26 releases
Uses new Rust 2024
| 0.13.6 | Mar 23, 2025 |
|---|---|
| 0.13.4 | Nov 9, 2024 |
| 0.12.0 | Mar 25, 2024 |
| 0.10.0 | Dec 18, 2023 |
| 0.7.0 | Nov 6, 2023 |
#2 in #manipulation
41 downloads per month
3MB
55K
SLoC
srgn - a code surgeon
A grep-like tool which understands source code syntax and allows for manipulation in
addition to search.
Like grep, regular expressions are a core primitive. Unlike grep, additional
capabilities allow for higher precision, with options for manipulation. This
allows srgn to operate along dimensions regular expressions and IDE tooling (Rename
all, Find all references, ...) alone cannot, complementing them.
srgn is organized around actions to take (if any), acting only within precise,
optionally language grammar-aware scopes. In terms of existing tools, think of it
as a mix of
tr,
sed,
ripgrep and
tree-sitter, with a design goal of
simplicity: if you know regex and the basics of the language you are working with, you
are good to go.
The answer to "What if
grep,tr,sedandtree-sittergot really drunk one night and had a baby?"
Quick walkthrough
[!TIP]
All code snippets displayed here are verified as part of unit tests using the actual
srgnbinary. What is showcased here is guaranteed to work.
The most simple srgn usage works similar to tr:
$ echo 'Hello World!' | srgn '[wW]orld' 'there' # replacement
Hello there!
Matches for the regular expression pattern '[wW]orld' (the scope) are replaced (the
action) by the second positional argument. Zero or more actions can be specified:
$ echo 'Hello World!' | srgn '[wW]orld' # zero actions: input returned unchanged
Hello World!
$ echo 'Hello World!' | srgn --upper '[wW]orld' 'you' # two actions: replacement, afterwards uppercasing
Hello YOU!
Replacement is always performed first and specified positionally. Any other actions are applied after and given as command line flags.
Multiple scopes
Similarly, more than one scope can be specified: in addition to the regex pattern, a
language grammar-aware scope can be
given, which scopes to syntactical elements of source code (think, for example, "all
bodies of class definitions in Python"). If both are given, the regular expression
pattern is then only applied within that first, language scope. This enables
search and manipulation at precision not normally possible using plain regular
expressions, and serving a dimension different from tools such as Rename all in IDEs.
For example, consider this (pointless) Python source file:
"""Module for watching birds and their age."""
from dataclasses import dataclass
@dataclass
class Bird:
"""A bird!"""
name: str
age: int
def celebrate_birthday(self):
print("🎉")
self.age += 1
@classmethod
def from_egg(egg):
"""Create a bird from an egg."""
pass # No bird here yet!
def register_bird(bird: Bird, db: Db) -> None:
assert bird.age >= 0
with db.tx() as tx:
tx.insert(bird)
which can be searched using:
$ cat birds.py | srgn --python 'class' 'age'
11: age: int
15: self.age += 1
The string age was sought and found only within Python class definitions (and not,
for example, in function bodies such as register_bird, where age also occurs and
would be nigh impossible to exclude from consideration in vanilla grep). By default,
this 'search mode' also prints line numbers. Search mode is entered if no actions are
specified, and a language such as --python is given[^3]—think of it like
'ripgrep but with syntactical language
elements'.
Searching can also be performed across
lines, for example to
find methods (aka def within class) lacking docstrings:
$ cat birds.py | srgn --python 'class' 'def .+:\n\s+[^"\s]{3}' # do not try this pattern at home
13: def celebrate_birthday(self):
14: print("🎉")
Note how this does not surface either from_egg (has a docstring) or register_bird
(not a method, def outside class).
Multiple language scopes
Language scopes themselves can be specified multiple times as well. For example, in the Rust snippet
pub enum Genre {
Rock(Subgenre),
Jazz,
}
const MOST_POPULAR_SUBGENRE: Subgenre = Subgenre::Something;
pub struct Musician {
name: String,
genres: Vec<Subgenre>,
}
multiple items can be surgically drilled down into as
$ cat music.rs | srgn --rust 'pub-enum' --rust 'type-identifier' 'Subgenre' # AND'ed together
2: Rock(Subgenre),
where only lines matching all criteria are returned, acting like a logical and
between all conditions. Note that conditions are evaluated left-to-right, precluding
some combinations from making sense: for example, searching for a Python class body
inside of Python doc-strings usually returns nothing. The inverse works as expected
however:
$ cat birds.py | srgn --py 'class' --py 'doc-strings'
8: """A bird!"""
19: """Create a bird from an egg."""
No docstrings outside class bodies are surfaced!
The -j flag changes this behavior: from intersecting left-to-right, to
running all queries independently and joining their results, allowing you to search
multiple ways at once:
$ cat birds.py | srgn -j --python 'comments' --python 'doc-strings' 'bird[^s]'
8: """A bird!"""
19: """Create a bird from an egg."""
20: pass # No bird here yet!
The pattern bird[^s] was found inside of comments or docstrings likewise, not just
"docstrings within comments".
Working recursively
If standard input is not given, srgn knows how to find relevant source files
automatically, for example in this repository:
$ srgn --python 'class' 'age'
docs/samples/birds
11: age: int
15: self.age += 1
docs/samples/birds.py
9: age: int
13: self.age += 1
It recursively walks its current directory, finding files based on file
extensions and shebang lines, processing
at very high speed. For example, srgn --go strings '\d+' finds and prints all ~140,000
runs of digits in literal Go strings inside the Kubernetes
codebase
of ~3,000,000 lines of Go code within 3 seconds on 12 cores of M3. For more on working
with many files, see below.
Combining actions and scopes
Scopes and actions can be combined almost arbitrarily (though many combinations are not going to be use- or even meaningful). For example, consider this Python snippet (for examples using other supported languages see below):
"""GNU module."""
def GNU_says_moo():
"""The GNU function -> say moo -> ✅"""
GNU = """
GNU
""" # the GNU...
print(GNU + " says moo") # ...says moo
against which the following command is run:
cat gnu.py | srgn --titlecase --python 'doc-strings' '(?<!The )GNU ([a-z]+)' '$1: GNU 🐂 is not Unix'
The anatomy of that invocation is:
-
--titlecase(an action) will Titlecase Everything Found In Scope -
--python 'doc-strings'(a scope) will scope to (i.e., only take into consideration) docstrings according to the Python language grammar -
'(?<!The )GNU ([a-z]+)'(a scope) sees only what was already scoped by the previous option, and will narrow it down further. It can never extend the previous scope. The regular expression scope is applied after any language scope(s).(?<!)is negative lookbehind syntax, demonstrating how this advanced feature is available. Strings ofGNUprefixed byThewill not be considered. -
'$1: GNU 🐂 is not Unix'(an action) will replace each matched occurrence (i.e., each input section found to be in scope) with this string. Matched occurrences are patterns of'(?<!The )GNU ([a-z]+)'only within Python docstrings. Notably, this replacement string demonstrates:- dynamic variable binding and substitution using
$1, which carries the contents captured by the first capturing regex group. That's([a-z]+), as(?<!The )is not capturing. - full Unicode support (🐂).
- dynamic variable binding and substitution using
The command makes use of multiple scopes (language and regex pattern) and multiple actions (replacement and titlecasing). The result then reads
"""Module: GNU 🐂 Is Not Unix."""
def GNU_says_moo():
"""The GNU function -> say moo -> ✅"""
GNU = """
GNU
""" # the GNU...
print(GNU + " says moo") # ...says moo
where the changes are limited to:
- """GNU module."""
