6 releases
| 0.11.5 | Oct 21, 2021 |
|---|---|
| 0.11.4 | Feb 7, 2021 |
| 0.11.2 | May 19, 2020 |
#253 in Procedural macros
26 downloads per month
Used in modus_ponens_derive
250KB
2.5K
SLoC
modus_ponens.
Contents
Introduction
modus_ponens is an in-memory data store, in which the the structure of the data (both the database schema and the queries) is provided by a parsing expression grammar (PEG). Thus, the language for defining PEGs takes the place of SQL in RDBMSs. To give an example, JSON can be dfined by a PEG; so if we provide a PEG for JSON to modus_ponens, we can create JSON stores, and extract any particular piece of information from them using JSON queries. Note that we are not providing any particualr JSON schema, just JSON.
In addition to storing data, modus_ponens also provides a rules engine (a forward chaining inference engine) with which it is possible to massage and combine the data explicitly stored, to achieve data intelligence. The syntax of these rules is a mixture, in part prescribed by modus_ponens (logical connectives: conjunction and implication, and universally quantified variables), and in part provided by the user (conditions and consequents in rules respond to the PEG that governs the syntax of data and queries).
We might understand modus_ponens from different traditional, established perspectives:
- It can be approached from the perspective of (external) DSLs (domain specific languages). modus_ponens can be seen as a DSL engine, where the user prescribes the syntax of the language through a PEG, and modus_ponens adds the ability to produce rules with conditions and consequences formed according to the provided PEG;
- It can be approached from the perspective of knowledge representation and reasonging (KRR);
- modus_ponens can be understood from the perspective of logic programming, and be compared to the likes of CLIPS or Jess (or even Prolog, though Prolog is backwards chaining);
- It can also be seen as a tool for data analysis, and be compared to SQL engines and other data structuring schemes. In this sense, we might recall the initial example of JSON stores, and consider the difficulty of defining JSON in SQL, and compare it to that of defining JSON as a PEG;
- It can be compared to the rules engines behind bussiness rules management systems, such as Drools or JRules.
I have compared the prformance of modus_ponens with that of a couple of tools (so far, with CLIPS and with in-memory SQLite), and they are in a similar league, each with certain advantages and disadvantages, depending on the shape of the data and the queries.
TODO: Add the pending work to provide finished tools for each of the provided perspectives.
From the perspective of DSLs.
modus_ponens can be seen as a tool for producing DSLs. Using the terminology of model driven engineering, it might be said that modus_ponens is the metamodel, comprised of a PEG engine and an implementation of logical connectives and variables. Then, modus_ponens plus a given PEG would correspond to a model, and a knowledge base built on top of the given PEG would correspond to an original. This means that the space of models that can be derived from modus_ponens as a metamodel is only bound by the limits of PEGs in describing languages, thus making modus_ponens a truly powerful DSL engine.
From the perspective of KRR.
modus_ponens is able to hold knowledge structured in whatever possible form, since, practically, any structured language can be described in a PEG; and whatever the PEG used, modus_ponens allows to add rules according to the PEG. Thus, modus_ponens allows a user to represent any kind of knowledge in the most effective way, and reason about it imposing appropriate rules.
From the perspective of logic programming.
If we look at it from the perspective of logic programming, and compare it with the CLIPS progamming language (also with a forward chaining engine), we might note that:
- It is fast. With hundreds or thousands of rules loaded in the system, it is the same order of magnitude fast as CLIPS, and with tens and hundreds of thousands of rules, it is an increasing number of orders of magnitude faster than CLIPS (e.g., with 200 000 rules in the system, modus_ponens is 4 orders of magnitude faster adding another rule, see the results below).
- It is customizable. There is total freedom in the syntax of the facts that can be fed to inference engines produced with modus_ponens, since that syntax is provided by the user in the form of a PEG.
- It is scalable. The algorithmic cost (time and space) of adding both new facts and new rules to the system is very much independent of the amount of them already there. (See below for some benchmarks). In this sense it must be noted that it uses a novel algorithm with little resemblance to RETE, the algorithm behind CLIPS and most bussiness rules systems.
From the perspective of data analysis.
modus_ponens can help dealing with data. The point here is that it is not necessary to transform the data to feed it to modus_ponens; it is just necessary to provide modus_ponens with a PEG that describes the structure of the data to analyse, and then the data can be added straight into a modus_ponens knowledge base. Then it will be possible to add rules to the knowledge base or query it at whatever level of structural detail that may be needed, as specified in the PEG.
