25 releases (2 stable)
| 1.0.1 | Feb 28, 2025 |
|---|---|
| 0.11.3 | Jan 26, 2023 |
| 0.11.1 | Dec 12, 2022 |
| 0.11.0 | Nov 29, 2022 |
| 0.9.2 | Oct 17, 2021 |
#19 in Compression
41,823 downloads per month
Used in 34 crates
(23 directly)
2MB
3K
SLoC
⛓️gzp
![]()
![]()
![]()
Multi-threaded encoding and decoding.
Why?
This crate provides a near drop in replacement for Write that has will compress chunks of data in parallel and write
to an underlying writer in the same order that the bytes were handed to the writer. This allows for much faster
compression of data.
Additionally, this provides multi-threaded decompressors for Mgzip and BGZF formats.
Supported Encodings:
- Gzip via flate2
- Zlib via flate2
- Raw Deflate via flate2
- Snappy via rust-snappy
- BGZF block compression format limited to 64 Kb blocks
- Mgzip block compression format with no block size limit
Usage / Features
By default gzp has the deflate_default and libdeflate features enabled which brings in the best performing zlib
implementation as the backend for flate2 as well as libdeflater for the block gzip formats.
Examples
- Deflate default
[dependencies]
gzp = { version = "*" }
- Rust backend, this means that the
Zlibformat will not be available.
[dependencies]
gzp = { version = "*", default-features = false, features = ["deflate_rust"] }
- Snap only
[dependencies]
gzp = { version = "*", default-features = false, features = ["snap_default"] }
Note: if you are running into compilation issues with libdeflate and the i686-pc-windows-msvc target, please see this issue for workarounds.
Examples
Simple example
use std::{env, fs::File, io::Write};
use gzp::{deflate::Gzip, ZBuilder, ZWriter};
fn main() {
let mut writer = vec![];
// ZBuilder will return a trait object that transparent over `ParZ` or `SyncZ`
let mut parz = ZBuilder::<Gzip, _>::new()
.num_threads(0)
.from_writer(writer);
parz.write_all(b"This is a first test line\n").unwrap();
parz.write_all(b"This is a second test line\n").unwrap();
parz.finish().unwrap();
}
An updated version of pgz.
use gzp::{
ZWriter,
deflate::Mgzip,
par::{compress::{ParCompress, ParCompressBuilder}}
};
use std::io::{Read, Write};
fn main() {
let chunksize = 64 * (1 << 10) * 2;
let stdout = std::io::stdout();
let mut writer: ParCompress<Mgzip> = ParCompressBuilder::new().from_writer(stdout);
let stdin = std::io::stdin();
let mut stdin = stdin.lock();
let mut buffer = Vec::with_capacity(chunksize);
loop {
let mut limit = (&mut stdin).take(chunksize as u64);
limit.read_to_end(&mut buffer).unwrap();
if buffer.is_empty() {
break;
}
writer.write_all(&buffer).unwrap();
buffer.clear();
}
writer.finish().unwrap();
}
Same thing but using Snappy instead.
use gzp::{parz::{ParZ, ParZBuilder}, snap::Snap};
use std::io::{Read, Write};
fn main() {
let chunksize = 64 * (1 << 10) * 2;
let stdout = std::io::stdout();
let mut writer: ParZ<Snap> = ParZBuilder::new().from_writer(stdout);
let stdin = std::io::stdin();
let mut stdin = stdin.lock();
let mut buffer = Vec::with_capacity(chunksize);
loop {
let mut limit = (&mut stdin).take(chunksize as u64);
limit.read_to_end(&mut buffer).unwrap();
if buffer.is_empty() {
break;
}
writer.write_all(&buffer).unwrap();
buffer.clear();
}
writer.finish().unwrap();
}
Acknowledgements
- Many of the ideas for this crate were directly inspired by
pigz, including implementation details for some functions.
Contributing
PRs are very welcome! Please run tests locally and ensure they are passing. May tests are ignored in CI because the CI instances don't have enough threads to test them / are too slow.
cargo test --all-features && cargo test --all-features -- --ignored
Note that tests will take 30-60s.
Future todos
- Pull in an adler crate to replace zlib impl (need one that can combine values, probably implement COMB from pigz).
- Add more metadata to the headers
- Return an auto-generated index for BGZF / Mgzip formats
- Try with https://docs.rs/lzzzz/0.8.0/lzzzz/lz4_hc/fn.compress.html
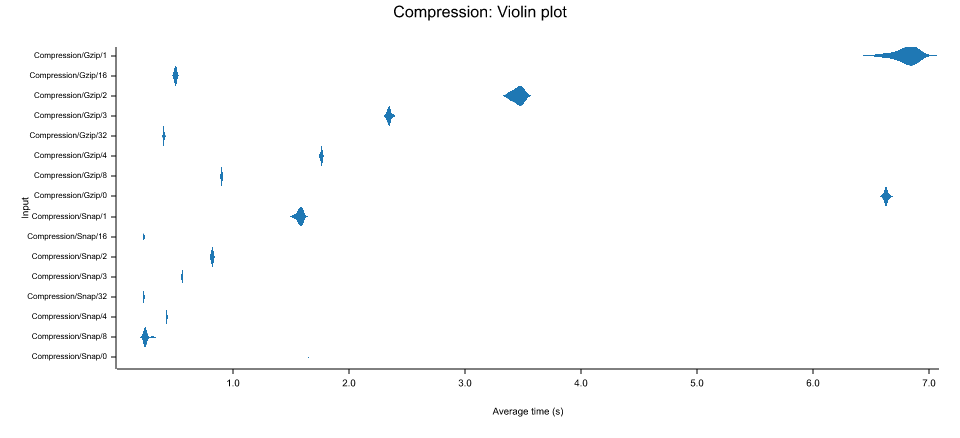
Benchmarks
All benchmarks were run on the file in ./bench-data/shakespeare.txt catted together 100 times which creates a rough
550Mb file.
The primary benchmark takeaway is that compression time decreases proportionately to the number of threads used.
Dependencies
~1.3–2.8MB
~51K SLoC