alias of -e 'grep -n -B <number> <pattern>'
-C <number> Alias of -e 'grep -n -C <number> <pattern>'
--sed <pattern> Alias of -e 'sed -n "<pattern>="'
--awk <pattern> Alias of -e 'awk "<pattern>{print NR}"'
Getting Started
Try this at first.
$ echo "100 200 300 400" | teip -f 3
The result is almost the same as the input but "300" is highlighted and surrounded by [...].
Because -f 3 specifies the 3rd field of space-separated input.
100 200 [300] 400
Understand that the area enclosed in [...] is a hole on the masking tape.
Next, put the sed and its arguments at the end.
$ echo "100 200 300 400" | teip -f 3 sed 's/./@/g'
The result is as below.
Highlight and [...] is gone then.
100 200 @@@ 400
As you can see, the sed only processed the input in the "hole" and ignores masked parts.
Technically, teip passes only highlighted part to the sed and replaces it with the result of the sed.
Off-course, any command whatever you like can be specified. It is called the targeted command in this article.
Let's try the cut as the targeted command to extract the first character only.
$ echo "100 200 300 400" | teip -f 3 cut -c 1
teip: Invalid arguments.
Oops? Why is it failed?
This is because the cut uses the -c option.
The option of the same name is also provided by teip, which is confusing.
When entering a targeted command with teip, it is better to enter it after --.
Then, teip interprets the arguments after -- as the targeted command and its argument.
$ echo "100 200 300 400" | teip -f 3 -- cut -c 1
100 200 3 400
Great, the first character 3 is extracted from 300!
Although -- is not always necessary, it is always better to be used.
So, -- is used in all the examples from here.
Now let's double this number with the awk.
The command looks like the following (Note that the variable to be doubled is not $3).
$ echo "100 200 300 400" | teip -f 3 -- awk '{print $1*2}'
100 200 600 400
OK, the result went from 300 to 600.
Now, let's change -f 3 to -f 3,4 and run it.
$ echo "100 200 300 400" | teip -f 3,4 -- awk '{print $1*2}'
100 200 600 800
The numbers in the 3rd and 4th were doubled!
As some of you may have noticed, the argument of -f is compatible with the LIST of cut.
Let's see how it works with cut --help.
$ echo "100 200 300 400" | teip -f -3 -- sed 's/./@/g'
@@@ @@@ @@@ 400
$ echo "100 200 300 400" | teip -f 2-4 -- sed 's/./@/g'
100 @@@ @@@ @@@
$ echo "100 200 300 400" | teip -f 1- -- sed 's/./@/g'
@@@ @@@ @@@ @@@
Select range by character
The -c option allows you to specify a range by character-base.
The below example is specifing 1st, 3rd, 5th, 7th characters and apply the sed command to them.
$ echo ABCDEFG | teip -c 1,3,5,7
[A]B[C]D[E]F[G]
$ echo ABCDEFG | teip -c 1,3,5,7 -- sed 's/./@/'
@B@D@F@
As same as -f, -c's argument is compatible with cut's LIST.
Processing delimited text like CSV, TSV
The -f option recognizes delimited fields like awk by default.
The continuous white spaces (all forms of whitespace categorized by Unicode) is interpreted as a single delimiter.
$ printf "A B \t\t\t\ C \t D" | teip -f 3 -- sed s/./@@@@/
A B @@@@ C D
This behavior might be inconvenient for the processing of CSV and TSV.
However, the -d option in conjunction with the -f can be used to specify a delimiter.
Now you can process the CSV file like this.
$ echo "100,200,300,400" | teip -f 3 -d , -- sed 's/./@/g'
100,200,@@@,400
In order to process TSV, the TAB character need to be typed.
If you are using Bash, type $'\t' which is one of ANSI-C Quoting.
$ printf "100\t200\t300\t400\n" | teip -f 3 -d $'\t' -- sed 's/./@/g'
100 200 @@@ 400
teip also provides -D option to specify an extended regular expression as the delimiter.
This is useful when you want to ignore consecutive delimiters, or when there are multiple types of delimiters.
$ echo 'A,,,,,B,,,,C' | teip -f 2 -D ',+'
A,,,,,[B],,,,C
$ echo "1970-01-02 03:04:05" | teip -f 2-5 -D '[-: ]'
1970-[01]-[02] [03]:[04]:05
The regular expression of TAB character (\t) can also be specified with the -D option.
