5 releases
| 0.2.1 | Feb 17, 2023 |
|---|---|
| 0.2.0 | Aug 31, 2022 |
| 0.1.2 | May 30, 2021 |
| 0.1.1 | May 23, 2021 |
| 0.1.0 | May 20, 2021 |
#98 in Embedded development
42,189 downloads per month
Used in 3 crates
170KB
2.5K
SLoC
rlsf
![]()
This crate implements the TLSF (Two-Level Segregated Fit) dynamic memory allocation algorithm¹. Requires Rust 1.61.0 or later.
-
Allocation and deallocation operations are guaranteed to complete in constant time. TLSF is suitable for real-time applications.
-
Fast and small. You can have both. It was found to be smaller and faster² than most
no_std-compatible allocator crates. -
Accepts any kinds of memory pools. The low-level type
Tlsfjust divides any memory pools you provide (e.g., astaticarray) to serve allocation requests. The high-level typeGlobalTlsfautomatically acquires memory pages using standard methods on supported systems. -
This crate supports
#![no_std]. It can be used in bare-metal and RTOS-based applications.
¹ M. Masmano, I. Ripoll, A. Crespo and J. Real, "TLSF: a new dynamic memory allocator for real-time systems," Proceedings. 16th Euromicro Conference on Real-Time Systems, 2004. ECRTS 2004., Catania, Italy, 2004, pp. 79-88, doi: 10.1109/EMRTS.2004.1311009.
² Compiled for and measured on a STM32F401 microcontroller using FarCri.rs.
Measured Performance
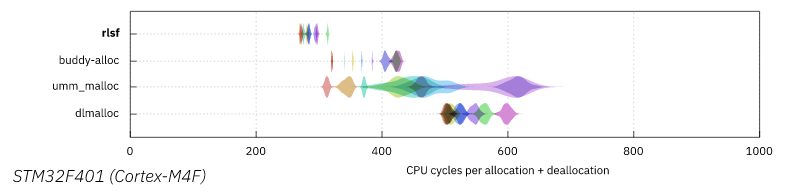
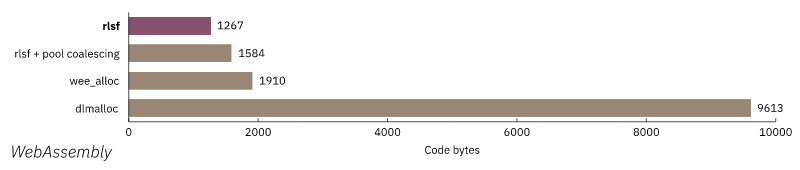
Drawbacks
-
It does not support concurrent access. A whole pool must be locked for allocation and deallocation. If you use a FIFO lock to protect the pool, the worst-case execution time will be
O(num_contending_threads). You should consider using a thread-caching memory allocator (e.g., TCMalloc, jemalloc) if achieving a maximal throughput in a highly concurrent environment is desired. -
Segregated freelists with constant-time lookup cause internal fragmentation proportional to free block sizes. The
SLLENparamter allows for adjusting the trade-off between fewer freelists and lower fragmentation. -
No special handling for small allocations (one algorithm for all sizes). This may lead to inefficiencies in allocation-heavy applications compared to modern scalable memory allocators, such as glibc and jemalloc.
Examples
Tlsf: Core API
use rlsf::Tlsf;
use std::{mem::MaybeUninit, alloc::Layout};
let mut pool = [MaybeUninit::uninit(); 65536];
// On 32-bit systems, the maximum block size is 16 << FLLEN = 65536 bytes.
// The worst-case internal fragmentation is (16 << FLLEN) / SLLEN - 2 = 4094 bytes.
// `'pool` represents the memory pool's lifetime (`pool` in this case).
let mut tlsf: Tlsf<'_, u16, u16, 12, 16> = Tlsf::new();
// ^^ ^^ ^^
// | | |
// 'pool | SLLEN
// FLLEN
tlsf.insert_free_block(&mut pool);
unsafe {
let mut ptr1 = tlsf.allocate(Layout::new::<u64>()).unwrap().cast::<u64>();
let mut ptr2 = tlsf.allocate(Layout::new::<u64>()).unwrap().cast::<u64>();
*ptr1.as_mut() = 42;
*ptr2.as_mut() = 56;
assert_eq!(*ptr1.as_ref(), 42);
assert_eq!(*ptr2.as_ref(), 56);
tlsf.deallocate(ptr1.cast(), Layout::new::<u64>().align());
tlsf.deallocate(ptr2.cast(), Layout::new::<u64>().align());
}
GlobalTlsf: Global Allocator
GlobalTlsf automatically acquires memory pages through platform-specific
mechanisms. It doesn't support returning memory pages to the system even if
the system supports it.
#[cfg(all(target_arch = "wasm32", not(target_feature = "atomics")))]
#[global_allocator]
static A: rlsf::SmallGlobalTlsf = rlsf::SmallGlobalTlsf::new();
let mut m = std::collections::HashMap::new();
m.insert(1, 2);
m.insert(5, 3);
drop(m);
Details
Changes from the Original Algorithm
- The end of each memory pool is capped by a sentinel block (a permanently occupied block) instead of a normal block with a last-block-in-pool flag. This simplifies the code a bit and improves its worst-case performance and code size.
Cargo Features
unstable: Enables experimental features that are exempt from the API stability guarantees.
License
MIT/Apache-2.0
Dependencies
~2.7–4.5MB
~87K SLoC