+ """Module: GNU 🐂 Is Not Unix."""
def GNU_says_moo():
"""The GNU -> say moo -> ✅"""
[!WARNING]
While
srgnis in beta (major version 0), make sure to only (recursively) process files you can safely restore.Search mode does not overwrite files, so is always safe.
See below for the full help output of the tool.
[!NOTE]
Supported languages are
- C
- C#
- Go
- HCL (Terraform)
- Python
- Rust
- TypeScript
Installation
Prebuilt binaries
Download a prebuilt binary from the releases.
cargo-binstall
This crate provides its binaries in a format
compatible
with cargo-binstall:
- Install the Rust toolchain
- Run
cargo install cargo-binstall(might take a while) - Run
cargo binstall srgn(couple seconds, as it downloads prebuilt binaries from GitHub)
These steps are guaranteed to work™, as they are tested in CI. They also work if no prebuilt binaries are available for your platform, as the tool will fall back to compiling from source.
Homebrew
A formula is available via:
brew install srgn
Nix
Available via unstable:
nix-shell -p srgn
Arch Linux
Available via the AUR.
MacPorts
A port is available:
sudo port install srgn
CI (GitHub Actions)
All GitHub Actions runner
images come with cargo
preinstalled, and cargo-binstall provides a convenient GitHub
Action:
jobs:
srgn:
name: Install srgn in CI
# All three major OSes work
runs-on: ubuntu-latest
steps:
- uses: cargo-bins/cargo-binstall@main
- name: Install binary
run: >
cargo binstall
--no-confirm
srgn
- name: Use binary
run: srgn --version
The above concludes in just 5 seconds
total, as no
compilation is required. For more context, see cargo-binstall's advise on
CI.
Cargo (compile from source)
- Install the Rust toolchain
- A C compiler is required:
-
On Linux,
gccworks. -
On macOS, use
clang. -
On Windows, MSVC works.
Select "Desktop development with C++" on installation.
-
- Run
cargo install srgn
Cargo (as a Rust library)
cargo add srgn
See here for more.
Shell completions
Various
shells
are supported for shell completion scripts. For example, append eval "$(srgn --completions zsh)" to ~/.zshrc for completions in ZSH. An interactive session can
then look like:

Walkthrough
The tool is designed around scopes and actions. Scopes narrow down the parts of the input to process. Actions then perform the processing. Generally, both scopes and actions are composable, so more than one of each may be passed. Both are optional (but taking no action is pointless); specifying no scope implies the entire input is in scope.
At the same time, there is considerable overlap with plain
tr: the tool is designed to have close correspondence in the most common use
cases, and only go beyond when needed.
Actions
The simplest action is replacement. It is specially accessed (as an argument, not an
option) for compatibility with tr, and general ergonomics. All other actions are
given as flags, or options should they take a value.
Replacement
For example, simple, single-character replacements work as in tr:
$ echo 'Hello, World!' | srgn 'H' 'J'
Jello, World!
The first argument is the scope (literal H in this case). Anything matched by it is
subject to processing (replacement by J, the second argument, in this case). However,
there is no direct concept of character classes as in tr. Instead, by
default, the scope is a regular expression pattern, so its
classes can be used to
similar effect:
$ echo 'Hello, World!' | srgn '[a-z]' '_'
H____, W____!
The replacement occurs greedily across the entire match by default (note the UTS
character class,
reminiscent of tr's
[:alnum:]):
$ echo 'ghp_oHn0As3cr3T!!' | srgn 'ghp_[[:alnum:]]+' '*' # A GitHub token
*!!
Advanced regex features are supported, for example lookarounds:
$ echo 'ghp_oHn0As3cr3T' | srgn '(?<=ghp_)[[:alnum:]]+' '*'
ghp_*
Take care in using these safely, as advanced patterns come without certain safety and performance guarantees. If they aren't used, performance is not impacted.
The replacement is not limited to a single character. It can be any string, for example to fix this quote:
$ echo '"Using regex, I now have no issues."' | srgn 'no issues' '2 problems'
"Using regex, I now have 2 problems."
The tool is fully Unicode-aware, with useful support for certain advanced character classes:
$ echo 'Mood: 🙂' | srgn '🙂' '😀'
Mood: 😀
$ echo 'Mood: 🤮🤒🤧🦠 :(' | srgn '\p{Emoji_Presentation}' '😷'
Mood: 😷😷😷😷 :(
Variables
Replacements are aware of variables, which are made accessible for use through regex capture groups. Capture groups can be numbered, or optionally named. The zeroth capture group corresponds to the entire match.
$ echo 'Swap It' | srgn '(\w+) (\w+)' '$2 $1' # Regular, numbered
It Swap
$ echo 'Swap It' | srgn '(\w+) (\w+)' '$2 $1$1$1' # Use as many times as you'd like
It SwapSwapSwap
$ echo 'Call +1-206-555-0100!' | srgn 'Call (\+?\d\-\d{3}\-\d{3}\-\d{4}).+' 'The phone number in "$0" is: $1.' # Variable `0` is the entire match
The phone number in "Call +1-206-555-0100!" is: +1-206-555-0100.
A more advanced use case is, for example, code refactoring using named capture groups (perhaps you can come up with a more useful one...):
$ echo 'let x = 3;' | srgn 'let (?<var>[a-z]+) = (?<expr>.+);' 'const $var$var = $expr + $expr;'
const xx = 3 + 3;
As in bash, use curly braces to disambiguate variables from immediately adjacent content:
$ echo '12' | srgn '(\d)(\d)' '$2${1}1'
211
$ echo '12' | srgn '(\d)(\d)' '$2$11' # will fail (`11` is unknown)
$ echo '12' | srgn '(\d)(\d)' '$2${11' # will fail (brace was not closed)
Beyond replacement
Seeing how the replacement is merely a static string, its usefulness is limited. This is
where tr's secret sauce
ordinarily comes into play: using its character classes, which are valid in the second
position as well, neatly translating from members of the first to the second. Here,
those classes are instead regexes, and only valid in first position (the scope). A
regular expression being a state machine, it is impossible to match onto a 'list of
characters', which in tr is the second (optional) argument. That concept is out the
window, and its flexibility lost.
Instead, the offered actions, all of them fixed, are used. A peek at the most
common use cases for tr reveals that the provided set of
actions covers virtually all of them! Feel free to file an issue if your use case is not
covered.
Onto the next action.
Deletion
Removes whatever is found from the input. Same flag name as in tr.
$ echo 'Hello, World!' | srgn -d '(H|W|!)'
ello, orld
[!NOTE] As the default scope is to match the entire input, it is an error to specify deletion without a scope.
Squeezing
Squeezes repeats of characters matching the scope into single occurrences. Same flag
name as in tr.
$ echo 'Helloooo Woooorld!!!' | srgn -s '(o|!)'
Hello World!
If a character class is passed, all members of that class are squeezed into whatever class member was encountered first:
$ echo 'The number is: 3490834' | srgn -s '\d'
The number is: 3
Greediness in matching is not modified, so take care:
$ echo 'Winter is coming... 🌞🌞🌞' | srgn -s '🌞+'
Winter is coming... 🌞🌞🌞
[!NOTE] The pattern matched the entire run of suns, so there's nothing to squeeze. Summer prevails.