So for example to analyse and extract information from a set of logs, the PEG would prescribe facts that reflect the structure of the log entries, and then each log entry would be fed into the knowledge base as a fact.
Inference engines
Brief introduction to inference engines, to establish some terminologic common ground.
Inference engines deal with 2 basic kinds of objects: facts and rules. The fundamental operational semantics of these objects, in forward chaining systems, is three-fold:
- Facts and rules are added by the user to the system;
- Facts can match with rules, thus producing new facts not directly provided by the user (or, equivalently, triggering some other arbitrary actions);
- The system can be queried for the presence of facts, according to some query language.
Popular examples of forward chaining inference engines are the one in CLIPS, or the one behind the Drools Business Rules Management System.
Different engines provide different syntax for their facts. For example, CLIPS uses lisp style s-expressions, and Drools uses some own ad-hoc syntax.
Rules are essentially made up of a number of conditions and an action, where conditions are facts that can contain quantified, bound variables, and actions can be anything to be triggered when the conditions of a rule are matched; though here for our purposes it is enough to only consider as actions assertions of new facts, possibly containing variables used in the conditions (and substituted in the assertion with the assignments provided by the matches).
from a logical point of view, what these systems provide is, first, a syntax for facts and for Horn clauses; and then, on top of that, an implementation of conjunction, implication, and quantified variables, such as they appear in the Horn clauses. This allows these systems to extend any set of facts and Horn clauses to its completion, according to modus ponens.
modus_ponens
What modus_ponens provides is an implementation of logical conjunction and implication and of quantified variables, and it does so, not on top of some particular syntax for the facts that are conjoined or implied or that contain the variables, but on top of PEG parse trees. For modus_ponens, a fact is just a parse tree produced by the Pest PEG parser. Thus, the user of the library can provide whatever PEG she chooses to define her space of facts. In a sense, the user of the library provides the grammar for the facts, and modus_ponens provides the grammar to build rules out of those facts. As a bridge between what modus_ponens prescribes and what the user ad-libs, the user needs to mark which of the productions that compose her facts can be in the range of the variables prescribed by modus_ponens. Otherwise, there is no restriction in the structure of the productions providing the facts.
Example
As an example, we will develop a system that represents a simple taxonomy. In this system, sentences have 2 basic forms:
- taxon A is a sub-taxon of taxon B
- individual A belongs to taxon B
We want the system to provide a complete view of our taxonomy; So, for example, if we tell the system that Bobby belongs to Dog, and also that Dog is a sub-taxon of Mammal, and then we query the system for mammals, we want to obtain Bobby in the response. For this, we will add 2 rules:
- A is a sub-taxon of B & B is a sub-taxon of C -> A is a sub-taxon of C
- A belongs to B & B is a sub-taxon of C -> A belongs to C
First of all, we must add some dependencies to our Cargo.toml:
[dependencies]
modus_ponens = "0.11.3"
modus_ponens_derive = "0.1.1"
pest = "2.1.3"
pest_derive = "2.1.0"
log = "0.4"
env_logger = "0.7.1"
Now, the grammar. It is Pest that interprets this grammar,
so look up the Pest documentation for its syntax.
Since we can use unicode, we'll do so.
For the "sub-taxon" predicate we'll use ⊆, and for belongs, ∈.
We also need names for the individuals and taxons,
for which we'll use strings of lower case latin letters.
var = @{ "<" ~ "__"? ~ "X" ~ ('0'..'9')+ ~ ">" }
fact = { name ~ pred ~ name }
pred = @{ "∈" | "⊆" }
v_name = @{ ASCII_ALPHANUMERIC+ }
name = _{ v_name | var }
WHITESPACE = { " " | "\t" | "\r" | "\n" }
In this grammar, the productions WHITESPACE and var are prescribed by modus_ponens.
On top of them, the user must provide a production for fact.
So we, as "user", are providing name, v_name, and pred, to compose fact.
Here we allow for very simple facts, just triples subject-predicate-object.
Note how we mark the production v_name, that can match variables, with a prefix "v_",
and mix it with var in a further name production.
We call these logical productions.
In this case v_name is a terminal production, but it need not be so;
and there can be more than one production marked as logical.
So it is perfectly possible to represent higher order logics.
We store this grammar in a file named grammar.pest.
