20 unstable releases (4 breaking)
Uses new Rust 2024
| 0.9.2 | Feb 23, 2025 |
|---|---|
| 0.9.1 | Dec 16, 2024 |
| 0.9.0 | Nov 14, 2024 |
| 0.6.6 | Jul 16, 2024 |
| 0.5.3 | Feb 25, 2023 |
#275 in Command line utilities
1,127 downloads per month
190KB
417 lines
findlargedir
![]()
![]()
![]()

(Ferris the Detective by Esther Arzola, original design by Karen Rustad Tölva)
About
Findlargedir is a tool specifically written to help quickly identify "black hole" directories on an any filesystem having more than 100k entries in a single flat structure. When a directory has many entries (directories or files), getting directory listing gets slower and slower, impacting performance of all processes attempting to get a directory listing (for instance to delete some files and/or to find some specific files). Processes reading large directory inodes get frozen while doing so and end up in the uninterruptible sleep ("D" state) for longer and longer periods of time. Depending on the filesystem, this might start to become visible with 100k entries and starts being a very noticeable performance impact with 1M+ entries.
Such directories mostly cannot shrink back even if content gets cleaned up due to the fact that most Linux and Un*x filesystems do not support directory inode shrinking (for instance very common ext3/ext4). This often happens with forgotten Web sessions directory (PHP sessions folder where GC interval was configured to several days), various cache folders (CMS compiled templates and caches), POSIX filesystem emulating object storage, etc.
Program will attempt to identify any number of such events and report on them based on calibration, ie. how many assumed directory entries are packed in each directory inode for each filesystem. While doing so, it will determine directory inode growth ratio to number of entries/inodes and will use that ratio to quickly scan