Invert greediness if the use case calls for it:
$ echo 'Winter is coming... 🌞🌞🌞' | srgn -s '🌞+?' '☃️'
Winter is coming... ☃️
[!NOTE] Again, as with deletion, specifying squeezing without an explicit scope is an error. Otherwise, the entire input is squeezed.
Character casing
A good chunk of tr usage falls into this category. It's
very straightforward.
$ echo 'Hello, World!' | srgn --lower
hello, world!
$ echo 'Hello, World!' | srgn --upper
HELLO, WORLD!
$ echo 'hello, world!' | srgn --titlecase
Hello, World!
Normalization
Decomposes input according to Normalization Form D, and then discards code points of the Mark category (see examples). That roughly means: take fancy character, rip off dangly bits, throw those away.
$ echo 'Naïve jalapeño ärgert mgła' | srgn -d '\P{ASCII}' # Naive approach
Nave jalapeo rgert mga
$ echo 'Naïve jalapeño ärgert mgła' | srgn --normalize # Normalize is smarter
Naive jalapeno argert mgła
Notice how mgła is out of scope for NFD, as it is "atomic" and thus not decomposable
(at least that's what ChatGPT whispers in my ear).
Symbols
This action replaces multi-character, ASCII symbols with appropriate single-code point, native Unicode counterparts.
$ echo '(A --> B) != C --- obviously' | srgn --symbols
(A ⟶ B) ≠ C — obviously
Alternatively, if you're only interested in math, make use of scoping:
$ echo 'A <= B --- More is--obviously--possible' | srgn --symbols '<='
A ≤ B --- More is--obviously--possible
As there is a 1:1 correspondence between an ASCII symbol and its replacement, the effect is reversible[^1]:
$ echo 'A ⇒ B' | srgn --symbols --invert
A => B
There is only a limited set of symbols supported as of right now, but more can be added.
German
This action replaces alternative spellings of German special characters (ae, oe, ue, ss) with their native versions (ä, ö, ü, ß)[^2].
$ echo 'Gruess Gott, Neueroeffnungen, Poeten und Abenteuergruetze!' | srgn --german
Grüß Gott, Neueröffnungen, Poeten und Abenteuergrütze!
This action is based on a word list (compile without
german feature if this bloats your binary too much). Note the following features about
the above example:
- empty scope and replacement: the entire input will be processed, and no replacement is performed
Poetenremained as-is, instead of being naively and mistakenly converted toPöten- as a (compound) word,
Abenteuergrützeis not going to be found in any reasonable word list, but was handled properly nonetheless - while part of a compound word,
Abenteuerremained as-is as well, instead of being incorrectly converted toAbenteür - lastly,
Neueroeffnungensneakily forms aueelement neither constituent word (neu,Eröffnungen) possesses, but is still processed correctly (despite the mismatched casings as well)
On request, replacements may be forced, as is potentially useful for names:
$ echo 'Frau Loetter steht ueber der Mauer.' | srgn --german-naive '(?<=Frau )\w+'
Frau Lötter steht ueber der Mauer.
Through positive lookahead, nothing but the salutation was scoped and therefore changed.
Mauer correctly remained as-is, but ueber was not processed. A second pass fixes
this:
$ echo 'Frau Loetter steht ueber der Mauer.' | srgn --german-naive '(?<=Frau )\w+' | srgn --german
Frau Lötter steht über der Mauer.
[!NOTE]
Options and flags pertaining to some "parent" are prefixed with their parent's name, and will imply their parent when given, such that the latter does not need to be passed explicitly. That's why
--german-naiveis named as it is, and--germanneedn't be passed.This behavior might change once
clapsupports subcommand chaining.
Some branches are undecidable for this modest tool, as it operates without language
context. For example, both Busse (busses) and Buße (penance) are legal words. By
default, replacements are greedily performed if legal (that's the whole
point of srgn,
after all), but there's a flag for toggling this behavior:
$ echo 'Busse und Geluebte 🙏' | srgn --german
Buße und Gelübte 🙏
$ echo 'Busse 🚌 und Fussgaenger 🚶♀️' | srgn --german-prefer-original
Busse 🚌 und Fußgänger 🚶♀️
Combining Actions
Most actions are composable, unless doing so were nonsensical (like for deletion). Their order of application is fixed, so the order of the flags given has no influence (piping multiple runs is an alternative, if needed). Replacements always occur first. Generally, the CLI is designed to prevent misuse and surprises: it prefers crashing to doing something unexpected (which is subjective, of course). Note that lots of combinations are technically possible, but might yield nonsensical results.
Combining actions might look like:
$ echo 'Koeffizienten != Bruecken...' | srgn -Sgu
KOEFFIZIENTEN ≠ BRÜCKEN...
A more narrow scope can be specified, and will apply to all actions equally:
$ echo 'Koeffizienten != Bruecken...' | srgn -Sgu '\b\w{1,8}\b'
Koeffizienten != BRÜCKEN...
The word boundaries are
required as otherwise Koeffizienten is matched as Koeffizi and enten. Note how the
trailing periods cannot be, for example, squeezed. The required scope of \. would
interfere with the given one. Regular piping solves this:
$ echo 'Koeffizienten != Bruecken...' | srgn -Sgu '\b\w{1,8}\b' | srgn -s '\.'
Koeffizienten != BRÜCKEN.
Note: regex escaping (\.) can be circumvent using literal scoping.
The specially treated replacement action is also composable:
$ echo 'Mooood: 🤮🤒🤧🦠!!!' | srgn -s '\p{Emoji}' '😷'
Mooood: 😷!!!
Emojis are first all replaced, then squeezed. Notice how nothing else is squeezed.
Scopes
Scopes are the second driving concept to srgn. In the default case, the main scope is
a regular expression. The actions section showcased this use case in some
detail, so it's not repeated here. It is given as a first positional argument.
Language grammar-aware scopes
srgn extends this through prepared, language grammar-aware scopes, made possible
through the excellent tree-sitter
library. It offers a
queries feature,
which works much like pattern matching against a tree data
structure.
srgn comes bundled with a handful of the most useful of these queries. Through its
discoverable API (either as a library or via CLI, srgn --help), one
can learn of the supported languages and available, prepared queries. Each supported
language comes with an escape hatch, allowing you to run your own, custom ad-hoc
queries. The hatch comes in the form of --lang-query <S EXPRESSION>, where lang is a
language such as python. See below for more on this advanced topic.
[!NOTE]
Language scopes are applied first, so whatever regex aka main scope you pass, it operates on each matched language construct individually.
Prepared queries
This section shows examples for some of the prepared queries.
Most prepared queries are static, e.g. they always scope "all comments", for example. Various language elements are naturally named however: functions, classes, structs, modules and more are usually not anonymous, but carry names. Some prepared queries therefore have dynamic variants, where an optional regular expression pattern can additionally be supplied. The pattern then applies to the name of the item, and will only scope those items whose name matches the pattern. This allows for an extra degree of freedom for querying. Examples follow.
Finding all structs related to testing (Go)
An input like
type PublicTestInput struct {
Name string
Value int
}
type privateTestInput struct {
name string
value int
}
type ActualDomainType struct {
Name string
Value int
}
can be searched as
$ cat testing.go | srgn --go 'struct~[tT]est'
1:type PublicTestInput struct {
2: Name string
3: Value int
4:}
6:type privateTestInput struct {
7: name string
8: value int
9:}
surfacing only structs whose name matches [tT]est. The ~ character serves as the
separator between the language grammar/node type and pattern. This approach allows
manipulation of only these structs, e.g.