$ printf "100\t200\t300\t400\n" | teip -f 3 -D '\t' -- sed 's/./@/g'
100 200 @@@ 400
Regarding available notations of the regular expression, refer to regular expression of Rust.
Complex CSV processing
If you want to process a complex CSV file, such as the one below, which has columns surrounded by double quotes, use the -f option together with the --csv option.
Name,Address,zipcode
Sola Harewatar,"Doreami Road 123
Sorashido city",12877
Yui Nagomi,"Nagomi Street 456, Nagomitei, Oishina town",26930-0312
"Conectol Motimotit Hooklala Glycogen Comex II a.k.a ""Kome kome""","Cooking dam",513123
With --csv, teip will parse the input as a CSV file according to RFC4180. Thus, you can use -f to specify column numbers for CSV files with complex structures.
For example, the CSV just mentioned above will have a "hole" as shown below.
$ cat tests/sample.csv | teip --csv -f2
Name,[Address],zipcode
Sola Harewatar,["Doreami Road 123]
[Sorashido city"],12877
Yui Nagomi,["Nagomi Street 456, Nagomitei, Oishina town"],26930-0312
"Conectol Motimotit Hooklala Glycogen Comex II a.k.a ""Kome kome""",["Cooking dam"],513123
Because -f2 was specified, there is a hole in the second column of each row.
The following command is an example of rewriting all characters in the second column to "@".
$ cat tests/sample.csv | teip --csv -f2 -- sed 's/[^"]/@/g'
Name,@@@@@@@,zipcode
Sola Harewatar,"@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@",12877
Yui Nagomi,"@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@",26930-0312
"Conectol Motimotit Hooklala Glycogen Comex II a.k.a ""Kome kome""","@@@@@@@@@@@",513123
Note for --csv option:
- Double quotation
"surrounding fields are also included in the holes. - Escaped double quotes
""are treated as is; two double quotes""are given as input to the targeted command. - Fields containing newlines will have multiple holes, separated by newlines, instead of a single hole.
- However, if the
-sor-zoption is used, it is treated as a single hole, including line breaks.
- However, if the
Matching with Regular Expression
You can also use -g to select a specific line matching a regular expression as the hole location.
$ echo -e "ABC1\nEFG2\nHIJ3" | teip -g '[GJ]\d'
ABC1
[EFG2]
[HIJ3]
By default, the entire line containing the pattern is the range of holes. With the -o option, the range of holes will be only at matched range.
$ echo -e "ABC1\nEFG2\nHIJ3" | teip -og '[GJ]\d'
ABC1
EF[G2]
HI[J3]
Note that -og is one of the useful idiom and frequently used in this manual.
Here is an example of using \d which matches numbers.
$ echo ABC100EFG200 | teip -og '\d+'
ABC[100]EFG[200]
$ echo ABC100EFG200 | teip -og '\d+' -- sed 's/.*/@@@/g'
ABC@@@EFG@@@
This feature is quite versatile and can be useful for handling the file that has no fixed form like logs, markdown, etc.
What commands are appropriate?
teip bypasses the string in the hole line by line so that each hole is one line of input.
Therefore, a targeted command must follow the below rule.
- A targeted command must print a single line of result for each line of input.
In the simplest example, the cat command always succeeds.
Because the cat prints the same number of lines against the input.
$ echo ABCDEF | teip -og . -- cat
ABCDEF
If the above rule is not satisfied, the result will be inconsistent.
For example, grep may fail.
Here is an example.
$ echo ABCDEF | teip -og .
[A][B][C][D][E][F]
$ echo ABCDEF | teip -og . -- grep '[ABC]'
ABC
teip: Output of given command is exhausted
$ echo $?
1
teip could not get the result corresponding to the hole of D, E, and F.
That is why the above example fails.
If an inconsistency occurs, teip will exit with the error message.
Also, the exit status will be 1.
To learn more about teip's behavior, see Wiki > Chunking.
Advanced usage
Solid mode (-s)
If you want to use a command that does not satisfy the condition, "A targeted command must print a single line of result for each line of input", enable "Solid mode" which is available with the -s option.
Solid mode spawns the targeted command for each hole and executes it each time.
$ echo ABCDEF | teip -s -og . -- grep '[ABC]'
In the above example, understand the following commands are executed in teip's internal procedure.
