6 releases (2 stable)
| 1.1.0 | Nov 21, 2021 |
|---|---|
| 1.0.0 | Nov 1, 2021 |
| 0.0.6 | Oct 28, 2021 |
#1632 in Data structures
28 downloads per month
27KB
476 lines
Swap Queue
![]()
![]()
![]()
![]()
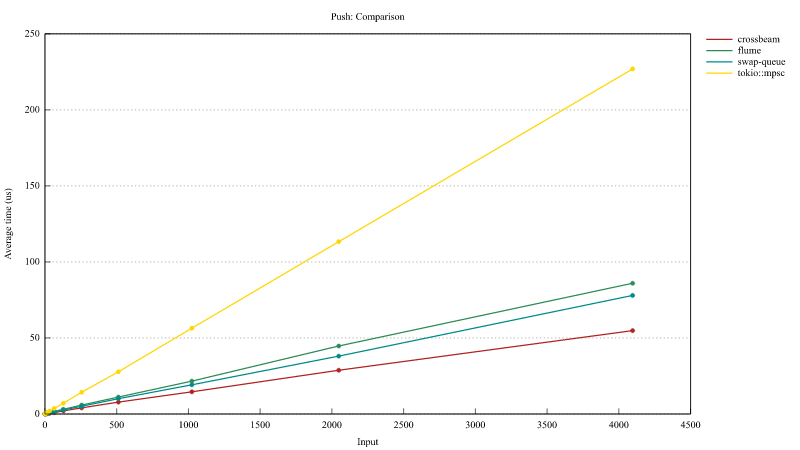
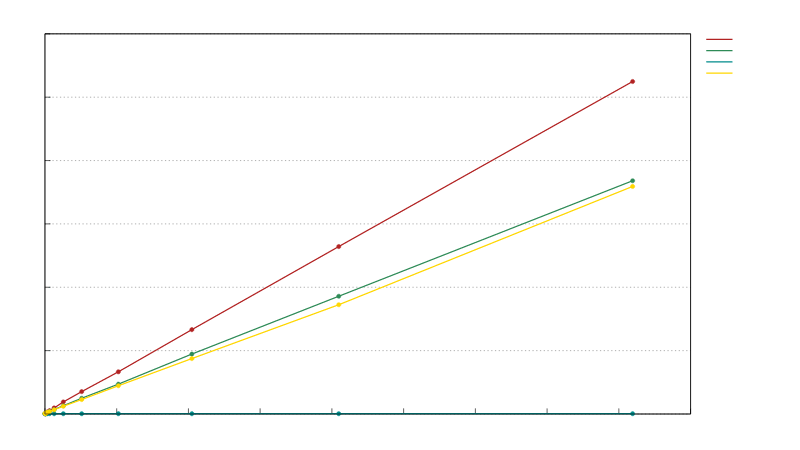
A lock-free thread-owned queue whereby tasks are taken by stealers in entirety via buffer swapping. For batching use-cases, this has the advantage that all tasks can be taken as a single batch in constant time irregardless of batch size, whereas alternatives using crossbeam_deque::Worker and tokio::sync::mpsc need to collect each task separately and situationally lack a clear cutoff point. This design ensures that should you be waiting on a resource such as a connection to be available, that once it is so there is no further delay before a task batch can be processed. While push behavior alone is slower than crossbeam_deque::Worker and faster than tokio::sync::mpsc, overall batching performance is around ~11-19% faster than crossbeam_deque::Worker, and ~28-45% faster than tokio::sync::mpsc on ARM and there is never a slow cutoff between batches.
Example
use swap_queue::Worker;
use tokio::{
runtime::Handle,
sync::oneshot::{channel, Sender},
};
// Jemalloc makes this library substantially faster
#[global_allocator]
static GLOBAL: jemallocator::Jemalloc = jemallocator::Jemalloc;
// Worker needs to be thread local because it is !Sync
thread_local! {
static QUEUE: Worker<(u64, Sender<u64>)> = Worker::new();
}
// This mechanism will batch optimally without overhead within an async-context because spawn will happen after things already scheduled
async fn push_echo(i: u64) -> u64 {
{
let (tx, rx) = channel();
QUEUE.with(|queue| {
// A new stealer is returned whenever the buffer is new or was empty
if let Some(stealer) = queue.push((i, tx)) {
Handle::current().spawn(async move {
// Take the underlying buffer in entirety; the next push will return a new Stealer
let batch = stealer.take().await;
// Some sort of batched operation, such as a database query
batch.into_iter().for_each(|(i, tx)| {
tx.send(i).ok();
});
});
}
});
rx
}
.await
.unwrap()
}
Benchmarks
Benchmarks ran on t4g.medium using ami-06391d741144b83c2
Async Batching
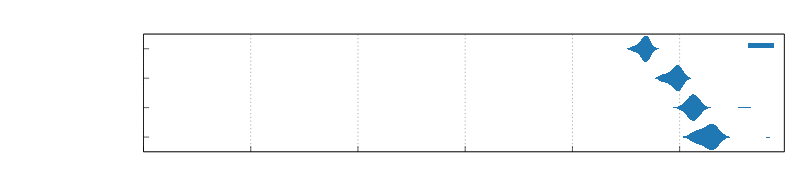
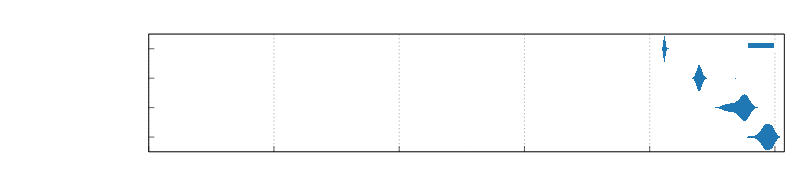
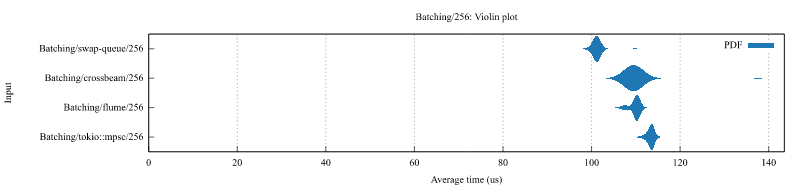
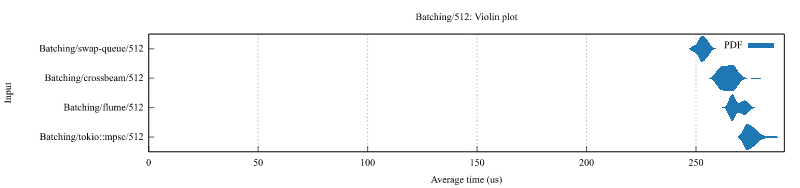
Push
Batch collecting
CI tested under ThreadSanitizer, LeakSanitizer, Miri and Loom.
Dependencies
~3–28MB
~369K SLoC