$ cat testing.go | srgn --go 'struct~[tT]est' '(\s+)Name' '${1}TestName'
type PublicTestInput struct {
TestName string
Value int
}
type privateTestInput struct {
name string
value int
}
type ActualDomainType struct {
Name string
Value int
}
Finding all unsafe code (Rust)
One advantage of the unsafe keyword in
Rust is its "grepability".
However, an rg 'unsafe' will of course surface all string matches (rg '\bunsafe\b'
helps to an extent), not just those in of the actual Rust language keyword. srgn helps
make this more precise. For example:
// Oh no, an unsafe module!
mod scary_unsafe_operations {
pub unsafe fn unsafe_array_access(arr: &[i32], index: usize) -> i32 {
// UNSAFE: This function performs unsafe array access without bounds checking
*arr.get_unchecked(index)
}
pub fn call_unsafe_function() {
let unsafe_numbers = vec![1, 2, 3, 4, 5];
println!("About to perform an unsafe operation!");
let result = unsafe {
// Calling an unsafe function
unsafe_array_access(&unsafe_numbers, 10)
};
println!("Result of unsafe operation: {}", result);
}
}
can be searched as
$ cat unsafe.rs | srgn --rs 'unsafe' # Note: no 2nd argument necessary
3: pub unsafe fn unsafe_array_access(arr: &[i32], index: usize) -> i32 {
4: // UNSAFE: This function performs unsafe array access without bounds checking
5: *arr.get_unchecked(index)
6: }
11: let result = unsafe {
12: // Calling an unsafe function
13: unsafe_array_access(&unsafe_numbers, 10)
14: };
surfacing only truly unsafe items (and not comments, strings etc. merely mentioning
it).[^4]
Replacing allow with expect for lints (Rust)
Taking advantage of the stabilization of the expect lint level in Rust
1.81, one might want
to migrate from allow to expect throughout (cf.
959a692f1d788d071d5f55376e2bb5ff3c2ae15a in this repo):
#[allow(unsafe_code)]
if let Some(env_value) = env_value {
unsafe {
env::set_var(DEFAULT_FILTER_ENV, env_value);
}
}
can be refactored using
cat allow.rs | srgn --rust 'attribute' '^allow' 'expect'
which will yield
#[expect(unsafe_code)]
if let Some(env_value) = env_value {
unsafe {
env::set_var(DEFAULT_FILTER_ENV, env_value);
}
}
Mass import (module) renaming (Python, Rust)
As part of a large refactor (say, after an acquisition), imagine all imports of a specific package needed renaming:
import math
from pathlib import Path
import good_company.infra
import good_company.aws.auth as aws_auth
from good_company.util.iter import dedupe
from good_company.shopping.cart import * # Ok but don't do this at home!
good_company = "good_company" # good_company
At the same time, a move to src/
layout
is desired. Achieve this move with:
cat imports.py | srgn --python 'imports' '^good_company' 'src.better_company'
which will yield
import math
from pathlib import Path
import src.better_company.infra
import src.better_company.aws.auth as aws_auth
from src.better_company.util.iter import dedupe
from src.better_company.shopping.cart import * # Ok but don't do this at home!
good_company = "good_company" # good_company
Note how the last line remains untouched by this particular operation. To run across
many files, see the files option.
Similar import-related edits are supported for other languages as well, for example Rust:
use std::collections::HashMap;
use good_company::infra;
use good_company::aws::auth as aws_auth;
use good_company::util::iter::dedupe;
use good_company::shopping::cart::*;
good_company = "good_company"; // good_company
which, using
cat imports.rs | srgn --rust 'uses' '^good_company' 'better_company'
becomes
use std::collections::HashMap;
use better_company::infra;
use better_company::aws::auth as aws_auth;
use better_company::util::iter::dedupe;
use better_company::shopping::cart::*;
good_company = "good_company"; // good_company
Assigning TODOs (TypeScript)
Perhaps you're using a system of TODO notes in comments:
class TODOApp {
// TODO app for writing TODO lists
addTodo(todo: TODO): void {
// TODO: everything, actually 🤷♀️
}
}
and usually assign people to each note. It's possible to automate assigning yourself to every unassigned note (lucky you!) using
cat todo.ts | srgn --typescript 'comments' 'TODO(?=:)' 'TODO(@poorguy)'
which in this case gives
class TODOApp {
// TODO app for writing TODO lists
addTodo(todo: TODO): void {
// TODO(@poorguy): everything, actually 🤷♀️
}
}
Notice the positive lookahead of
(?=:), ensuring an actual TODO note is hit (TODO:). Otherwise, the other TODOs
mentioned around the comments would be matched as well.
Converting print calls to proper logging (Python)
Say there's code making liberal use of print:
def print_money():
"""Let's print money 💸."""
amount = 32
print("Got here.")
print_more = lambda s: print(f"Printed {s}")
print_more(23) # print the stuff
print_money()
print("Done.")
and a move to logging is desired.
That's fully automated by a call of
cat money.py | srgn --python 'function-calls' '^print$' 'logging.info'
yielding
def print_money():
"""Let's print money 💸."""
amount = 32
logging.info("Got here.")
print_more = lambda s: logging.info(f"Printed {s}")
print_more(23) # print the stuff
print_money()
logging.info("Done.")
[!NOTE] Note the anchors:
print_moreis a function call as well, but^print$ensures it's not matched.The regular expression applies after grammar scoping, so operates entirely within the already-scoped context.
Remove all comments (C#)
Overdone, comments can turn into smells. If not tended to, they might very well start lying:
using System.Linq;
public class UserService
{
private readonly AppDbContext _dbContext;
/// <summary>
/// Initializes a new instance of the <see cref="FileService"/> class.
/// </summary>
/// <param name="dbContext">The configuration for manipulating text.</param>
public UserService(AppDbContext dbContext)
{
_dbContext /* the logging context */ = dbContext;
}
/// <summary>
/// Uploads a file to the server.
/// </summary>
// Method to log users out of the system
public void DoWork()
{
_dbContext.Database.EnsureCreated(); // Ensure the database schema is deleted
_dbContext.Users.Add(new User /* the car */ { Name = "Alice" });
/* Begin reading file */
_dbContext.SaveChanges();
var user = _dbContext.Users.Where(/* fetch products */ u => u.Name == "Alice").FirstOrDefault();
/// Delete all records before proceeding
if (user /* the product */ != null)
{
System.Console.WriteLine($"Found user with ID: {user.Id}");
}
}
}
So, should you count purging comments among your fetishes, more power to you:
cat UserService.cs | srgn --csharp 'comments' -d '.*' | srgn -d '[[:blank:]]+\n'
The result is a tidy, yet taciturn:
using System.Linq;
public class UserService
{
private readonly AppDbContext _dbContext;
public UserService(AppDbContext dbContext)
{
_dbContext = dbContext;
}
public void DoWork()
{
_dbContext.Database.EnsureCreated();
_dbContext.Users.Add(new User { Name = "Alice" });
_dbContext.SaveChanges();
var user = _dbContext.Users.Where( u => u.Name == "Alice").FirstOrDefault();
if (user != null)
{
System.Console.WriteLine($"Found user with ID: {user.Id}");
}
}
}
Note how all
different
sorts of
comments were identified and removed. The second pass removes all leftover dangling
lines ([:blank:] is tabs and
spaces).