Then, we build our knowledge base based on the grammar. First some boilerplate:
extern crate modus_ponens;
#[macro_use]
extern crate modus_ponens_derive;
extern crate pest;
#[macro_use]
extern crate pest_derive;
#[derive(KBGen)]
#[grammar = "grammar.pest"]
pub struct KBGenerator;
This provides us with a struct KBgenerator, whose only responsibility is to
create knowledge bases that can hold facts and rules according to grammar.pest.
So we can build a knowledge base:
let kb = KBGenerator::gen_kb();
We can add rules to it:
kb.tell("<X0> ⊆ <X1> ∧ <X1> ⊆ <X2> → <X0> ⊆ <X2>.");
kb.tell("<X0> ∈ <X1> ∧ <X1> ⊆ <X2> → <X0> ∈ <X2>.");
We add some content:
kb.tell("human ⊆ primate.");
kb.tell("primate ⊆ animal.");
kb.tell("susan ∈ human.");
And we query the system:
assert_eq!(kb.ask("susan ∈ animal."), true);
assert_eq!(kb.ask("susan ⊆ animal."), false);
assert_eq!(kb.ask("primate ∈ animal."), false);
That completes a first approach to modus_ponens. To try the code in this example yourself, you can do as follows:
$ git clone <modus_ponens mirror>
$ cd modus_ponens/examples/readme-example
$ cargo build --release
$ RUST_LOG=trace ./target/release/readme-example
RUST_LOG=trace will log to stdout all facts and rules added in the system;
RUST_LOG=info will only log facts.
API
There are 3 steps in using this library: Providing a grammar, building a knowledge base with the grammar, and adding and retrieving data from the knowledge base.
Grammars
The grammars in modus_ponens are interpreted by Pest, so look up the Pest documentation for their syntax.
modus_ponens grammars must provide a top level production called fact. In
principle, facts can have any possible structure, i.e., they can be built out
of any number of terminal or non-terminal sub-productions.
modus_ponens provides a termination symbol for facts, ◊, so to add a fact
to a knowledge base, you would use a string like:
<fact1> ◊
modus_ponens also provides symbols to compose facts into rules; it provides
∧ for conjuntion, and → for implication. So a rule might be:
<fact1> ∧ <fact2> → <fact3> ◊
It is possible to use logical variables in the rules, both in the conditions
and in the consecuents. The form of the variables can be customized, but by
default is made out of a less than sign, followed by an upper case letter,
followed by any number of lower case letters or numbers, followed by a greater
than sign. For example, <Var1>, or <X2>.
To use variables, the user has to mark the productions that are in the range of
variables, called logical productions in modus_ponens. To do so, the logical
production must have a name starting by v_, and then be mixed in a further
production with the var production. For example:
v_name = @{ ASCII_ALPHANUMERIC+ }
var_range = _{ v_name | var }
It is also possible to add so called non-logical conditions in rules, that test
for arithmetic or string conditions usin a number of numeric or string
predicates (TODO: list available predicates). This are provided surrounded by
{?{ and }?}.
And it is also possible to add transformations in rules, both arithmetic and
stringy, surrounded by {={ and }=}, using string and numeric operators
(TODO: list all available operators). We use transformations to obtain new
values out of those matched by the logical conditions.
Finally, it is possible to add rules that produce new rules (instead of just new facts). This is achieved simply by using more than one implication symbol in the rule, e.g.:
<fact1> ∧ <fact2> → <fact3> → <fact4> ◊
Once the facts <fact1> and <fact2> are matched, the rule <fact3> → <fact4>◊
will be added, with any variables bound in <fact1> and <fact2> substituted by
the matching values.
Building knowledge bases
Having developed a grammar, the user of the library will want to produce knowledge bases on top of it. This just requires a little bit of boilerplate:
extern crate modus_ponens;
#[macro_use]
extern crate modus_ponens_derive;
extern crate pest;
#[macro_use]
extern crate pest_derive;
#[derive(KBGen)]
#[grammar = "path/to/grammar.pest"]
pub struct KBGenerator;
let kb = KBGenerator::gen_kb();
The "path/to/gammar.pest" is relative to the project's src/ directory.
Using the knowledge bases.
modus_ponens knowledge bases have 2 methods, tell and ask. The tell
method takes a string slice with a facts and/or rules and puts them in its
internal trees. The ask method takes a fact, possibly containing variables,
and returns either True or False (in case the query contains no variables),
or a vector of variable assignments, (in case the query contains variables).
In the latter case, an empty vector signals a negative response.
