19 releases (stable)
| 2.0.0-beta.2 | Mar 5, 2023 |
|---|---|
| 1.6.0 | Jan 30, 2023 |
| 1.5.0 | Jun 1, 2022 |
| 1.4.2 | Mar 23, 2022 |
| 0.7.2 | Jun 19, 2020 |
#187 in WebAssembly
32 downloads per month
200KB
5K
SLoC
Stork
|
Project update: I'm winding down my work with Stork. Thanks to everyone who enjoyed using Stork over the past few years! |
Impossibly fast web search, made for static sites.
Stork is a library for creating beautiful, fast, and accurate full-text search interfaces on the web.
It comes in two parts. First, it's a command-line tool that indexes content and creates a search index file that you can upload to a web server. Second, it's a Javascript library that uses that index file to build an interactive search interface that displays optimal search results immediately to your user, as they type.
Stork is built with Rust, and the Javascript library uses WebAssembly behind the scenes. It's easy to get started and is even easier to customize so it fits your needs. It's perfect for Jamstack sites and personal blogs, but can be used wherever you need an interactive search bar.
Currently in development by James Little
Getting Started
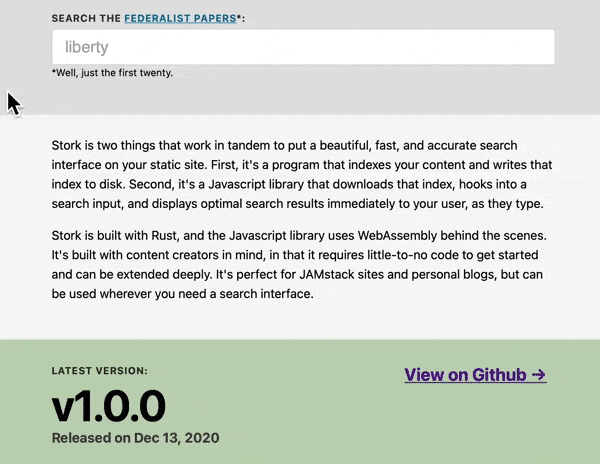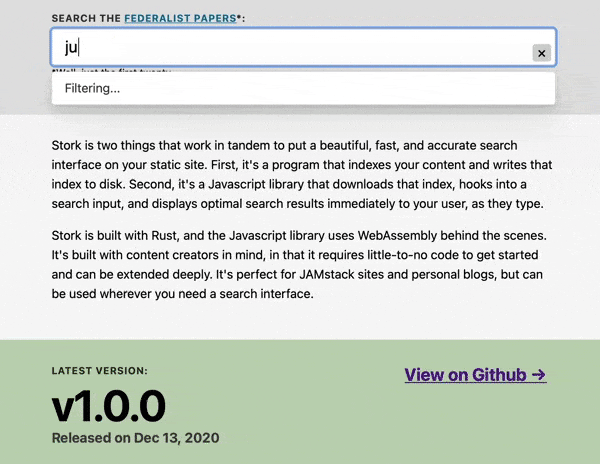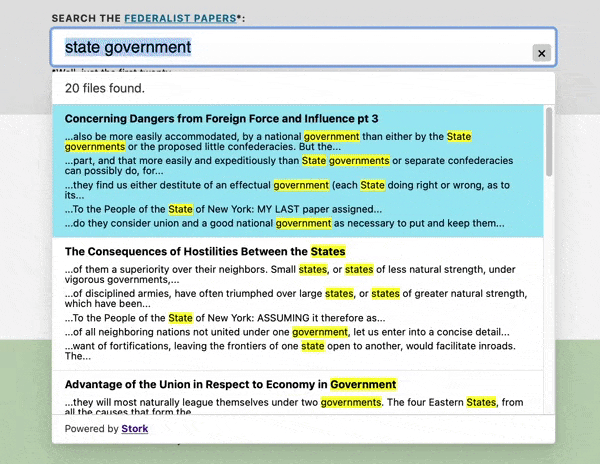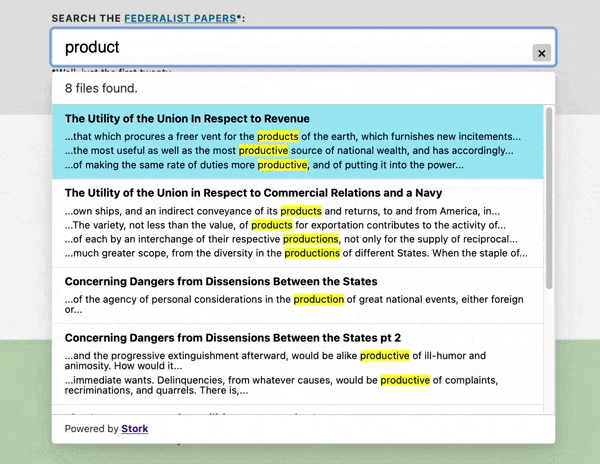
Let's put a search box online that searches within the text of the Federalist Papers.
See this demo live at https://stork-search.net.
<!DOCTYPE html>
<html lang="en">
<head>
<title>Federalist Search</title>
</head>
<body>
<div class="stork-wrapper">
<input data-stork="federalist" class="stork-input" />
<div data-stork="federalist-output" class="stork-output"></div>
</div>
<script src="https://files.stork-search.net/stork.js"></script>
<script>
stork.register(
"federalist",
"http://files.stork-search.net/federalist.st"
);
</script>
</body>
</html>
Step 1: Include the HTML
Stork hooks into existing HTML that you include on your page. Each Stork instance has to have an input hook and a results list; those two elements should be placed in a wrapper, though the wrapper is optional.
