3 unstable releases
| 0.5.0 | Jan 12, 2023 |
|---|---|
| 0.3.2 | Nov 29, 2022 |
| 0.3.1 | Nov 29, 2022 |
#22 in #tantivy
21 downloads per month
Used in 6 crates
(2 directly)
13KB
286 lines
![]()
![]()
![]()
![]()
![]()
Fast full-text search engine library written in Rust
If you are looking for an alternative to Elasticsearch or Apache Solr, check out Quickwit, our distributed search engine built on top of Tantivy.
Tantivy is closer to Apache Lucene than to Elasticsearch or Apache Solr in the sense it is not an off-the-shelf search engine server, but rather a crate that can be used to build such a search engine.
Tantivy is, in fact, strongly inspired by Lucene's design.
Benchmark
The following benchmark breaks down the performance for different types of queries/collections.
Your mileage WILL vary depending on the nature of queries and their load.
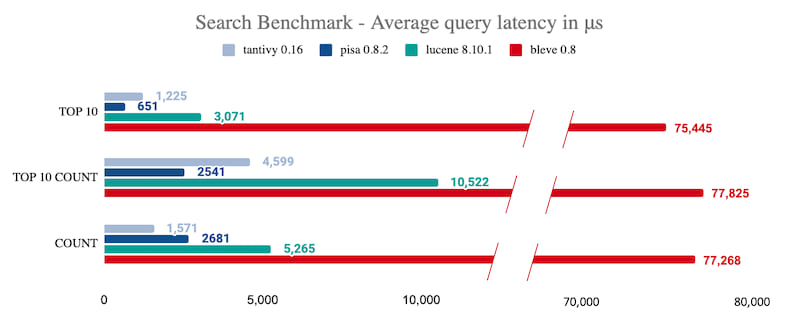
Details about the benchmark can be found at this repository.
Features
- Full-text search
- Configurable tokenizer (stemming available for 17 Latin languages) with third party support for Chinese (tantivy-jieba and cang-jie), Japanese (lindera, Vaporetto, and tantivy-tokenizer-tiny-segmenter) and Korean (lindera + lindera-ko-dic-builder)
- Fast (check out the 🐎 ✨ benchmark ✨ 🐎)
- Tiny startup time (<10ms), perfect for command-line tools
- BM25 scoring (the same as Lucene)
- Natural query language (e.g.
(michael AND jackson) OR "king of pop") - Phrase queries search (e.g.
"michael jackson") - Incremental indexing
- Multithreaded indexing (indexing English Wikipedia takes < 3 minutes on my desktop)
- Mmap directory
- SIMD integer compression when the platform/CPU includes the SSE2 instruction set
- Single valued and multivalued u64, i64, and f64 fast fields (equivalent of doc values in Lucene)
&[u8]fast fields- Text, i64, u64, f64, dates, ip, bool, and hierarchical facet fields
- Compressed document store (LZ4, Zstd, None)
- Range queries
- Faceted search
- Configurable indexing (optional term frequency and position indexing)
- JSON Field
- Aggregation Collector: histogram, range buckets, average, and stats metrics
- LogMergePolicy with deletes
- Searcher Warmer API
- Cheesy logo with a horse
Non-features
Distributed search is out of the scope of Tantivy, but if you are looking for this feature, check out Quickwit.
Getting started
Tantivy works on stable Rust and supports Linux, macOS, and Windows.
- Tantivy's simple search example
- tantivy-cli and its tutorial -
tantivy-cliis an actual command-line interface that makes it easy for you to create a search engine, index documents, and search via the CLI or a small server with a REST API. It walks you through getting a Wikipedia search engine up and running in a few minutes. - Reference doc for the last released version
How can I support this project?
There are many ways to support this project.
- Use Tantivy and tell us about your experience on Discord or by email (paul.masurel@gmail.com)
- Report bugs
- Write a blog post
- Help with documentation by asking questions or submitting PRs
- Contribute code (you can join our Discord server)
- Talk about Tantivy around you
Contributing code
We use the GitHub Pull Request workflow: reference a GitHub ticket and/or include a comprehensive commit message when opening a PR. Feel free to update CHANGELOG.md with your contribution.
Tokenizer
When implementing a tokenizer for tantivy depend on the tantivy-tokenizer-api crate.
Clone and build locally
Tantivy compiles on stable Rust. To check out and run tests, you can simply run:
git clone https://github.com/quickwit-oss/tantivy.git
cd tantivy
cargo test
Companies Using Tantivy
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
FAQ
Can I use Tantivy in other languages?
- Python → tantivy-py
- Ruby → tantiny
You can also find other bindings on GitHub but they may be less maintained.
What are some examples of Tantivy use?
- seshat: A matrix message database/indexer
- tantiny: Tiny full-text search for Ruby
- lnx: adaptable, typo tolerant search engine with a REST API
- and more!
On average, how much faster is Tantivy compared to Lucene?
- According to our search latency benchmark, Tantivy is approximately 2x faster than Lucene.
Does tantivy support incremental indexing?
- Yes.
How can I edit documents?
- Data in tantivy is immutable. To edit a document, the document needs to be deleted and reindexed.
When will my documents be searchable during indexing?
- Documents will be searchable after a
commitis called on anIndexWriter. ExistingIndexReaders will also need to be reloaded in order to reflect the changes. Finally, changes are only visible to newly acquiredSearcher.
Dependencies
~9KB