Complexity
We consider here that the state of the art in forward chaining inference engines are implementations of variants of the RETE algorithm, with different kinds of heuristic improvements but with no significative change in the fundamental complexity. We use CLIPS 6.30 as reference implementation of RETE, managed from PyCLIPS. There is CLIPS 6.31 and 6.4beta, but we gather from their changelogs that those new versions do not carry algorithmic improvements that would alter the results shown below, and PyCLIPS is very convenient for benchmarking CLIPS - and only knows about CLIPS 6.30.
Now, with modus_ponens, the cost of adding a new fact (or rule) to the system is only dependent on the grammatical complexity of the fact (or of the conditions of the rule) being added, and on the number of rules that the fact matches (or on the number of facts that match a condition of the rule, when adding a rule). In particular, those costs are independent of both the total number of facts in the system and the total number of rules in the system.
This is due to the fact that all searches in the structures that represent the sets of facts and rules in the system are made through hash table lookups; there is not a single filtered iteration of nodes involved.
This is not the case for RETE: With RETE, the cost of adding a fact or a rule increases with the total number of rules in the system. At least, that is what the numbers below show. Doorenboss in his thesis sets as objective for an efficient matching algorithm one that is polynomial in the number of facts (WMEs) and sublinear in the number of rules. He claims the objective to be achievable with his RETE/UL enhancement of RETE. What I observe with CLIPS is a performance independent of the number of facts and linear in the number of rules.
The benchmarks shown below consisted on adding 200 000 rules and 600 000 facts, where every 2 rules would be matched by 6 of the facts to produce 4 extra assertions. Every 1000 rules added we would measure the time cost of adding a few more rules and facts. We are showing the results of 3 runs. Each run took modus_ponens around 2 minutes, and CLIPS around 7 hours, in my i5-8250U @1.60GHz laptop. This is the code for the CLIPS benchmark and this for modus_ponens.
First we see the effect of increasing the number of rules in the system on the time the system takes to process each new fact. CLIPS shows a (seemingly constantly) increasing cost, whereas modus_ponens persistently takes the same time for each fact.
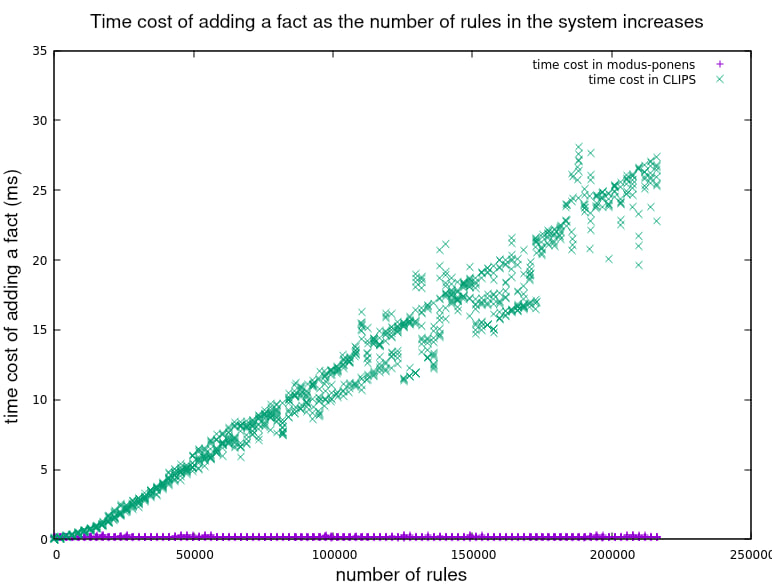
Zooming in on modus_ponens data:
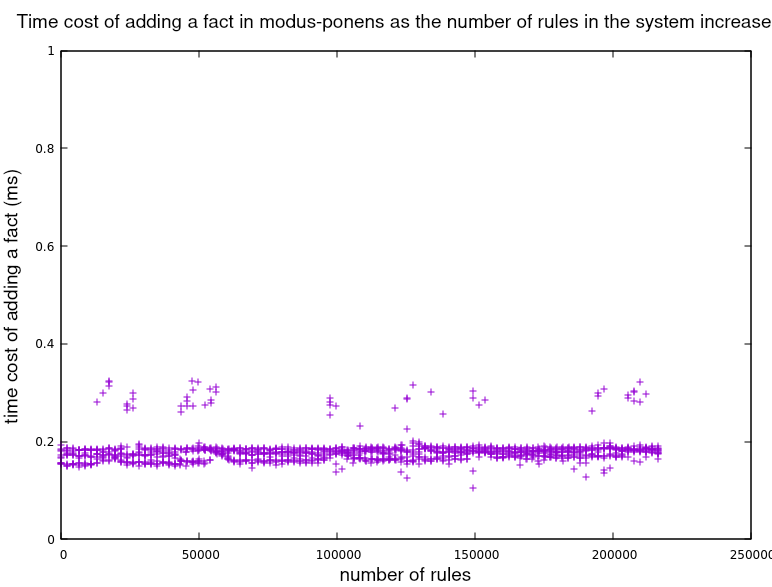
Some results which we do not plot, gave evidence to the effect that maintining the number of rules, and increasing the number of facts in the system, had no effect on the cost of adding new facts or rules, for any of the systems. In fact, in the case of modus_ponens the above graph can be taken as evidence that the cost does not depend on the number of facts, since the number of facts increases with th number of rules.