filesystem, avoiding doing expensive/slow directory lookups. While there are many tools that scan the filesystem (find, du, ncdu, etc.), none of them use heuristics to avoid expensive lookups, since they are designed to be fully accurate, while this tool is meant to use heuristics and alert on issues without getting stuck on problematic folders.
Program will not follow symlinks and requires r/w permissions to calibrate directory to be able to calculate a directory inode size to number of entries ratio and estimate a number of entries in a directory without actually counting them. While this method is just an approximation of the actual number of entries in a directory, it is good enough to quickly scan for offending directories.
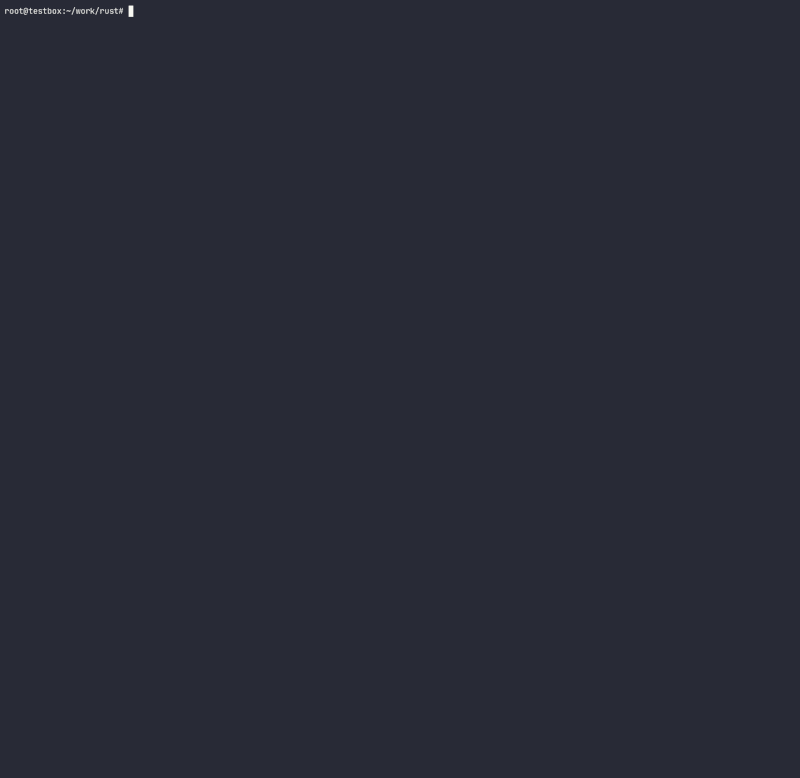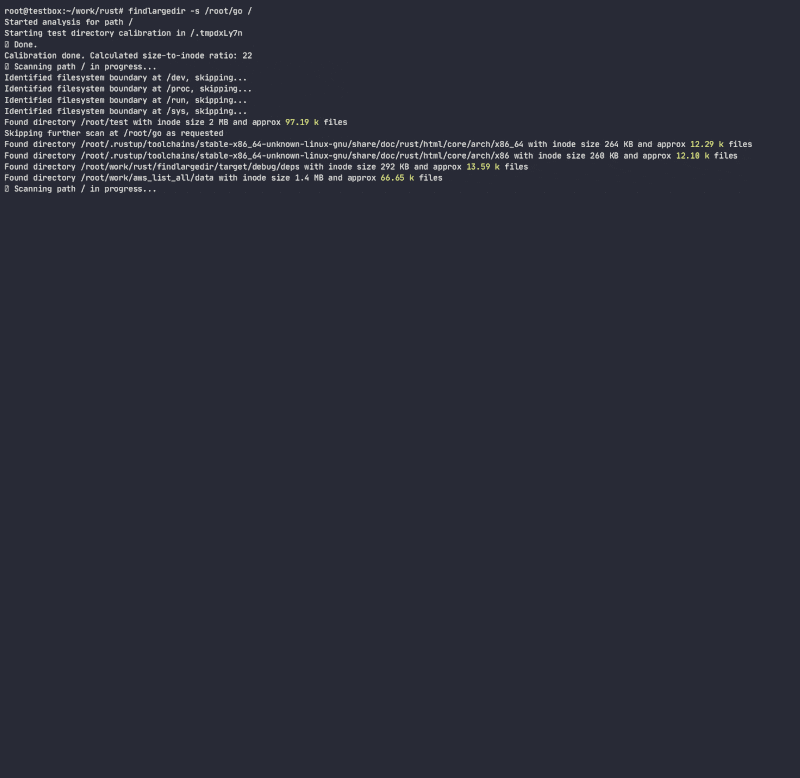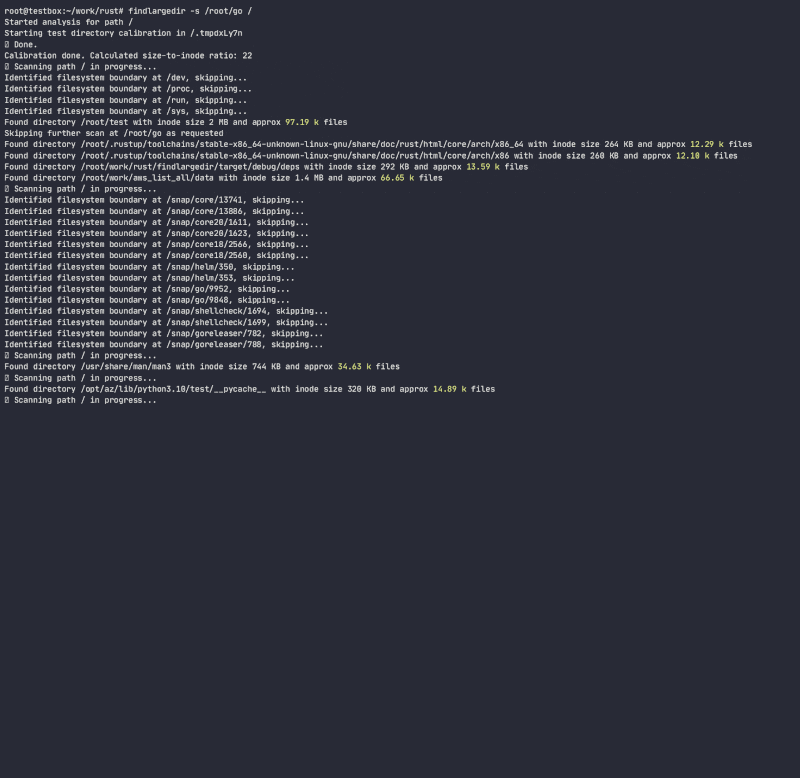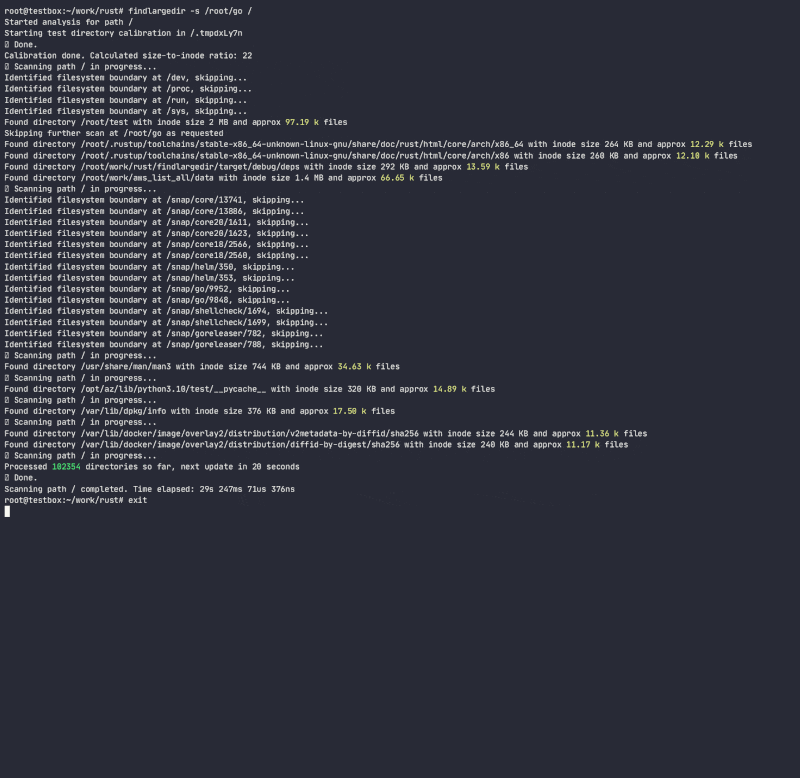
Caveats
- requires r/w privileges for an each filesystem being tested, it will also create a temporary directory with a lot of temporary files which are cleaned up afterwards
- accurate mode (
-a) can cause an excessive I/O and an excessive memory use; only use when appropriate
Usage
Usage: findlargedir [OPTIONS] <PATH>...
Arguments:
<PATH>... Paths to check for large directories
Options:
-a, --accurate <ACCURATE>
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem <ONE_FILESYSTEM>
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count <CALIBRATION_COUNT>
Calibration directory file count [default: 100000]
-A, --alert-threshold <ALERT_THRESHOLD>
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold <BLACKLIST_THRESHOLD>
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads <THREADS>
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates <UPDATES>
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio <SIZE_INODE_RATIO>