[!NOTE] When deleting (
-d), for reasons of safety and sanity, a scope is required.
Upgrade VM size (Terraform)
Say you'd like to upgrade the instance size you're using:
data "aws_ec2_instance_type" "tiny" {
instance_type = "t2.micro"
}
resource "aws_instance" "main" {
ami = "ami-022f20bb44daf4c86"
instance_type = data.aws_ec2_instance_type.tiny.instance_type
}
with
cat ec2.tf | srgn --hcl 'strings' '^t2\.(\w+)$' 't3.$1' | srgn --hcl 'data-names' 'tiny' 'small'
will give
data "aws_ec2_instance_type" "small" {
instance_type = "t3.micro"
}
resource "aws_instance" "main" {
ami = "ami-022f20bb44daf4c86"
instance_type = data.aws_ec2_instance_type.small.instance_type
}
Rename function (C)
You can rename a function:
void old_function_name(void) {
///
int variable_in_old_function_name;
///
}
int main(void) {
old_function_name();
}
using
cat function.c | srgn --c 'function' 'old_function_name' 'new_function_name'
which will give
void new_function_name(void) {
///
int variable_in_old_function_name;
///
}
int main(void) {
new_function_name();
}
Custom queries
Custom queries allow you to create ad-hoc scopes. These might be useful, for example, to create small, ad-hoc, tailor-made linters, for example to catch code such as:
if x:
return left
else:
return right
with an invocation of
cat cond.py | srgn --python-query '(if_statement consequence: (block (return_statement (identifier))) alternative: (else_clause body: (block (return_statement (identifier))))) @cond' --fail-any # will fail
to hint that the code can be more idiomatically rewritten as return left if x else right. Another example, this one in Go, is ensuring sensitive fields are not
serialized:
package main
type User struct {
Name string `json:"name"`
Token string `json:"token"`
}
which can be caught as:
cat sensitive.go | srgn --go-query '(field_declaration name: (field_identifier) @name tag: (raw_string_literal) @tag (#match? @name "[tT]oken") (#not-eq? @tag "`json:\"-\"`"))' --fail-any # will fail
Custom queries from file
Typing out tree-sitter queries at the CLI can be unwieldy. To mitigate this you can read queries from file.
Below we use the same Python file from the previous section with an invocation of
cat cond.py | srgn --python-query-file 'docs/python_cond_query.scm'
1:if x:
2: return left
3:else:
4: return right
Ignoring parts of matches
Occassionally, parts of a match need to be ignored, for example when no suitable
tree-sitter node type is available. For example, say we'd like to replace the error
with wrong inside the string of the macro body:
fn wrong() {
let wrong = "wrong";
error!("This went error");
}
Let's assume there's a node type for matching entire macros (macro_invocation) and
one to match macro names (((macro_invocation macro: (identifier) @name))), but
none to match macro contents (this is wrong, tree-sitter offers this in the form of
token_tree, but let's imagine...). To match just "This went error", the entire macro
would need to be matched, with the name part ignored. Any capture name starting with
_SRGN_IGNORE will provide just that:
cat wrong.rs | srgn --rust-query '((macro_invocation macro: (identifier) @_SRGN_IGNORE_name) @macro)' 'error' 'wrong'
fn wrong() {
let wrong = "wrong";
error!("This went wrong");
}
If it weren't ignored, the result would read wrong!("This went wrong");.
Further reading
These matching expressions are a mouthful. A couple resources exist for getting started with your own queries:
-
the great official playground for interactive use, which makes developing queries a breeze. For example, the above Go sample looks like:

-
How to write a linter using tree-sitter in an hour, a great introduction to the topic in general
-
the official
tree-sitterCLI -
using
srgnwith high verbosity (-vvvv) is supposed to grant detailed insights into what's happening to your input, including a representation of the parsed tree
Run against multiple files
Use the --glob option to run against multiple files, in-place. This option accepts a
glob pattern. The glob is
processed within srgn: it must be quoted to prevent premature shell interpretation.
The --glob option takes precedence over the heuristics of language scoping. For
example,
$ srgn --go 'comments' --glob 'tests/langs/go/fizz*.go' '\w+'
tests/langs/go/fizzbuzz.go
5:// fizzBuzz prints the numbers from 1 to a specified limit.
6:// For multiples of 3, it prints "Fizz" instead of the number,
7:// for multiples of 5, it prints "Buzz", and for multiples of both 3 and 5,
8:// it prints "FizzBuzz".
25: // Run the FizzBuzz function for numbers from 1 to 100
finds only what's matched by the (narrow) glob, even though --go queries by themselves
would match much more.
srgn will process results fully parallel, using all available threads. For example,
450k lines of Python are processed in about a second, altering
over 1000 lines across a couple hundred files:
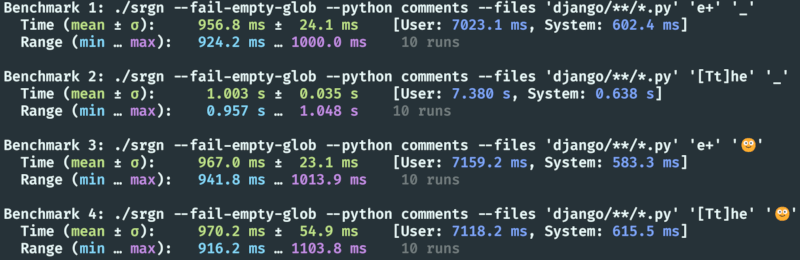
Run the benchmarks too see performance for your own system.
Explicit failure for (mis)matches
After all scopes are applied, it might turn out no matches were found. The default behavior is to silently succeed:
$ echo 'Some input...' | srgn --delete '\d'
Some input...
The output matches the specification: all digits are removed. There just happened to be none. No matter how many actions are applied, the input is returned unprocessed once this situation is detected. Hence, no unnecessary work is done.
One might prefer receiving explicit feedback (exit code other than zero) on failure:
echo 'Some input...' | srgn --delete --fail-none '\d' # will fail
The inverse scenario is also supported: failing if anything matched. This is useful for checks (for example, in CI) against "undesirable" content. This works much like a custom, ad-hoc linter.
Take for example "old-style" Python code, where type hints are not yet surfaced to the syntax-level:
def square(a):
"""Squares a number.
:param a: The number (type: int or float)
"""
return a**2
This style can be checked against and "forbidden" using:
cat oldtyping.py | srgn --python 'doc-strings' --fail-any 'param.+type' # will fail
Literal scope
This causes whatever was passed as the regex scope to be interpreted literally. Useful for scopes containing lots of special characters that otherwise would need to be escaped:
$ echo 'stuff...' | srgn -d --literal-string '.'
stuff
Help output
For reference, the full help output with all available options is given below. As with all other snippets, the output is validated for correctness as part of unit tests. Checkout git tags to view help output of specific versions.
$ srgn --help
A grep-like tool which understands source code syntax and allows for manipulation in
addition to search
Usage: srgn [OPTIONS] [SCOPE] [REPLACEMENT]
Arguments:
[SCOPE]
Scope to apply to, as a regular expression pattern.
If string literal mode is requested, will be interpreted as a literal
string.
Actions will apply their transformations within this scope only.
The default is the global scope, matching the entire input. Where that
default is meaningless or dangerous (e.g., deletion), this argument is
required.
[default: .*]
Options:
--completions <SHELL>
Print shell completions for the given shell.