The next results show the effect that increasing the total number of rules had on the cost of adding a new rule. Again, in CLIPS the cost seems to increase continuously, whereas in modus_ponens the cost seems independent of the number of rules.
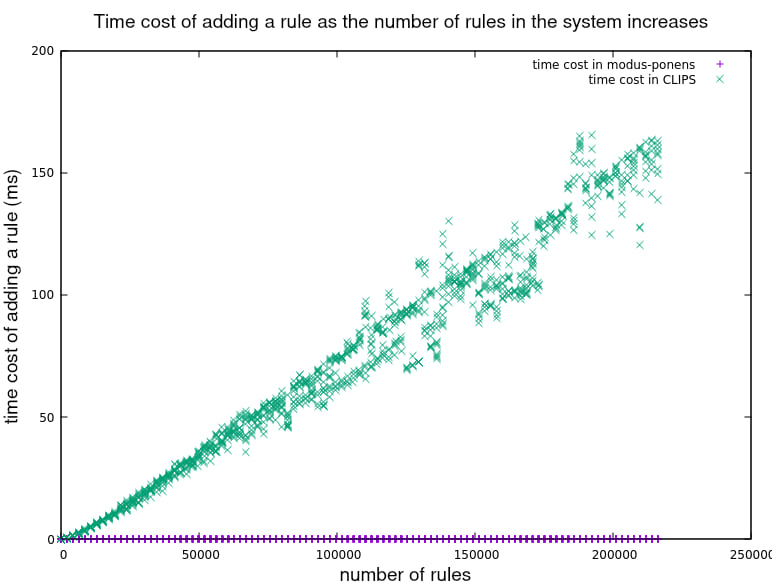
Zooming in on modus_ponens data:
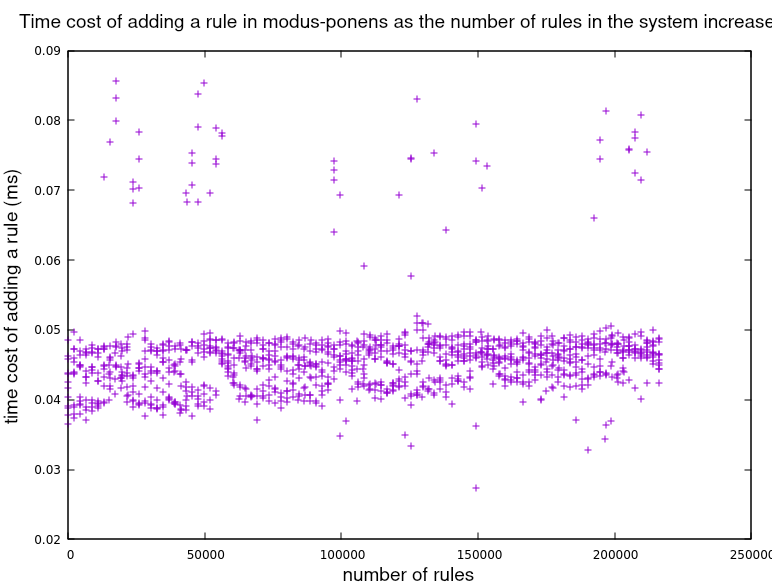
It is worth noting that in modus_ponens, contrary to CLIPS, it is much cheaper adding rules that adding facts.
I also measured the peak memory allocated by the process as measured by heaptrack, with different numbers of facts and rules. I don't have enough data to plot it, but preliminary results show a constant spatial cost per fact of around a KB, independently of the number of facts and rules already in the system. There is room for improvement in this sense, as a KB / fact is way more than strictly needed.
© Enrique Pérez Arnaud <enrique at cazalla.net> 2021
Dependencies
~4–13MB
~150K SLoC