57 releases (19 breaking)
Uses new Rust 2024
| 0.26.0 | May 6, 2025 |
|---|---|
| 0.24.0 | Apr 11, 2025 |
| 0.22.7 | Mar 30, 2025 |
| 0.15.0 | Dec 24, 2024 |
| 0.7.0 | Jul 28, 2024 |
#1928 in Asynchronous
711 downloads per month
Used in 5 crates
(via swiftide)
220KB
5K
SLoC
Table of Contents
![]()
![]()
![]()
![]()
Swiftide
Fast, streaming indexing, query, and agentic LLM applications in Rust
Read more on swiftide.rs »
API Docs
·
Report Bug
·
Request Feature
·
Discord
What is Swiftide?
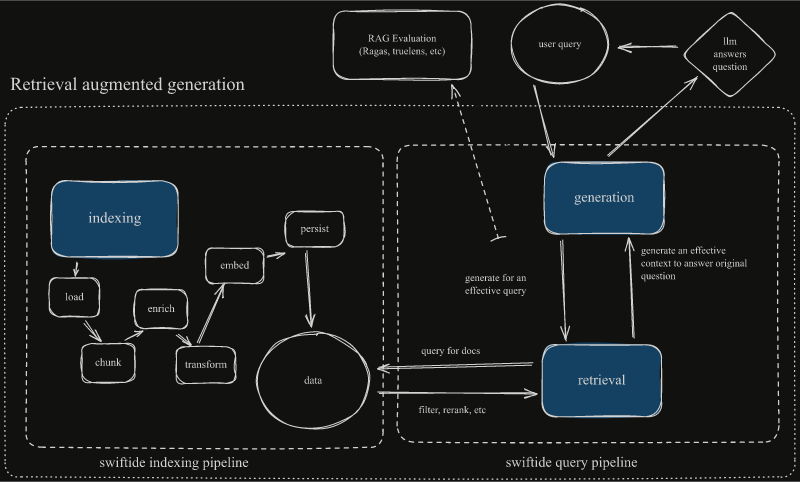
Swiftide is a Rust library for building LLM applications, enabling fast data ingestion, transformation, and indexing for effective querying and prompt injection, known as Retrieval Augmented Generation. It provides flexible building blocks for creating various agents, allowing rapid development from concept to production with minimal code.
High level features
- Build fast, streaming indexing and querying pipelines
- Easily build agents, mix and match with previously built pipelines
- A modular and extendable API, with minimal abstractions
- Integrations with popular LLMs and storage providers
- Ready to use pipeline transformations
Part of the bosun.ai project. An upcoming platform for autonomous code improvement.
We <3 feedback: project ideas, suggestions, and complaints are very welcome. Feel free to open an issue or contact us on discord.
[!CAUTION] Swiftide is under heavy development and can have breaking changes. Documentation might fall short of all features, and despite our efforts be slightly outdated. We recommend to always keep an eye on our github and api documentation. If you found an issue or have any kind of feedback we'd love to hear from you.
Latest updates on our blog 🔥
-
Evaluate Swiftide pipelines with Ragas (2024-09-15)
-
Release - Swiftide 0.12 (2024-09-13)
-
Local code intel with Ollama, FastEmbed and OpenTelemetry (2024-09-04
-
Release - Swiftide 0.9 (2024-09-02)
-
Bring your own transformers (2024-08-13)
-
Release - Swiftide 0.8 (2024-08-12)
-
Release - Swiftide 0.7 (2024-07-28)
-
Building a code question answering pipeline (2024-07-13)
-
Release - Swiftide 0.6 (2024-07-12)
-
Release - Swiftide 0.5 (2024-07-1)
Examples
Indexing a local code project, chunking into smaller pieces, enriching the nodes with metadata, and persisting into Qdrant:
indexing::Pipeline::from_loader(FileLoader::new(".").with_extensions(&["rs"]))
.with_default_llm_client(openai_client.clone())
.filter_cached(Redis::try_from_url(
redis_url,
"swiftide-examples",
)?)
.then_chunk(ChunkCode::try_for_language_and_chunk_size(
"rust",
10..2048,
)?)
.then(MetadataQACode::default())
.then(move |node| my_own_thing(node))
.then_in_batch(Embed::new(openai_client.clone()))
.then_store_with(
Qdrant::builder()
.batch_size(50)
.vector_size(1536)
.build()?,
)
.run()
.await?;
Querying for an example on how to use the query pipeline:
query::Pipeline::default()
.then_transform_query(GenerateSubquestions::from_client(
openai_client.clone(),
))
.then_transform_query(Embed::from_client(
openai_client.clone(),
))
.then_retrieve(qdrant.clone())
.then_answer(Simple::from_client(openai_client.clone()))
.query("How can I use the query pipeline in Swiftide?")
