1 unstable release
| 0.1.0 | Oct 22, 2024 |
|---|
#435 in Concurrency
89KB
1.5K
SLoC
congestion-limiter
Dynamic congestion-based concurrency limits for controlling backpressure.
What is this?
A Rust library to dynamically control concurrency limits. Several algorithms are included, mostly based on TCP congestion control. These detect signs of congestion or overload by observing and reacting to either latency (delay) or load-based failures (loss), respectively. Beyond the limit, additional requests to perform work can be rejected. These rejections can be detected by upstream limiters as load-based failures, acting as an effective form of backpressure.
In general, systems serving clients by doing jobs have a finite number of resources. For example, an HTTP server might have 4 CPU cores available. When these resources become heavily utilised, queues begin to form, and job latency increases. If these queues continue to grow, the system becomes effectively overloaded and unable to respond to job requests in a reasonable time.
These systems can only process so many jobs concurrently. For a purely CPU-bound job, the server above might only be able to process about 4 jobs concurrently. Reality is much more complex, however, and therefore this number is much harder to predict.
Concurrency limits can help protect a system from becoming overloaded, and these limits can be automatically set by observing and responding to the behaviour of the system.
See background for more details.
Goals
This library aims to:
- Achieve optimally high throughput and low latency.
- Shed load and apply backpressure in response to congestion or overload.
- Fairly distribute available resources between independent clients with zero coordination.
Limit algorithms
The congestion-based algorithms come in several flavours:
- Loss-based – respond to failed jobs (i.e. overload). Feedback can be implicit (e.g. a timeout) or explicit (e.g. an HTTP 429 or 503 status).
- Delay-based – respond to increases in latency (i.e. congestion). Feedback is implicit.
| Algorithm | Feedback | Response | Fairness |
|---|---|---|---|
| AIMD | Loss | AIMD | Fair, but can out-compete delay-based algorithms |
| Gradient | Delay | AIMD | TODO: ? |
| Vegas | Loss and delay | AIAD (AIMD for loss) | Proportional until overload (loss) |
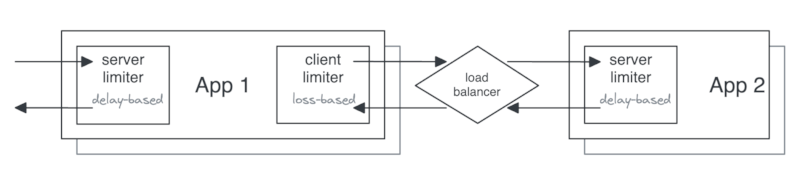
Example topology
The example below shows two applications using limiters on the client (output) and on the server (input), using different algorithms for each.
Caveats
- Loss-based algorithms require a reliable signal for load-based errors.
- If configured to reduce concurrency for non-load-based errors, they can exacerbate availability problems when these errors occur.
- Delay-based algorithms work more reliably with predictable latency.
- For example, short bursts of increased latency from GC pauses could cause an outsized reduction in concurrency limits.
- Windowing can help with this.
- Cold-start problem: capacity limits are not known at start up.
- There's a need to probe to discover this. Requests could be unnecessarily limited until the limit is increased to match capacity.
- Can be mitigated with single immediate retries (from a token bucket?) on the client, which might get load balanced to a server with available capacity.
FAQ
Does this require coordination between multiple processes?
No! The congestion avoidance is based on TCP congestion control algorithms which are designed to work independently. In TCP, each transmitting socket independently detects congestion and reacts accordingly.
Installing, running and testing
TODO:
Example
use std::sync::Arc;
use congestion_limiter::{limits::Aimd, limiter::{DefaultLimiter, Limiter, Outcome}};
// A limiter shared between request handler invocations.
// This controls the concurrency of incoming requests.
let limiter = Arc::new(DefaultLimiter::new(
Aimd::new_with_initial_limit(10)
.with_max_limit(20)
.decrease_factor(0.9)
.increase_by(1),
));
// A request handler
tokio_test::block_on(async move {
// On request start
let token = limiter.try_acquire()
.await
.expect("Do some proper error handling instead of this...");
// Do some work...
// On request finish
limiter.release(token, Some(Outcome::Success)).await;
});
Prior art
Further reading
- Wikipedia -- TCP congestion control
- AWS -- Using load shedding to avoid overload
- Sarah-Marie Nothling -- Load Series: Throttling vs Loadshedding
- Myntra Engineering -- Adaptive Throttling of Indexing for Improved Query Responsiveness
- TCP Congestion Control: A Systems Approach
- LWN -- Delay-gradient congestion control (CDG)
- Strange Loop -- Stop Rate Limiting! Capacity Management Done Right
- Marc Brooker -- Telling Stories About Little's Law
- Queuing theory: Definition, history & real-life applications & examples
License
Licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
Dependencies
~2.3–8.5MB
~63K SLoC