9 releases (5 breaking)
| 0.6.1 | Jun 24, 2024 |
|---|---|
| 0.6.0 | Mar 11, 2024 |
| 0.5.1 | Feb 25, 2024 |
| 0.5.0 | Jan 24, 2024 |
| 0.1.1 | Nov 29, 2023 |
#220 in Data structures
29 downloads per month
Used in flat_bit_set
230KB
4.5K
SLoC
Hierarchical sparse bitset
![]()
![]()
![]()
High performance of operations between bitsets (intersection, union, etc.). Low memory usage.
Think of hibitset, but with lower memory consumption. Unlike hibitset - it is actually sparse - it's memory usage does not depend on max index in set. Only amount of used bitblocks matters (or elements, to put it simply). And like hibitset, it also utilizes hierarchical bitmask acceleration structure to reduce algorithmic complexity on operations between bitsets.
Usage
use hi_sparse_bitset::reduce;
use hi_sparse_bitset::ops::*;
type BitSet = hi_sparse_bitset::BitSet<hi_sparse_bitset::config::_128bit>;
let bitset1 = BitSet::from([1,2,3,4]);
let bitset2 = BitSet::from([3,4,5,6]);
let bitset3 = BitSet::from([3,4,7,8]);
let bitset4 = BitSet::from([4,9,10]);
let bitsets = [bitset1, bitset2, bitset3];
// reduce on bitsets iterator
let intersection = reduce(And, bitsets.iter()).unwrap();
assert_equal(&intersection, [3,4]);
// operation between different types
let union = intersection | &bitset4;
assert_equal(&union, [3,4,9,10]);
// partially traverse iterator, and save position to cursor.
let mut iter = union.iter();
assert_equal(iter.by_ref().take(2), [3,4]);
let cursor = iter.cursor();
// resume iteration from cursor position
let iter = union.iter().move_to(cursor);
assert_equal(iter, [9,10]);
Memory footprint
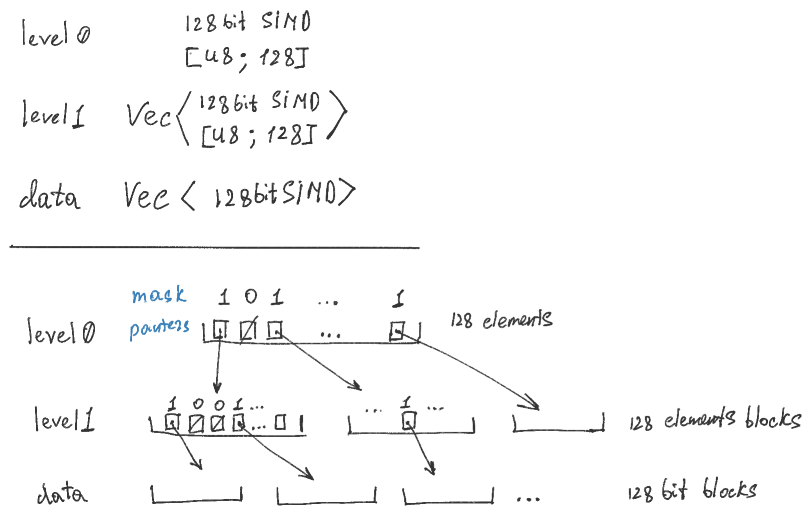
Being truly sparse, hi_sparse_bitset allocate memory only for bitblocks in use.
hi_sparse_bitset::BitSet has tri-level hierarchy, with first and second levels
containing bit-masks and indirection information, and third level - actual bit data.
Currently, whole first level (which is one block itself) and one block from the
second level are always allocated.
Hierarchy-wise memory overhead, for config::_128bit:
minimal(initial) = 416 bytes, maximum = 35 Kb.
SmallBitSet
hi_sparse_bitset::SmallBitSet instead of full-sized array for block pointers
use technique we call "SparseBitMap", which allows to store pointers only to
non-empty blocks.
Thou, this tehcnique introduce some additional performance overhead,
all operations still have O(1) complexity, like BitSet.