The input hook should have the data-stork="federalist" attribute, where federalist is the name with which you register that search instance. (This way, you can have multiple, independent search boxes on a page, all pointing to different instances.) It doesn't have to be federalist -- you can change it to whatever you want.
The results list should be an empty <div> tag with the attribute data-stork="federalist-results". Again, here, you can change federalist to whatever you want.
The classes in the example above (stork-input, stork-output) are for the theme. Most Stork themes assume the format above; the theme documentation will tell you if it requires something different. You can also design your own theme, at which point the styling and class names are up to you.
Step 2: Include the Javascript
You need to include stork.js, which you can either load from the Stork CDN or host yourself. This will load the Stork WebAssembly blob and create the Stork object, which will allow for registering and configuring indices.
Then, you should register at least one index:
stork.register("federalist", "http://files.stork-search.net/federalist.st");
The search index you build needs to be stored somewhere with a public URL. To register
This registers the index stored at http://files.stork-search.net/federalist.st under the name federalist; the data-stork attributes in the HTML will hook into this name.
Finally, you can set some configuration options for how your search bar will interact with the index and with the page.
Building your own index
You probably don't want to add an interface to your own website that lets you search through the Federalist papers. Here's how to make your search bar yours.
To build an index, you need the Stork executable on your computer, which you can install at the latest Github release or by running cargo install stork-search --locked if you have a Rust toolchain installed.
The search index is based on a document structure: you give Stork a list of documents on disk and include some metadata about those documents, and Stork will build its search index based on the contents of those documents.
First, you need a configuration file that describes, among other things, that list of files:
[input]
base_directory = "test/federalist"
files = [
{path = "federalist-1.txt", url = "/federalist-1/", title = "Introduction"},
{path = "federalist-2.txt", url = "/federalist-2/", title = "Concerning Dangers from Foreign Force and Influence"},
{path = "federalist-3.txt", url = "/federalist-3/", title = "Concerning Dangers from Foreign Force and Influence 2"},
{path = "federalist-4.txt", url = "/federalist-4/", title = "Concerning Dangers from Foreign Force and Influence 3"},
{path = "federalist-5.txt", url = "/federalist-5/", title = "Concerning Dangers from Foreign Force and Influence 4"},
{path = "federalist-6.txt", url = "/federalist-6/", title = "Concerning Dangers from Dissensions Between the States"},
{path = "federalist-7.txt", url = "/federalist-7/", title = "Concerning Dangers from Dissensions Between the States 2"},
{path = "federalist-8.txt", url = "/federalist-8/", title = "The Consequences of Hostilities Between the States"},
{path = "federalist-9.txt", url = "/federalist-9/", title = "The Union as a Safeguard Against Domestic Faction and Insurrection"},
{path = "federalist-10.txt", url = "/federalist-10/", title = "The Union as a Safeguard Against Domestic Faction and Insurrection 2"}
]
This TOML file describes the base directory of all your documents, then lists out each document along with the web URL at which that document will be found, along with that document's title.
From there, you can build your search index by running:
$ stork build --input federalist.toml --output federalist.st
This will create a new file at federalist.st. You can search through it with the same command line tool:
$ stork search --index federalist.st --query "liberty"
To embed a Stork search interface on your website, first upload the index file to your web server, then pass its URL to the stork.register() function in your web page's Javascript.
Going further
You can read more documentation and learn more about customization at the project's website: https://stork-search.net.
Development
To build Stork, you'll need:
- Rust, using the stable toolchain
- wasm-pack
- yarn
- Just if you want to use the same build scripts I do (otherwise you can read the Justfile and run the scripts manually)
The repository is structured like a typical Cargo workspace, with some modifications.
- The
stork-*directories hold Rust packages.stork-cliandstork-wasmare the top-level packages; everything else is a dependency. jsholds the Javascript source code.test-assetsholds binary assets required by Stork's functional tests.local-devholds configuration files, corpora, and index files required to build and run the test webpage used for local development.
You can build the project using either the Rust entrypoint or the Javascript entrypoint (build instructions are listed below). After you've built the project, you'll see three more directories:
targetholds the output binary build artifactspkgholds intermediate WASM build artifactsdistholds the final build artifacts for the web.
If you're interested in extracting the final Stork build artifacts, you can extract the following files after building the project with yarn build:
/target/release/stork/dist/stork.js/dist/stork.wasm
Building the project for production
just build-indexerwill build the indexer binary totarget/release/storkjust build-jswill build the WASM binary and the Javascript bridging code to thedistdirectoryjust build-federalist-indexwill build the federalist.st index file that's referenced throughout the project. It will output tolocal-dev/test-indexes/federalist.st.
Building the project for development
just build-indexer-devwill build the indexer binarycargo run -- <CLI OPTIONS>will run the indexer binaryjust build-dev-sitewill build the WASM and Javascript bridge code, build the federalist.st index, and package the development site./scripts/serve.shwill serve the development site
Take a look at the project's Justfile for more available scripts.
Dependencies
~16–32MB
~479K SLoC