$ echo A | grep '[ABC]' # => A
$ echo B | grep '[ABC]' # => B
$ echo C | grep '[ABC]' # => C
$ echo D | grep '[ABC]' # => Empty
$ echo E | grep '[ABC]' # => Empty
$ echo F | grep '[ABC]' # => Empty
The empty result is replaced with an empty string. Therefore, D, E, and F are replaced with empty as expected.
$ echo ABCDEF | teip -s -og . -- grep '[ABC]'
ABC
$ echo $?
0
However, this option is not suitable for processing large files because of its high processing overhead, which can significantly degrade performance.
Solid mode with --chomp
If -s option does not work as expected, --chomp may be helpful.
A targeted command in solid mode always accepts input with a line field (\x0A) at the end.
This is because teip assumes the use of commands that return a single line of result in response to a single line of input.
Therefore, even if there is no line break in the hole, a line break is given to treat it as a single line of input.
However, there are situations where this behavior is inconvenient. For example, when using commands whose behavior changes depending on the presence or absence of line field.
$ echo AAABBBCCC | teip -og BBB -s
AAA[BBB]CCC
$ echo AAABBBCCC | teip -og BBB -s -- tr '\n' '@'
AAABBB@CCC
The above is an example where the targeted command is a "tr command that converts line field (\x0A) to @".
"BBB" does not contain a newline, but the result is "BBB@", because implicitly added line breaks have been processed.
To prevent this behavior, use the --chomp option.
This option gives the targeted command pure input with no newlines added.
$ echo AAABBBCCC | teip -og BBB -s --chomp -- tr '\n' '@'
AAABBBCCC
For example, it is useful when using commands that interpret and process input as binary like tr.
Below is an example of "removing newlines from the second column of a CSV that contains newlines.
$ cat tests/sample.csv
Name,Address,zipcode
Sola Harewatar,"Doreami Road 123
Sorashido city",12877
The result is.
$ cat tests/sample.csv | teip --csv -f 2 -s --chomp -- tr '\n' '@'
Name,Address,zipcode
Sola Harewatar,"Doreami Road 123@Sorashido city",12877
Line number (-l)
You can specify a line number and drill holes only in that line.
$ echo -e "ABC\nDEF\nGHI" | teip -l 2
ABC
[DEF]
GHI
$ echo -e "ABC\nDEF\nGHI" | teip -l 1,3
[ABC]
DEF
[GHI]
Overlay teips
Any command can be used with teip, surprisingly, even if it is teip itself.
$ echo "AAA@@@@@AAA@@@@@AAA" | teip -og '@.*@'
AAA[@@@@@AAA@@@@@]AAA
$ echo "AAA@@@@@AAA@@@@@AAA" | teip -og '@.*@' -- teip -og 'A+'
AAA@@@@@[AAA]@@@@@AAA
$ echo "AAA@@@@@AAA@@@@@AAA" | teip -og '@.*@' -- teip -og 'A+' -- tr A _
AAA@@@@@___@@@@@AAA
In other words, by connecting multiple functions of teip with AND conditions, it is possible to drill holes in a more complex range.
Furthermore, it works asynchronously and in multi-processes, similar to the shell pipeline.
It will hardly degrade performance unless the machine faces the limits of parallelism.
Oniguruma regular expressior (-G)
If -G option is given together with -g, the regular expressin is interpreted as Oniguruma regular expression. For example, "keep" and "look-ahead" syntax can be used.
$ echo 'ABC123DEF456' | teip -G -og 'DEF\K\d+'
ABC123DEF[456]
$ echo 'ABC123DEF456' | teip -G -og '\d+(?=D)'
ABC[123]DEF456
Empty hole
If a blank field exists when the -f option is used, the blank is not ignored and treated as an empty hole.
$ echo ',,,' | teip -d , -f 1-
[],[],[],[]
Therefore, the following command can work (Note that * matches empty as well).
$ echo ',,,' | teip -f 1- -d, sed 's/.*/@@@/'
@@@,@@@,@@@,@@@
In the above example, the sed loads four newline characters and prints @@@ four times.
Invert match (-v)
The -v option allows you to invert the range of holes.
When the -f or -c option is used with -v, holes to be made in the complement of the specified field instead.
$ echo 1 2 3 4 5 | teip -v -f 1,3,5 -- sed 's/./_/'
1 _ 3 _ 5
Of course, it can also be used for the -og option.
