4 releases
| 0.2.4 | Jan 31, 2020 |
|---|---|
| 0.2.3 | Jan 29, 2020 |
| 0.2.2 | Sep 21, 2019 |
| 0.2.1 | Sep 19, 2019 |
#31 in #python-module
2MB
897 lines
![]()
![]()
A hyper-fast, safe Python module to read and write JSON data. Works as a drop-in replacement for Python's built-in json module. This is alpha software and there will be bugs, so maybe don't deploy to production just yet. 😉
Installation
pip install hyperjson
Usage
hyperjson is meant as a drop-in replacement for Python's json module:
>>> import hyperjson
>>> hyperjson.dumps([{"key": "value"}, 81, True])
'[{"key":"value"},81,true]'
>>> hyperjson.loads("""[{"key": "value"}, 81, true]""")
[{u'key': u'value'}, 81, True]
Motivation
Parsing JSON is a solved problem; so, no need to reinvent the wheel, right?
Well, unless you care about performance and safety.
Turns out, parsing JSON correctly is a hard problem. Thanks to Rust however, we can minimize the risk of running into stack overflows or segmentation faults however.
hyperjson is a thin wrapper around Rust's serde-json and pyo3. It is compatible with Python 3 (and 2 on a best-effort basis).
For a more in-depth discussion, watch the talk about this project recorded at the Rust Cologne Meetup in August 2018.
Goals
- Compatibility: Support the full feature-set of Python's
jsonmodule. - Safety: No segfaults, panics, or overflows.
- Performance: Significantly faster than
jsonand as fast asujson(both written in C).
Non-goals
- Support ujson and simplejson extensions:
Custom extensions likeencode(),__json__(), ortoDict()are not supported. The reason is, that they go against PEP8 (e.g.dundermethods are restricted to the standard library, camelCase is not Pythonic) and are not available in Python'sjsonmodule. - Whitespace preservation: Whitespace in JSON strings is not preserved.
Mainly because JSON is a whitespace-agnostic format and
serde-jsonstrips them out by default. In practice this should not be a problem, since your application must not depend on whitespace padding, but it's something to be aware of.
Benchmark
