1 unstable release
| 0.7.2+serum.1 | Jan 15, 2021 |
|---|
#2090 in Encoding
Used in serum-borsh-derive
31KB
710 lines
borsh
Binary Object Representation Serializer for Hashing
Website | Join Community | Implementations | Benchmarks | Specification
Why do we need yet another serialization format? Borsh is the first serializer that prioritizes the following qualities that are crucial for security-critical projects:
- Consistent and specified binary representation:
- Consistent means there is a bijective mapping between objects and their binary representations. There is no two binary representations that deserialize into the same object. This is extremely useful for applications that use binary representation to compute hash;
- Borsh comes with a full specification that can be used for implementations in other languages;
- Safe. Borsh implementations use safe coding practices. In Rust, Borsh uses almost only safe code, with one exception usage of
unsafeto avoid an exhaustion attack; - Speed. In Rust, Borsh achieves high performance by opting out from Serde which makes it faster than bincode in some cases; which also reduces the code size.
Implementations
| Platform | Repository | Latest Release |
|---|---|---|
| Rust | borsh-rs | |
| TypeScript, JavaScript | borsh-js | |
| TypeScript | borsh-ts | |
| Java, Kotlin, Scala, Clojure, etc | borshj | |
| Go | borsh-go | |
| Python | borsh-construct-py | |
| Assemblyscript | borsh-as | |
| C# | Hexarc.Borsh | |
| C++ | borsh-cpp | (work-in-progress) |
| C++20 | borsh-cpp20 | (work-in-progress) |
| Elixir | borsh-ex |
Benchmarks
We measured the following benchmarks on objects that blockchain projects care about the most: blocks, block headers, transactions, accounts. We took object structure from the NEAR Protocol blockchain. We used Criterion for building the following graphs.
The benchmarks were run on Google Cloud n1-standard-2 (2 vCPUs, 7.5 GB memory).
Block header serialization speed vs block header size in bytes (size only roughly corresponds to the serialization complexity which causes non-smoothness of the graph):
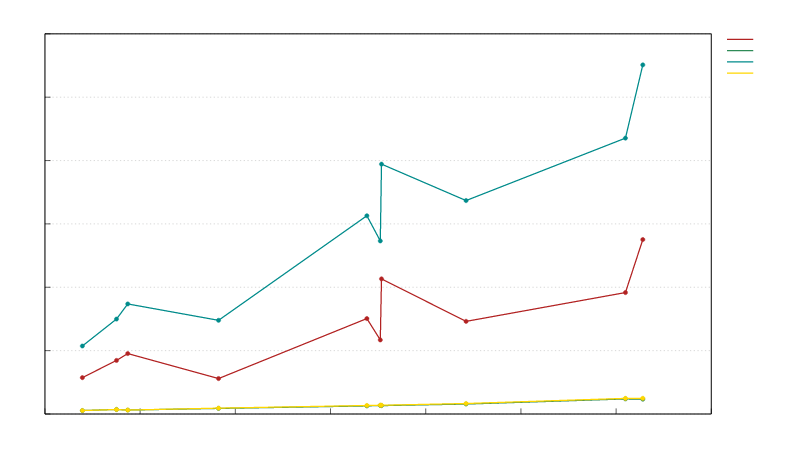
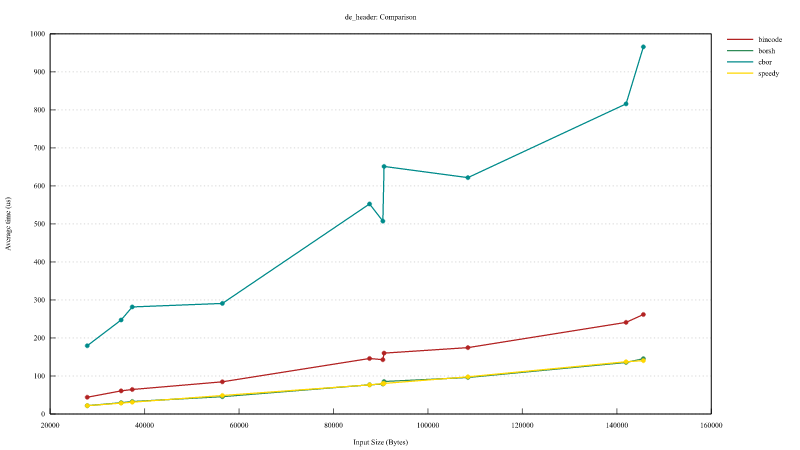
Block header de-serialization speed vs block header size in bytes:
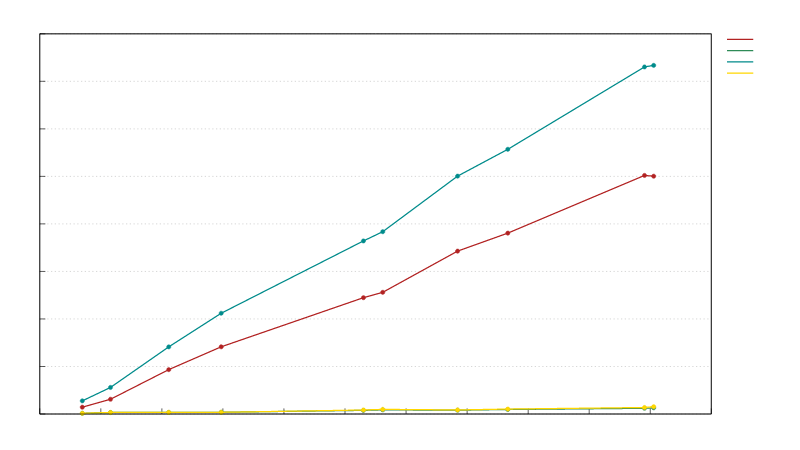
Block serialization speed vs block size in bytes:
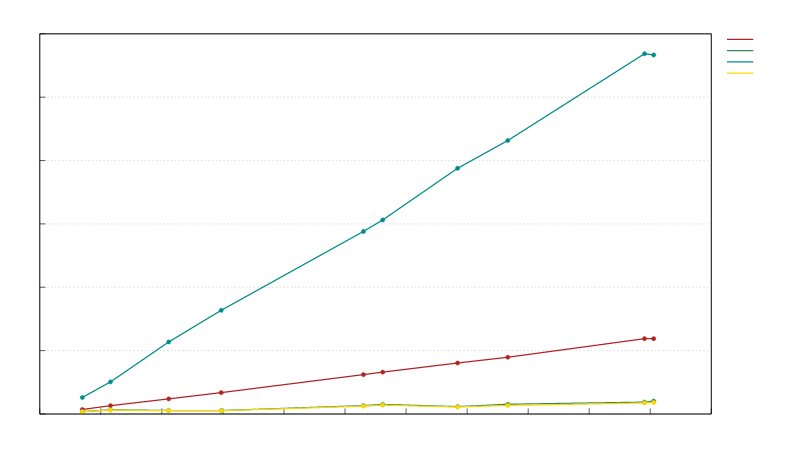
Block de-serialization speed vs block size in bytes:
See complete report here.
Specification
In short, Borsh is a non self-describing binary serialization format. It is designed to serialize any objects to canonical and deterministic set of bytes.
General principles:
- integers are little endian;