$ printf 'AAA\n123\nBBB\n' | teip -vg '\d+' -- sed 's/./@/g'
@@@
123
@@@
Zero-terminated mode (-z)
If you want to process the data in a more flexible way, the -z option may be useful.
This option allows you to use the NUL character (the ASCII NUL character) instead of the newline character.
It behaves like -z provided by GNU sed or GNU grep, or -0 option provided by xargs.
$ printf '111,\n222,33\n3\0\n444,55\n5,666\n' | teip -z -f3 -d,
111,
222,[33
3]
444,55
5,[666]
With this option, the standard input is interpreted per a NUL character rather than per a newline character.
You should also pay attention to that strings in the hole are concatenated with the NUL character instead of a newline character in teip's procedure.
In other words, if you use a targeted command that cannot handle NUL characters (and cannot print NUL-separated results), the final result can be unintended.
$ printf '111,\n222,33\n3\0\n444,55\n5,666\n' | teip -z -f3 -d, -- sed -z 's/.*/@@@/g'
111,
222,@@@
444,55
5,@@@
$ printf '111,\n222,33\n3\0\n444,55\n5,666\n' | teip -z -f3 -d, -- sed 's/.*/@@@/g'
111,
222,@@@
@@@
444,55
5,teip: Output of given command is exhausted
Specifying from one line to another is a typical use case for this option.
$ cat test.html | teip -z -og '<body>.*</body>'
<html>
<head>
<title>AAA</title>
</head>
[<body>
<div>AAA</div>
<div>BBB</div>
<div>CCC</div>
</body>]
</html>
$ cat test.html | teip -z -og '<body>.*</body>' -- grep -a BBB
<html>
<head>
<title>AAA</title>
</head>
<div>BBB</div>
</html>
External execution for match offloading (-e)
-e is the option to use external commands for pattern matching.
Until the above, you had to use teip's own functions, such as -c or -g, to control the position of the holes on the masking tape.
With -e, however, you can use the external commands you are familiar with to specify the range of holes.
-e allows you to specify the shell pipeline as a string.
On UNIX-like OS, this pipeline is executed in /bin/sh, on Windows in cmd.exe.
For example, with a pipeline echo 3 that outputs 3, then only the third line will be bypassed.
$ echo -e 'AAA\nBBB\nCCC' | teip -e 'echo 3'
AAA
BBB
[CCC]
It works even if the output is somewhat 'dirty'. For example, if any spaces or tab characters are included at the beginning of a line, they are ignored. Also, once a number is given, it does not matter if there are non-numerical characters to the right of the number.
$ echo -e 'AAA\nBBB\nCCC' | teip -e 'echo " 3"'
AAA
BBB
[CCC]
$ echo -e 'AAA\nBBB\nCCC' | teip -e 'echo " 3:testtest"'
AAA
BBB
[CCC]
Technically, the first captured group in the regular expression ^\s*([0-9]+) is interpreted as a line number.
-e will also recognize multiple numbers if the pipeline provides multiple lines of numbers.
For example, the seq command to display only odd numbers up to 10 is.
$ seq 1 2 10
1
3
5
7
9
This means that only odd-numbered rows can be bypassed by specifying the following.
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'seq 1 2 10' -- sed 's/. /@/g'
@@@
BBB
@@@
DDD
@@@
FFF
Note that the order of the numbers must be in ascending order.
Now, on its own, this looks like a feature that is just a slight development of the -l option.
However, the breakthrough of this feature is that the pipeline obtains identical standard input as teip.
Thus, it can output any number using not only seq and echo, but also commands such as grep, sed, and awk, which process the standard input.
Let's look at a more concrete example.
The following command is a grep command that prints the line numbers of the line containing the string "CCC" and the two lines after it.
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | grep -n -A 2 CCC
3:CCC
4-DDD
5-EEE
If you give this command to -e, you can punch holes in the line containing the string "CCC" and the two lines after it!
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'grep -n -A 2 CCC'
AAA
BBB
[CCC]
[DDD]
[EEE]
FFF
grep is not the only one.
GNU sed has =, which prints the line number being processed.
Below is an example of how to drill from the line containing "BBB" to the line containing "EEE".
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'sed -n "/BBB/,/EEE/="'
AAA
[BBB]
[CCC]
[DDD]
[EEE]
FFF
Of course, similar operations can also be done with awk.