[possible values: bash, elvish, fish, powershell, zsh]
-h, --help
Print help (see a summary with '-h')
-V, --version
Print version
Composable Actions:
-u, --upper
Uppercase anything in scope.
[env: UPPER=]
-l, --lower
Lowercase anything in scope.
[env: LOWER=]
-t, --titlecase
Titlecase anything in scope.
[env: TITLECASE=]
-n, --normalize
Normalize (Normalization Form D) anything in scope, and throw away marks.
[env: NORMALIZE=]
-g, --german
Perform substitutions on German words, such as 'Abenteuergruesse' to
'Abenteuergrüße', for anything in scope.
ASCII spellings for Umlauts (ae, oe, ue) and Eszett (ss) are replaced by
their respective native Unicode (ä, ö, ü, ß).
Arbitrary compound words are supported.
Words legally containing alternative spellings are not modified.
Words require correct spelling to be detected.
-S, --symbols
Perform substitutions on symbols, such as '!=' to '≠', '->' to '→', on
anything in scope.
Helps translate 'ASCII art' into native Unicode representations.
[REPLACEMENT]
Replace anything in scope with this value.
Variables are supported: if a regex pattern was used for scoping and
captured content in named or numbered capture groups, access these in the
replacement value using `$1` etc. for numbered, `$NAME` etc. for named
capture groups.
This action is specially treated as a positional argument for ergonomics and
compatibility with `tr`.
If given, will run before any other action.
[env: REPLACE=]
Standalone Actions (only usable alone):
-d, --delete
Delete anything in scope.
Cannot be used with any other action: there is no point in deleting and
performing any other processing. Sibling actions would either receive empty
input or have their work wiped.
-s, --squeeze
Squeeze consecutive occurrences of scope into one.
[env: SQUEEZE=]
[aliases: squeeze-repeats]
Options (global):
-G, --glob <GLOB>
Glob of files to work on (instead of reading stdin).
If actions are applied, they overwrite files in-place.
For supported glob syntax, see:
<https://docs.rs/glob/0.3.1/glob/struct.Pattern.html>
Names of processed files are written to stdout.
--fail-no-files
Fail if working on files (e.g. globbing is requested) but none are found.
Processing no files is not an error condition in itself, but might be an
unexpected outcome in some contexts. This flag makes the condition explicit.
--dry-run
Do not destructively overwrite files, instead print rich diff only.
The diff details the names of files which would be modified, alongside all
changes inside those files which would be performed outside of dry running.
It is similar to git diff with word diffing enabled.
-i, --invert
Undo the effects of passed actions, where applicable.
Requires a 1:1 mapping between replacements and original, which is currently
available only for:
- symbols: '≠' <-> '!=' etc.
Other actions:
- german: inverting e.g. 'Ä' is ambiguous (can be 'Ae' or 'AE')
- upper, lower, deletion, squeeze: inversion is impossible as information is
lost
These may still be passed, but will be ignored for inversion and applied
normally.
[env: INVERT=]
-L, --literal-string
Do not interpret the scope as a regex. Instead, interpret it as a literal
string. Will require a scope to be passed.
[env: LITERAL_STRING=]
--fail-any
If anything at all is found to be in scope, fail.
The default is to continue processing normally.
--fail-none
If nothing is found to be in scope, fail.
The default is to return the input unchanged (without failure).
-j, --join-language-scopes
Join (logical 'OR') multiple language scopes, instead of intersecting them.
The default when multiple language scopes are given is to intersect their
scopes, left to right. For example, `--go func --go strings` will first
scope down to `func` bodies, then look for strings only within those. This
flag instead joins (in the set logic sense) all scopes. The example would
then scope any `func` bodies, and any strings, anywhere. Language scopers
can then also be given in any order.
No effect if only a single language scope is given. Also does not affect
non-language scopers (regex pattern etc.), which always intersect.
-H, --hidden
Do not ignore hidden files and directories.
--gitignored
Do not ignore `.gitignore`d files and directories.
--sorted
Process files in lexicographically sorted order, by file path.
In search mode, this emits results in sorted order. Otherwise, it processes
files in sorted order.
Sorted processing disables parallel processing.
--threads <THREADS>
Number of threads to run processing on, when working with files.
If not specified, will default to available parallelism. Set to 1 for
sequential, deterministic (but not sorted) output.
-v, --verbose...
Increase log verbosity level.
The base log level to use is read from the `RUST_LOG` environment variable
(if unspecified, defaults to 'error'), and increased according to the number
of times this flag is given, maxing out at 'trace' verbosity.
Language scopes:
--c <C>
Scope C code using a prepared query.
[env: C=]
Possible values:
- comments: Comments (single- and multi-line)
- strings: Strings
- includes: Includes
- type-def: Type definitions
- enum: `enum` definitions
- struct: `struct` type definitions
- variable: Variable definitions
- function: All functions usages (declarations and calls)
- function-def: Function definitions
- function-decl: Function declaration
- switch: `switch` blocks
- if: `if` blocks
- for: `for` blocks
- while: `while` blocks
- do: `do` blocks
- union: `union` blocks
- identifier: Identifier
- declaration: Declaration
- call-expression: Call expression
--c-query <TREE-SITTER-QUERY-VALUE>
Scope C code using a custom tree-sitter query.
[env: C_QUERY=]
--c-query-file <TREE-SITTER-QUERY-FILENAME>
Scope C code using a custom tree-sitter query from file.
[env: C_QUERY_FILE=]
--csharp <CSHARP>
Scope C# code using a prepared query.
[env: CSHARP=]
[aliases: cs]
Possible values:
- comments: Comments (including XML, inline, doc comments)
- strings: Strings (incl. verbatim, interpolated; incl. quotes,
except for interpolated)
- usings: `using` directives (including periods)
- struct: `struct` definitions (in their entirety)
- enum: `enum` definitions (in their entirety)
- interface: `interface` definitions (in their entirety)
- class: `class` definitions (in their entirety)
- method: Method definitions (in their entirety)
- variable-declaration: Variable declarations (in their entirety)
- property: Property definitions (in their entirety)
- constructor: Constructor definitions (in their entirety)
- destructor: Destructor definitions (in their entirety)
- field: Field definitions on types (in their entirety)
- attribute: Attribute names
- identifier: Identifier names
--csharp-query <TREE-SITTER-QUERY-VALUE>
Scope C# code using a custom tree-sitter query.
[env: CSHARP_QUERY=]
--csharp-query-file <TREE-SITTER-QUERY-FILENAME>
Scope C# code using a custom tree-sitter query from file.
[env: CSHARP_QUERY_FILE=]
--go <GO>
Scope Go code using a prepared query.
[env: GO=]
Possible values:
- comments: Comments (single- and multi-line)
- strings: Strings (interpreted and raw; excluding struct tags)
- imports: Imports
- expression: Expressions (all of them!)
- type-def: Type definitions
- type-alias: Type alias assignments
- struct: `struct` type definitions
- struct~<PATTERN>: Like struct, but only considers items whose name matches
PATTERN.
- interface: `interface` type definitions
- interface~<PATTERN>: Like interface, but only considers items whose name
matches PATTERN.
- const: `const` specifications
- var: `var` specifications
- func: `func` definitions
- func~<PATTERN>: Like func, but only considers items whose name matches
PATTERN.