- sizes of dynamic containers are written before values as
u32; - all unordered containers (hashmap/hashset) are ordered in lexicographic order by key (in tie breaker case on value);
- structs are serialized in the order of fields in the struct;
- enums are serialized with using
u8for the enum ordinal and then storing data inside the enum value (if present).
Formal specification:
| Informal type | Rust EBNF * | Pseudocode |
| Integers | integer_type: ["u8" | "u16" | "u32" | "u64" | "u128" | "i8" | "i16" | "i32" | "i64" | "i128" ] | little_endian(x) |
| Floats | float_type: ["f32" | "f64" ] |
err_if_nan(x) little_endian(x as integer_type) |
| Unit | unit_type: "()" | We do not write anything |
| Bool | boolean_type: "bool" |
if x { repr(1 as u8) } else { repr(0 as u8) } |
| Fixed sized arrays | array_type: '[' ident ';' literal ']' |
for el in x { repr(el as ident) } |
| Dynamic sized array | vec_type: "Vec<" ident '>' |
repr(len() as u32) for el in x { repr(el as ident) } |
| Struct | struct_type: "struct" ident fields | repr(fields) |
| Fields | fields: [named_fields | unnamed_fields] | |
| Named fields | named_fields: '{' ident_field0 ':' ident_type0 ',' ident_field1 ':' ident_type1 ',' ... '}' |
repr(ident_field0 as ident_type0) repr(ident_field1 as ident_type1) ... |
| Unnamed fields | unnamed_fields: '(' ident_type0 ',' ident_type1 ',' ... ')' |
repr(x.0 as type0) repr(x.1 as type1) ... |
| Enum |
enum: 'enum' ident '{' variant0 ',' variant1 ',' ... '}' variant: ident [ fields ] ? |
Suppose X is the number of the variant that the enum takes. repr(X as u8) repr(x.X as fieldsX) |
| HashMap | hashmap: "HashMap<" ident0, ident1 ">" |
repr(x.len() as u32) for (k, v) in x.sorted_by_key() { repr(k as ident0) repr(v as ident1) } |
| HashSet | hashset: "HashSet<" ident ">" |
repr(x.len() as u32) for el in x.sorted() { repr(el as ident) } |
| Option | option_type: "Option<" ident '>' |
if x.is_some() { repr(1 as u8) repr(x.unwrap() as ident } else { repr(0 as u8) } |
| String | string_type: "String" |
encoded = utf8_encoding(x) as Vec<u8> repr(encoded.len() as u32) repr(encoded as Vec<u8>) |
Note:
- Some parts of Rust grammar are not yet formalized, like enums and variants. We backwards derive EBNF forms of Rust grammar from syn types;
- We had to extend repetitions of EBNF and instead of defining them as
[ ident_field ':' ident_type ',' ] *we define them asident_field0 ':' ident_type0 ',' ident_field1 ':' ident_type1 ',' ...so that we can refer to individual elements in the pseudocode; - We use
repr()function to denote that we are writing the representation of the given element into an imaginary buffer.
Dependencies
~1.5MB
~42K SLoC