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'awk "/BBB/,/EEE/{print NR}"'
The following is an example of combining the commands nl and tail.
You can only make holes in the last three lines of input!
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'nl -ba | tail -n 3'
AAA
BBB
CCC
[DDD]
[EEE]
[FFF]
The -e argument is a single string.
Therefore, pipe | and other symbols can be used as it is.
Alias options (-A, -B, -C, --awk, --sed)
There are several experimental options which are alias of -e and specific string.
These options may be discontinued in the future since they are just experimental ones.
Do not use them in the script or something that is not a one-off.
-A <number>
This is an alias of -e 'grep -n -A <number> <pattern>'.
If it is used together with -g <pattern> option, it makes holes in row matching <pattern> and <number> rows after the row.
$ cat AtoG.txt | teip -g B -A 2
A
[B]
[C]
[D]
E
F
G
-B <number>
This is an alias of -e 'grep -n -B <number> <pattern>'
If it is used together with -g <pattern> option, it makes holes in row matching <pattern> and <number> rows before the row.
$ cat AtoG.txt | teip -g E -B 2
A
B
[C]
[D]
[E]
F
G
-C <number>
This is an alias of -e 'grep -n -C <number> <pattern>'.
If it is used together with -g <pattern> option, it makes holes in row matching <pattern> and <number> rows before and after the row.
$ cat AtoG.txt | teip -g E -C 2
A
B
[C]
[D]
[E]
[F]
[G]
--sed <pattern>
This is an alias of -e 'sed -n "<pattern>=".
$ cat AtoG.txt | teip --sed '/B/,/E/'
A
[B]
[C]
[D]
[E]
F
G
$ cat AtoG.txt | teip --sed '1~3'
[A]
B
C
[D]
E
F
[G]
--awk <pattern>
This is an alias of -e 'awk "<pattern>{print NR}".
$ cat AtoG.txt | teip --awk '/B/,/E/'
A
[B]
[C]
[D]
[E]
F
G
$ cat AtoG.txt | teip --awk 'NR%3==0'
A
B
[C]
D
E
[F]
G
Environment variables
teip refers to the following environment variables.
Add the statement to your default shell's startup file (i.e .bashrc, .zshrc) to change them as you like.
TEIP_HIGHLIGHT
DEFAULT VALUE: \x1b[36m[\x1b[0m\x1b[01;31m{}\x1b[0m\x1b[36m]\x1b[0m
The default format for highlighting hole.
It must include at least one {} as a placeholder.
Example:
$ export TEIP_HIGHLIGHT="<<<{}>>>"
$ echo ABAB | teip -og A
<<<A>>>B<<<A>>>B
$ export TEIP_HIGHLIGHT=$'\x1b[01;31m{}\x1b[0m'
$ echo ABAB | teip -og A
ABAB ### Same color as grep
ANSI Escape Sequences and ANSI-C Quoting are helpful to customize this value.
TEIP_GREP_PATH
DEFAULT VALUE: grep
The path to grep command used by -A, -B, -C options.
For example, if you want to use ggrep instead of grep, set this variable to ggrep.
$ export TEIP_GREP_PATH=/opt/homebrew/bin/ggrep
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -g CCC -A 2
AAA
BBB
[CCC]
[DDD]
[EEE]
FFF
TEIP_SED_PATH
DEFAULT VALUE: sed
The path to sed command used by --sed option.
For example, if you want to use gsed instead of sed, set this variable to gsed.
TEIP_AWK_PATH
DEFAULT VALUE: awk
The path to awk command used by --awk option.
For example, if you want to use gawk instead of awk, set this variable to gawk.
Background
Why made it?
See this post.
Why "teip"?
- tee + in-place.
- And it sounds similar to Masking-"tape".
License
Modules imported/referenced from other repositories
Thank you so much for helpful modules!
-
./src/list/ranges.rs
- One of the module used in
cutcommand of uutils/coreutils - Original souce codes are distributed under MIT license
- The license file is on the same directory
- One of the module used in
-
./src/csv/parser.rs
- Many parts of the source code are referenced from BurntSushi/rust-csv.
- Original source codes are distributed under dual-licensed under MIT and Unlicense
Source code
The scripts are available as open source under the terms of the MIT License.
Logo
![]()
The logo of teip is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
Dependencies
~5–14MB
~158K SLoC