- method: Method `func` definitions (`func (recv Recv) SomeFunc()`)
- free-func: Free `func` definitions (`func SomeFunc()`)
- init-func: `func init()` definitions
- type-params: Type parameters (generics)
- defer: `defer` blocks
- select: `select` blocks
- go: `go` blocks
- switch: `switch` blocks
- labeled: Labeled statements
- goto: `goto` statements
- struct-tags: Struct tags
--go-query <TREE-SITTER-QUERY-VALUE>
Scope Go code using a custom tree-sitter query.
[env: GO_QUERY=]
--go-query-file <TREE-SITTER-QUERY-FILENAME>
Scope Go code using a custom tree-sitter query from file.
[env: GO_QUERY_FILE=]
--hcl <HCL>
Scope HashiCorp Configuration Language code using a prepared query.
[env: HCL=]
Possible values:
- variable: `variable` blocks (in their entirety)
- resource: `resource` blocks (in their entirety)
- data: `data` blocks (in their entirety)
- output: `output` blocks (in their entirety)
- provider: `provider` blocks (in their entirety)
- terraform: `terraform` blocks (in their entirety)
- locals: `locals` blocks (in their entirety)
- module: `module` blocks (in their entirety)
- variables: Variable declarations and usages
- resource-names: `resource` name declarations and usages
- resource-types: `resource` type declarations and usages
- data-names: `data` name declarations and usages
- data-sources: `data` source declarations and usages
- comments: Comments
- strings: Literal strings
--hcl-query <TREE-SITTER-QUERY-VALUE>
Scope HashiCorp Configuration Language code using a custom tree-sitter query.
[env: HCL_QUERY=]
--hcl-query-file <TREE-SITTER-QUERY-FILENAME>
Scope HashiCorp Configuration Language code using a custom tree-sitter query
from file.
[env: HCL_QUERY_FILE=]
--python <PYTHON>
Scope Python code using a prepared query.
[env: PYTHON=]
[aliases: py]
Possible values:
- comments: Comments
- strings: Strings (raw, byte, f-strings; interpolation not
included)
- imports: Module names in imports (incl. periods; excl.
`import`/`from`/`as`/`*`)
- doc-strings: Docstrings (not including multi-line strings)
- function-names: Function names, at the definition site
- function-calls: Function calls
- class: Class definitions (in their entirety)
- def: Function definitions (*all* `def` block in their
entirety)
- async-def: Async function definitions (*all* `async def` block in
their entirety)
- methods: Function definitions inside `class` bodies
- class-methods: Function definitions decorated as `classmethod` (excl.
the decorator)
- static-methods: Function definitions decorated as `staticmethod` (excl.
the decorator)
- with: `with` blocks (in their entirety)
- try: `try` blocks (in their entirety)
- lambda: `lambda` statements (in their entirety)
- globals: Global, i.e. module-level variables
- variable-identifiers: Identifiers for variables (left-hand side of
assignments)
- types: Types in type hints
- identifiers: Identifiers (variable names, ...)
--python-query <TREE-SITTER-QUERY-VALUE>
Scope Python code using a custom tree-sitter query.
[env: PYTHON_QUERY=]
--python-query-file <TREE-SITTER-QUERY-FILENAME>
Scope Python code using a custom tree-sitter query from file.
[env: PYTHON_QUERY_FILE=]
--rust <RUST>
Scope Rust code using a prepared query.
[env: RUST=]
[aliases: rs]
Possible values:
- comments: Comments (line and block styles; excluding doc comments;
comment chars incl.)
- doc-comments: Doc comments (comment chars included)
- uses: Use statements (paths only; excl. `use`/`as`/`*`)
- strings: Strings (regular, raw, byte; includes interpolation parts in
format strings!)
- attribute: Attributes like `#[attr]`
- struct: `struct` definitions
- struct~<PATTERN>: Like struct, but only considers items whose name matches
PATTERN.
- priv-struct: `struct` definitions not marked `pub`
- pub-struct: `struct` definitions marked `pub`
- pub-crate-struct: `struct` definitions marked `pub(crate)`
- pub-self-struct: `struct` definitions marked `pub(self)`
- pub-super-struct: `struct` definitions marked `pub(super)`
- enum: `enum` definitions
- enum~<PATTERN>: Like enum, but only considers items whose name matches
PATTERN.
- priv-enum: `enum` definitions not marked `pub`
- pub-enum: `enum` definitions marked `pub`
- pub-crate-enum: `enum` definitions marked `pub(crate)`
- pub-self-enum: `enum` definitions marked `pub(self)`
- pub-super-enum: `enum` definitions marked `pub(super)`
- enum-variant: Variant members of `enum` definitions
- fn: Function definitions
- fn~<PATTERN>: Like fn, but only considers items whose name matches
PATTERN.
- impl-fn: Function definitions inside `impl` blocks (associated
functions/methods)
- priv-fn: Function definitions not marked `pub`
- pub-fn: Function definitions marked `pub`
- pub-crate-fn: Function definitions marked `pub(crate)`
- pub-self-fn: Function definitions marked `pub(self)`
- pub-super-fn: Function definitions marked `pub(super)`
- const-fn: Function definitions marked `const`
- async-fn: Function definitions marked `async`
- unsafe-fn: Function definitions marked `unsafe`
- extern-fn: Function definitions marked `extern`
- test-fn: Function definitions with attributes containing `test`
(`#[test]`, `#[rstest]`, ...)
- trait: `trait` definitions
- trait~<PATTERN>: Like trait, but only considers items whose name matches
PATTERN.
- impl: `impl` blocks
- impl-type: `impl` blocks for types (`impl SomeType {}`)
- impl-trait: `impl` blocks for traits on types (`impl SomeTrait for
SomeType {}`)
- mod: `mod` blocks
- mod~<PATTERN>: Like mod, but only considers items whose name matches
PATTERN.
- mod-tests: `mod tests` blocks
- type-def: Type definitions (`struct`, `enum`, `union`)
- identifier: Identifiers
- type-identifier: Identifiers for types
- closure: Closure definitions
- unsafe: `unsafe` keyword usages (`unsafe fn`, `unsafe` blocks,
`unsafe Trait`, `unsafe impl Trait`)
--rust-query <TREE-SITTER-QUERY-VALUE>
Scope Rust code using a custom tree-sitter query.
[env: RUST_QUERY=]
--rust-query-file <TREE-SITTER-QUERY-FILENAME>
Scope Rust code using a custom tree-sitter query from file.
[env: RUST_QUERY_FILE=]
--typescript <TYPESCRIPT>
Scope TypeScript code using a prepared query.
[env: TYPESCRIPT=]
[aliases: ts]
Possible values:
- comments: Comments
- strings: Strings (literal, template)
- imports: Imports (module specifiers)
- function: Any `function` definitions
- async-function: `async function` definitions
- sync-function: Non-`async function` definitions
- method: Method definitions
- constructor: `constructor` method definitions
- class: `class` definitions
- enum: `enum` definitions
- interface: `interface` definitions
- try-catch: `try`/`catch`/`finally` blocks
- var-decl: Variable declarations (`let`, `const`, `var`)
- let: `let` variable declarations
- const: `const` variable declarations
- var: `var` variable declarations
- type-params: Type (generic) parameters
- type-alias: Type alias declarations
- namespace: `namespace` blocks
- export: `export` blocks
--typescript-query <TREE-SITTER-QUERY-VALUE>
Scope TypeScript code using a custom tree-sitter query.
[env: TYPESCRIPT_QUERY=]
--typescript-query-file <TREE-SITTER-QUERY-FILENAME>
Scope TypeScript code using a custom tree-sitter query from file.