Performance
It is faster than hashsets and pure bitsets for all inter-bitset operations and all cases in orders of magnitude. It is even faster than hibitset. See benchmarks.
Against hibitset
Despite the fact that hi_sparse_bitset have layer of indirection for accessing
each level, it is faster (sometimes significantly) then hibitset for all operations.
On top of that, it is also algorithmically faster than hibitset in
non-intersection inter-bitset operations due to caching iterator, which
can skip bitsets with empty level1 blocks.
Against roaring
roaring is a hybrid bitset, that use sorted array of bitblocks for set with large integers,
and big fixed-sized bitset for a small ones.
Let's consider case for intersecting roaring sets, that contain large integers.
In order to find intersection, it binary search for bitblocks with the same start index,
then intersect each bitblock. Operation of binary searching matching bitblock
is algorithmically more complex O(log N), then directly traversing intersected
bitblock in hierarchy, which is close to O(1) for each resulted bitblock.
Plus, hierarchical bitset discard groups of non-intersected blocks
early, due to its tree-like nature.
DataBlock operations
In order to speed up things even more, you can work directly with
DataBlocks. DataBlocks - is a bit-blocks (relatively small in size),
which you can store and iterate latter.
In future versions, you can also insert DataBlocks into BitSet.
Reduce on iterator of bitsets
In addition to "the usual" bitset-to-bitset(binary) operations, you can apply operation to iterator of bitsets (reduce/fold). In this way, you not only apply operation to the arbitrary number of bitsets, but also have the same result type, for any bitsets count. Which allows to have nested reduce operations.
Ordered/sorted
Iteration always return sorted sequences.
Suspend-resume iterator with cursor
Iterators of BitSetInterface (any kind of bitset) can return cursor,
and can rewind to cursor. Cursor is like integer index in Vec.
Which means, that you can use it even if container was mutated.
Multi-session iteration
With cursor you can suspend and later resume your iteration session. For example, you can create an intersection between several bitsets, iterate it to a certain point, and obtain an iterator cursor. Then, later, you can make an intersection between the same bitsets (but possibly in different state), and resume iteration from the last point you stopped, using cursor.
Thread safe multi-session iteration
You can use "multi-session iteration" in multithreaded env too. (By wrapping bitsets in Mutex(es))
Invariant intersection
If intersection of bitsets (or any other operation) does not change with possible bitsets mutations - you're guaranteed to correctly traverse all of its elements.
Bitsets mutations narrows intersection/union
If in intersection, only remove operation mutates bitsets - this guarantees that you will not loose any valid elements at the end of "multi-session iteration".
Speculative iteration
For other cases - you're guaranteed to proceed forward, without repeated elements. (In each iteration session you'll see initial valid elements + some valid new ones) You can use this if you don't need to traverse EXACT intersection. For example, if you process intersection of the same bitsets over and over in a loop.
Changelog
See CHANGELOG.md for version differences.
Known alternatives
-
hibitset - hierarchical dense bitset. If you'll insert one index = 16_000_000, it will allocate 2Mb of RAM. It uses 4-level hierarchy, and being dense - does not use indirection. This makes it hierarchy overhead smaller, and on intersection operations it SHOULD perform better - but it doesn't (probably because of additional level of hierarchy, or some implementation details).
-
bitvec - pure dense bitset. Plain operations (insert/contains) should be reasonably faster (not at magnitude scale). Inter-bitset operations - super-linearly slower for the worst case (which is almost always), and have approx. same performance for the best case (when each bitset block used). Have no memory overhead per-se, but memory usage depends on max int in bitset, so if you do not need to perform inter-bitset operations, and know that your indices are relatively small numbers, or expect bitset to be densely populated - this is a good choice.
-
HashSet<usize>- you should use it only if you work with a relatively small set with extremely large numbers. It is orders of magnitude slower for inter-set operations. And "just" slower for the rest ones. -
roaring - compressed hybrid bitset. Higher algorithmic complexity of operations, but theoretically unlimited range. It is still super-linearly faster than pure dense bitsets and hashsets in inter-set operations. See performance section for detais.
Dependencies
~215KB