10 releases (stable)
| 1.3.1 | Jan 29, 2024 |
|---|---|
| 1.3.0 | Jan 23, 2024 |
| 0.1.2 | Jan 10, 2024 |
#359 in Concurrency
56 downloads per month
Used in roster
21KB
215 lines
sharded-thread
![]()
![]()
![]()
![]()
![]()
"Application tail latency is critical for services to meet their latency expectations. We have shown that the thread-per-core approach can reduce application tail latency of a key-value store by up to 71% compared to baseline Memcached running on commodity hardware and Linux."[^1]
[^1]: The Impact of Thread-Per-Core Architecture on Application Tail Latency
Introduction
This library is mainly made for io-uring and monoio. There are no dependency
on the runtime, so you should be able to use it with other runtime and also
without io-uring.
The purpose of this library is to have a performant way to send data between
thread when threads are following a thread per core architecture. Even if the
aim is to be performant remember it's a core to core passing, (or thread to
thread), which is really slow.
Thanks to Glommio for the inspiration.
Example
Originally, the library was made when you had multiple thread listening to the
same TcpStream and depending on what is sent through the TcpStream you might
want to change the thread handling the stream.
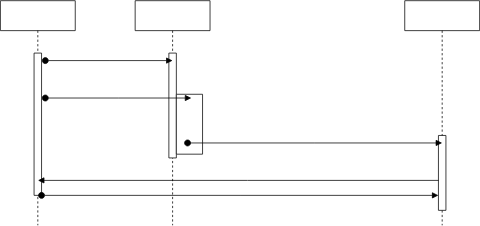
You can check some examples in the tests.
Benchmarks
Those benchmarks are only indicative, they are running in GA. You should run your own on the targeted hardware.
It shows that sharded-thread based on utility.sharded_queue is faster (~6%) than
if we built the mesh based on flume.

References
- Glommio example on their sharding
- The original monoio issue
- Sharded Queue - the fastest concurrent collection
License
Licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT) at your option.
Dependencies
~1–1.7MB
~33K SLoC