Skip calibration and provide directory entry to inode size ratio (typically ~21-32) [default: 0]
-t, --calibration-path <CALIBRATION_PATH>
Custom calibration directory path
-s, --skip-path <SKIP_PATH>
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information
When using accurate mode (-a parameter) beware that large directory lookups will stall the process completely for extended periods of time. What this mode does is basically a secondary fully accurate pass on a possibly offending directory calculating exact number of entries.
To avoid descending into mounted filesystems (as in find -xdev option), parameter one-filesystem mode (-o parameter) is toggled by default, but it can be disabled if necessary.
It is possible to completely skip calibration phase by manually providing directory inode size to number of entries ratio with -i parameter. It makes sense only when you already know the ratio, for example from previous runs.
Setting -p paramter to 0 will stop program from giving occasional status updates.
Benchmarks
Findlargedir vs GNU find
Mid-range server / mechanical storage
Hardware: 8-core Xeon E5-1630 with 4-drive SATA RAID-10
Benchmark setup:
$ cat bench1.sh
#!/bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#!/bin/dash
exec /usr/local/sbin/findlargedir /
Actual results measured with hyperfine:
$ hyperfine --prepare 'echo 3 | tee /proc/sys/vm/drop_caches' \
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
'./bench2.sh' ran
1.79 ± 0.05 times faster than './bench1.sh'
High-end server / SSD storage
Hardware: 48-core Xeon Silver 4214, 7-drive SM883 SATA HW RAID-5 array, 2TB content (dozen of containers with small files)
Same benchmark setup. Results:
$ hyperfine --prepare 'echo 3 | tee /proc/sys/vm/drop_caches' \
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
'./bench2.sh' ran
11.33 ± 0.16 times faster than './bench1.sh'
Star history

Dependencies
~12–24MB
~358K SLoC