.await?;
Running an agent that can search code:
#[swiftide::tool(
description = "Searches code",
param(name = "code_query", description = "The code query")
)]
async fn search_code(
context: &dyn AgentContext,
code_query: &str,
) -> Result<ToolOutput, ToolError> {
let command_output = context
.exec_cmd(&Command::shell(format!("rg '{code_query}'")))
.await?;
Ok(command_output.into())
}
agents::Agent::builder()
.llm(&openai)
.tools(vec![search_code()])
.build()?
.query("In what file can I find an example of a swiftide agent?")
.await?;
You can find more detailed examples in /examples
Vision
Our goal is to create a fast, extendable platform for building LLM applications in Rust, to further the development of automated AI applications, with an easy-to-use and easy-to-extend api.
Features
- Fast, modular streaming indexing pipeline with async, parallel processing
- Experimental query pipeline
- Experimental agent framework
- A variety of loaders, transformers, semantic chunkers, embedders, and more
- Bring your own transformers by extending straightforward traits or use a closure
- Splitting and merging pipelines
- Jinja-like templating for prompts
- Store into multiple backends
- Integrations with OpenAI, Groq, Redis, Qdrant, Ollama, FastEmbed-rs, Fluvio, LanceDB, and Treesitter
- Evaluate pipelines with RAGAS
- Sparse vector support for hybrid search
tracingsupported for logging and tracing, see /examples and thetracingcrate for more information.
In detail
| Feature | Details |
|---|---|
| Supported Large Language Model providers | OpenAI (and Azure) - All models and embeddings Anthropic OpenRouter AWS Bedrock - Anthropic and Titan Groq - All models Ollama - All models |
| Loading data | Files Scraping Fluvio Parquet Other pipelines and streams |
| Transformers and metadata generation | Generate Question and answerers for both text and code (Hyde) Summaries, titles and queries via an LLM Extract definitions and references with tree-sitter |
| Splitting and chunking | Markdown Text (text_splitter) Code (with tree-sitter) |
| Storage | Qdrant Redis LanceDB |
| Query pipeline | Similarity and hybrid search, query and response transformations, and evaluation |
Getting Started
Prerequisites
Make sure you have the rust toolchain installed. rustup Is the recommended approach.
To use OpenAI, an API key is required. Note that by default async_openai uses the OPENAI_API_KEY environment variables.
Other integrations might have their own requirements.
Installation
-
Set up a new Rust project
-
Add swiftide
cargo add swiftide -
Enable the features of integrations you would like to use in your
Cargo.toml -
Write a pipeline (see our examples and documentation)
Usage and concepts
Before building your streams, you need to enable and configure any integrations required. See /examples.
We have a lot of examples, please refer to /examples and the Documentation
[!NOTE] No integrations are enabled by default as some are code heavy. We recommend you to cherry-pick the integrations you need. By convention flags have the same name as the integration they represent.
Indexing
An indexing stream starts with a Loader that emits Nodes. For instance, with the Fileloader each file is a Node.
You can then slice and dice, augment, and filter nodes. Each different kind of step in the pipeline requires different traits. This enables extension.
Nodes have a path, chunk and metadata. Currently metadata is copied over when chunking and always embedded when using the OpenAIEmbed transformer.
- from_loader
(impl Loader)starting point of the stream, creates and emits Nodes - filter_cached
(impl NodeCache)filters cached nodes - then
(impl Transformer)transforms the node and puts it on the stream - then_in_batch
(impl BatchTransformer)transforms multiple nodes and puts them on the stream - then_chunk
(impl ChunkerTransformer)transforms a single node and emits multiple nodes - then_store_with
(impl Storage)stores the nodes in a storage backend, this can be chained
Additionally, several generic transformers are implemented. They take implementers of SimplePrompt and EmbedModel to do their things.
[!WARNING] Due to the performance, chunking before adding metadata gives rate limit errors on OpenAI very fast, especially with faster models like 3.5-turbo. Be aware.
Querying
A query stream starts with a search strategy. In the query pipeline a Query goes through several stages. Transformers and retrievers work together to get the right context into a prompt, before generating an answer. Transformers and Retrievers operate on different stages of the Query via a generic statemachine. Additionally, the search strategy is generic over the pipeline and Retrievers need to implement specifically for each strategy.
That sounds like a lot but, tl&dr; the query pipeline is fully and strongly typed.
- Pending The query has not been executed, and can be further transformed with transformers
- Retrieved Documents have been retrieved, and can be further transformed to provide context for an answer
- Answered The query is done
Additionally, query pipelines can also be evaluated. I.e. by Ragas.
Similar to the indexing pipeline each step is governed by simple Traits and closures implement these traits as well.
Contributing
Swiftide is in a very early stage and we are aware that we lack features for the wider community. Contributions are very welcome. 🎉
If you have a great idea, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement". Don't forget to give the project a star! Thanks again!
If you just want to contribute (bless you!), see our issues or join us on Discord.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'feat: Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
See CONTRIBUTING for more
Core Team Members

timonv open for swiftide consulting |

tinco |
License
Distributed under the MIT License. See LICENSE for more information.
Dependencies
~12–22MB
~311K SLoC