We are not fast yet. That said, we haven't done any big optimizations. In the long-term we might explore features of newer CPUs like multi-core and SIMD. That's one area other (C-based) JSON extensions haven't touched yet, because it might make code harder to debug and prone to race-conditions. In Rust, this is feasible due to crates like faster or rayon.
So there's a chance that the following measurements might improve soon.
If you want to help, check the instructions in the Development Environment section below.
Test machine:
MacBook Pro 15 inch, Mid 2015 (2,2 GHz Intel Core i7, 16 GB RAM) Darwin 17.6.18
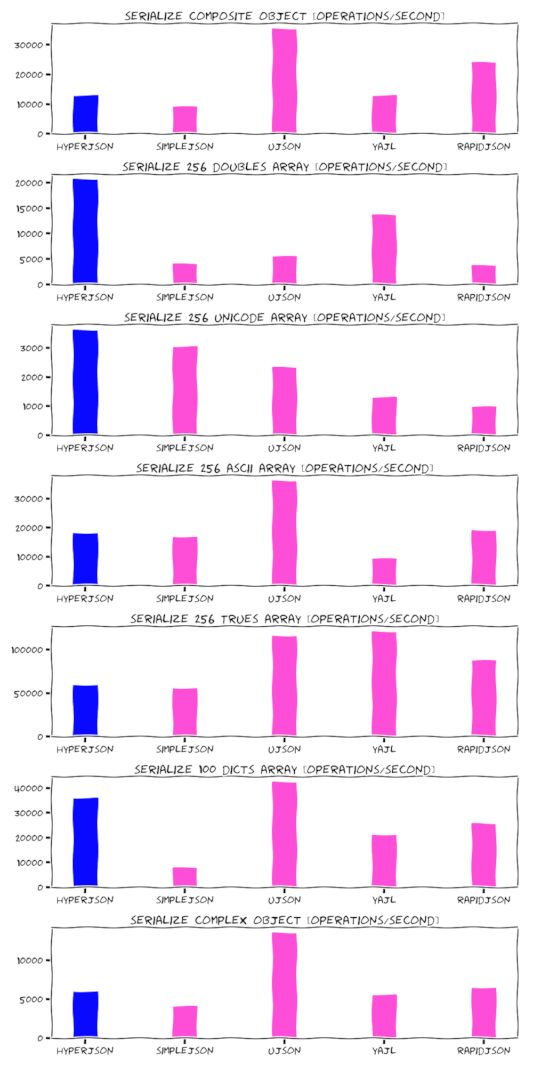
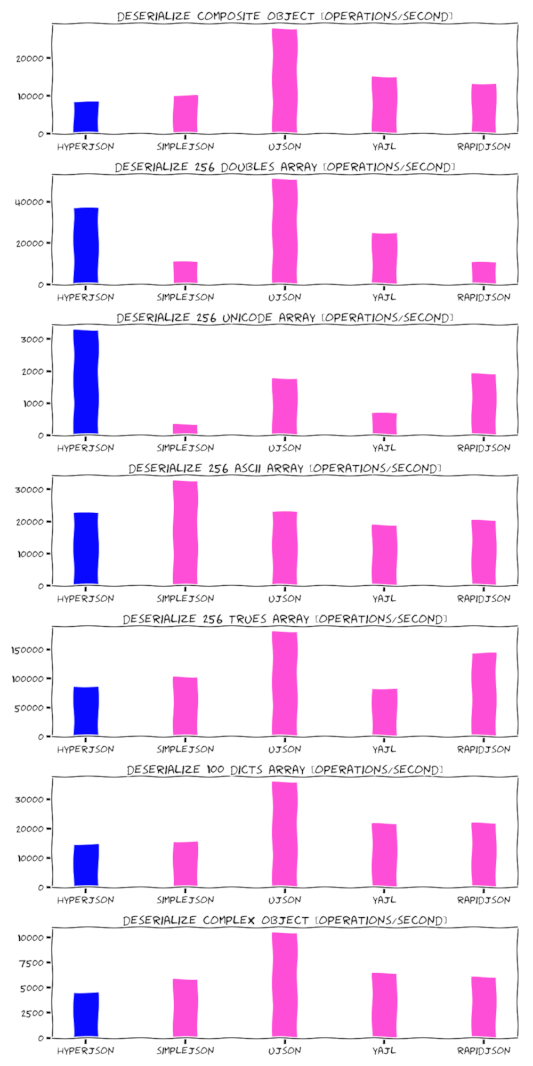
Contributions welcome!
If you would like to hack on hyperjson, here's what needs to be done:
- Implement
loads() - Implement
load() - Implement
dumps() - Implement
dump() - Benchmark against json and ujson (see #1)
- Add a CI/CD pipeline for easier testing (see #2)
- Create a proper pip package from it, to make installing easier (see #3).
- Profile and optimize performance (see #16)
- Add remaining keyword-only arguments to methods
Just pick one of the open tickets. We can provide mentorship if you like. 😃
Developer guide
This project uses pipenv for managing the development environment. If you don't have it installed, run
pip install poetry
The project requires the nightly version of Rust.
Install it via rustup:
rustup install nightly
If you have already installed the nightly version, make sure it is up-to-date:
rustup update nightly
After that, you can compile the current version of hyperjson and execute all tests and benchmarks with the following commands:
make install
make test
make bench
🤫 Pssst!... run make help to learn more.
Drawing pretty diagrams
In order to recreate the benchmark histograms, you first need a few additional prerequisites:
On macOS, please also add the following to your ~/.matplotlib/matplotlibrc (reference):
backend: TkAgg
After that, run the following:
make plot
License
hyperjson is licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in hyperjson by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
Dependencies
~5MB
~109K SLoC