[env: TYPESCRIPT_QUERY_FILE=]
Options (german):
--german-prefer-original
When some original version and its replacement are equally legal, prefer the
original and do not modify.
For example, "Busse" (original) and "Buße" (replacement) are equally legal
words: by default, the tool would prefer the latter.
[env: GERMAN_PREFER_ORIGINAL=]
--german-naive
Always perform any possible replacement ('ae' -> 'ä', 'ss' -> 'ß', etc.),
regardless of legality of the resulting word
Useful for names, which are otherwise not modifiable as they do not occur in
dictionaries. Called 'naive' as this does not perform legal checks.
[env: GERMAN_NAIVE=]
Rust library
While this tool is CLI-first, it is library-very-close-second, and library usage is treated as a first-class citizen just the same. See the library documentation for more, library-specific details.
Note that the binary takes precedence though, which with the crate currently being both a library and binary, creates problems. This might be fixed in the future.
Status and stats
![]()
![]()
![]()
Note: these apply to the entire repository, including the binary.
Code coverage icicle graph
The code is currently structured as (color indicates coverage):

Hover over the rectangles for file names.
Contributing
To see how to build, refer to compiling from source. Otherwise, refer to the guidelines.
Similar tools
An unordered list of similar tools you might be interested in.
- GritQL (very similar)
ast-grep(very similar)- Semgrep
pssfastmodprefactorgrep-astambersdripgrepripgrep-structured- tree-sitter CLI
tree-sitter-grepgron- Ruleguard (quite different, but useful for custom linting)
- Coccinelle for Rust
Comparison with tr
srgn is inspired by tr, and in its simplest form behaves similarly, but not
identically. In theory, tr is quite flexible. In practice, it is commonly used mainly
across a couple specific tasks. Next to its two positional arguments ('arrays of
characters'), one finds four flags:
-c,-C,--complement: complement the first array-d,--delete: delete characters in the first first array-s,--squeeze-repeats: squeeze repeats of characters in the first array-t,--truncate-set1: truncate the first array to the length of the second
In srgn, these are implemented as follows:
- is not available directly as an option; instead, negation of regular expression
classes can be used (e.g.,
[^a-z]), to much more potent, flexible and well-known effect - available (via regex)
- available (via regex)
- not available: it's inapplicable to regular expressions, not commonly used and, if used, often misused
To show how uses of tr found in the wild can translate to srgn, consider the
following section.
Use cases and equivalences
The following sections are the approximate categories much of tr usage falls into.
They were found using GitHub's code search. The corresponding
queries are given. Results are from the first page of results at the time. The code
samples are links to their respective sources.
As the stdin isn't known (usually dynamic), some representative samples are used and the tool is exercised on those.
Identifier Safety
Making inputs safe for use as identifiers, for example as variable names.
-
Translates to:
$ echo 'some-variable? 🤔' | srgn '[^[:alnum:]_\n]' '_' some_variable___Similar examples are:
-
Translates to:
$ echo 'some variablê' | srgn '[^[:alnum:]]' '_' some__variabl_ -
Translates to:
$ echo '🙂 hellö???' | srgn -s '[^[:alnum:]]' '-' -hell-
Literal-to-literal translation
Translates a single, literal character to another, for example to clean newlines.
-
Translates to:
$ echo 'x86_64 arm64 i386' | srgn ' ' ';' x86_64;arm64;i386Similar examples are:
-
Translates to:
$ echo '3.12.1' | srgn --literal-string '.' '\n' # Escape sequence works 3 12 1 $ echo '3.12.1' | srgn '\.' '\n' # Escape regex otherwise 3 12 1 -
Translates to:
$ echo -ne 'Some\nMulti\nLine\nText' | srgn --literal-string '\n' ',' Some,Multi,Line,TextIf escape sequences remain uninterpreted (
echo -E, the default), the scope's escape sequence will need to be turned into a literal\andnas well, as it is otherwise interpreted by the tool as a newline:$ echo -nE 'Some\nMulti\nLine\nText' | srgn --literal-string '\\n' ',' Some,Multi,Line,TextSimilar examples are:
Removing a character class
Very useful to remove whole categories in one fell swoop.
-
tr -d '[:punct:]'which they describe as:Omit all punctuation characters
translates to:
$ echo 'Lots... of... punctuation, man.' | srgn -d '[[:punct:]]' Lots of punctuation man
Lots of use cases also call for inverting, then removing a character class.
-
Translates to:
$ echo 'i RLY love LOWERCASING everything!' | srgn -d '[^[:lower:]]' iloveeverything -
Translates to:
$ echo 'All0wed ??? 💥' | srgn -d '[^[:alnum:]]' All0wed -
Translates to:
$ echo '{"id": 34987, "name": "Harold"}' | srgn -d '[^[:digit:]]' 34987
Remove literal character(s)
Identical to replacing them with the empty string.
-
Translates to:
$ echo '1632485561.123456' | srgn -d '\.' # Unix timestamp 1632485561123456Similar examples are:
-
Translates to:
$ echo -e 'DOS-Style\r\n\r\nLines' | srgn -d '\r\n' DOS-StyleLinesSimilar examples are:
Squeeze whitespace
Remove repeated whitespace, as it often occurs when slicing and dicing text.
-
Translates to:
$ echo 'Lots of space !' | srgn -s '[[:space:]]' # Single space stays Lots of space !Similar examples are:
tr -s " "tr -s [:blank:](blankis\tand space)tr -s(no argument: this will error out; presumably space was meant)tr -s ' 'tr -s ' 'tr -s '[:space:]'tr -s ' '
-
tr -s ' ' '\n'(squeeze, then replace)Translates to:
$ echo '1969-12-28 13:37:45Z' | srgn -s ' ' 'T' # ISO8601 1969-12-28T13:37:45Z -
Translates to:
$ echo -e '/usr/local/sbin \t /usr/local/bin' | srgn -s '[[:blank:]]' ':' /usr/local/sbin:/usr/local/bin
Changing character casing
A straightforward use case. Upper- and lowercase are often used.
-
tr A-Z a-z(lowercasing)Translates to:
$ echo 'WHY ARE WE YELLING?' | srgn --lower why are we yelling?Notice the default scope. It can be refined to lowercase only long words, for example:
$ echo 'WHY ARE WE YELLING?' | srgn --lower '\b\w{,3}\b' why are we YELLING?Similar examples are:
-
tr '[a-z]' '[A-Z]'(uppercasing)Translates to:
$ echo 'why are we not yelling?' | srgn --upper WHY ARE WE NOT YELLING?Similar examples are:
License
This project is licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
[^1]: Currently, reversibility is not possible for any other action. For example,
lowercasing is not the inverse of uppercasing. Information is lost, so it cannot be
undone. Structure (imagine mixed case) was lost. Something something entropy...
[^2]: Why is such a bizzare, unrelated feature included? As usual, historical reasons.
The original, core version of srgn was merely a Rust rewrite of a previous,
existing tool, which was only
concerned with the German feature. srgn then grew from there.
[^3]: With zero actions and no language scoping provided, srgn becomes 'useless', and
other tools such as ripgrep are much more suitable. That's why an error is emitted
and input is returned unchanged.
[^4]: Combined with --fail-any, the invocation could be used to fail if any unsafe
code is found, like a low-budget linter. In reality, for this case, just use
#![forbid(unsafe_code)]
though.
Dependencies
~100MB
~2.5M SLoC