6 releases
| 0.8.4 | Oct 20, 2020 |
|---|---|
| 0.8.3 | Oct 16, 2020 |
| 0.8.2 | Sep 28, 2020 |
| 0.1.0 | Sep 27, 2020 |
#542 in Memory management
87 downloads per month
155KB
2.5K
SLoC
shared-arena
Memory pools are usefull when allocating and deallocating lots of data of the same size.
Using a memory pool speed up those allocations/deallocations.
This crate provides 3 memory pools:

Performance
On my laptop, with Intel i7-10750H, running Clear Linux OS 33840, an allocation
with shared_arena is 6 to 8 times faster than the system allocator:
SingleAlloc/SharedArena time: [12.153 ns 12.423 ns 12.724 ns]
SingleAlloc/Arena time: [9.2267 ns 9.4895 ns 9.7559 ns]
SingleAlloc/Pool time: [8.8624 ns 8.9305 ns 9.0033 ns]
SingleAlloc/Box (System Allocator) time: [71.042 ns 72.995 ns 74.442 ns]
Performances with more allocations:

The graphic was generated with criterion, reproducible with cargo bench
Implementation details
SharedArena, Arena and Pool use the same method of allocation, derived from a free list.
They allocate by pages, which include 63 elements, and keep a list of pages where at least 1 element is not used by the user.
A page has a bitfield of 64 bits, each bit indicates whether or not the element is used.
In this bitfield, if the bit is set to zero, the element is already used.
So counting the number of trailing zeros gives us the index of an unused element.
Only 1 cpu instruction is necessary to find an unused element: such as tzcnt/bsf on x86 and clz on arm
[..]1101101000
With the bitfield above, the 4th element is unused.
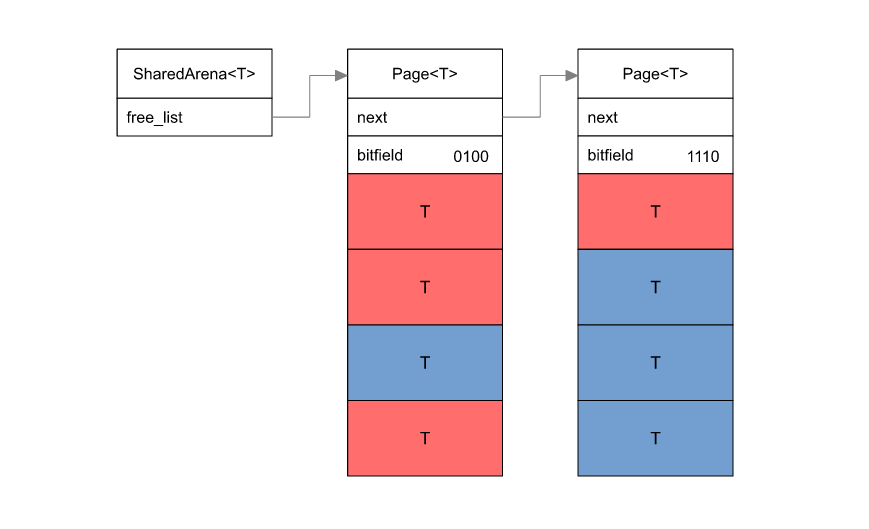
The difference between SharedArena/Arena and Pool is that Pool does not use atomics.
Safety
unsafe block are used in several places to dereference pointers.
The code is 100% covered by the miri interpreter, valgrind and 3 sanitizers: address, leak and memory, on each commit.
See the github actions
Dependencies
~42KB