3 releases
| 0.0.12 | Sep 28, 2022 |
|---|---|
| 0.0.11 | Sep 28, 2022 |
| 0.0.1 | Sep 28, 2022 |
#608 in Concurrency
20KB
352 lines
Atom
This is an experimental implementation, meaning API might change and bugs might arise.
Experimental API for a synchronous and mutable smart-pointer type Atom<T> and its Weak<T> variant. Also includes the associated spin-lock type SpinLock.
Unlike Mutex<T>, Atom<T> does not use system futexes, but instead uses a simple spin-lock. This can be advantageous in cases of low contention i.e. when the lock is only held for a short time and there are few threads competing for the lock.
Usage
Atom<T> mimics the behavior of Arc<Mutex<T>>, but with a slightly different API. Instead
of lock-guards we simply access the inner T inside a closure.
let atom = Atom::new(5);
atom.lock(|x| *x += 5);
assert_eq!(atom.get(), 10);
We can access parts of the inner value and map parts of it to a new value:
let atom = Atom::new(vec![1, 2, 3]);
let sum: i32 = atom.map(|x| x.iter().sum());
assert_eq!(sum, 6);
Or mutate and map:
let atom = Atom::new(vec![1, 2, 3]);
let three = atom.map_mut(|x| x.pop());
assert_eq!(three, Some(3));
assert_eq!(atom.get(), vec![1, 2]);
Example
use spinout::Atom;
fn main() {
let mut numbers = vec![];
for i in 1..43 {
numbers.push(i);
}
let numbers = Atom::new(numbers);
let t1_numbers = numbers.clone();
let t2_numbers = numbers.clone();
let results = Atom::new(vec![]);
let t1_results = results.clone();
let t2_results = results.clone();
let t1 = std::thread::spawn(move || {
while let Some(x) = t1_numbers.map_mut(|x| x.pop()) {
if x % 2 == 0 {
t1_results.lock(|v| v.push(x));
}
}
});
let t2 = std::thread::spawn(move || {
while let Some(x) = t2_numbers.map_mut(|x| x.pop()) {
if x % 2 == 0 {
t2_results.lock(|v| v.push(x));
}
}
});
t1.join().unwrap();
t2.join().unwrap();
let mut results = results.get();
results.sort();
let expected = [
2, 4, 6, 8, 10, 12, 14, 16,
18, 20, 22, 24, 26, 28, 30,
32, 34, 36, 38, 40, 42
];
assert_eq!(results, expected);
}
Benchmarks
These tests we run on a AMD Ryzen 3 3100 4-Core Processor using the Criterion statistical benchmarking tool.
There are four different tests that simulate a real world scenario with a small thread count and low contention.
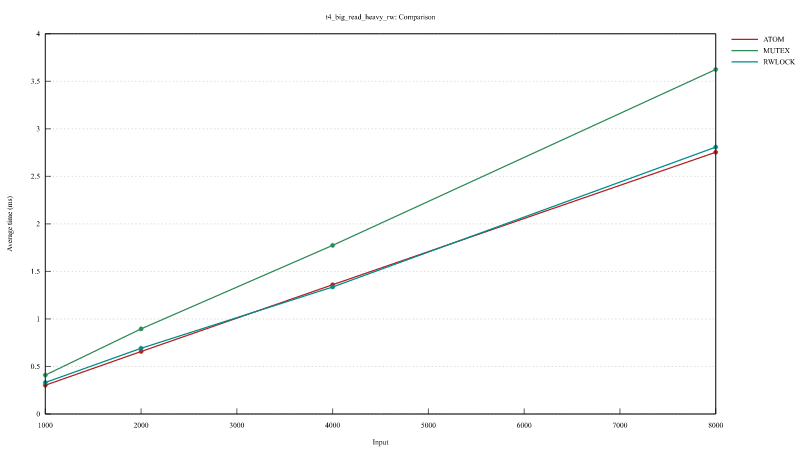
In the Balanced Read and Write and Read Heavy Read and Write we do a sort on a small vector and read the biggest value from the (reversed) vector.
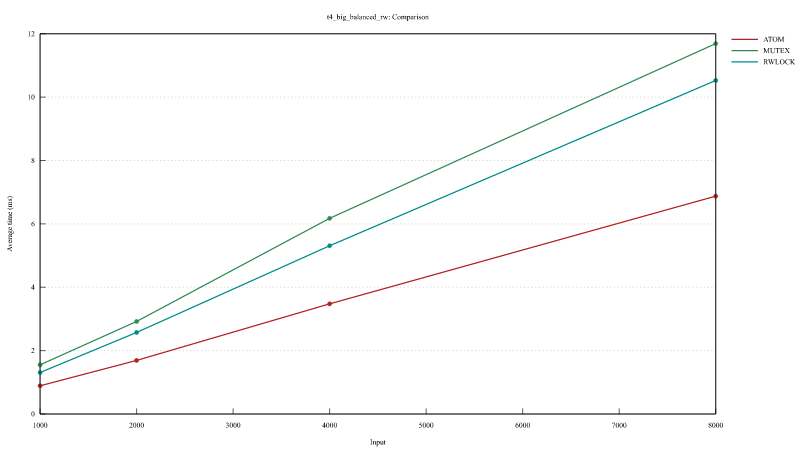
In Write Only only test we do a sort and a reverse on a small vector.
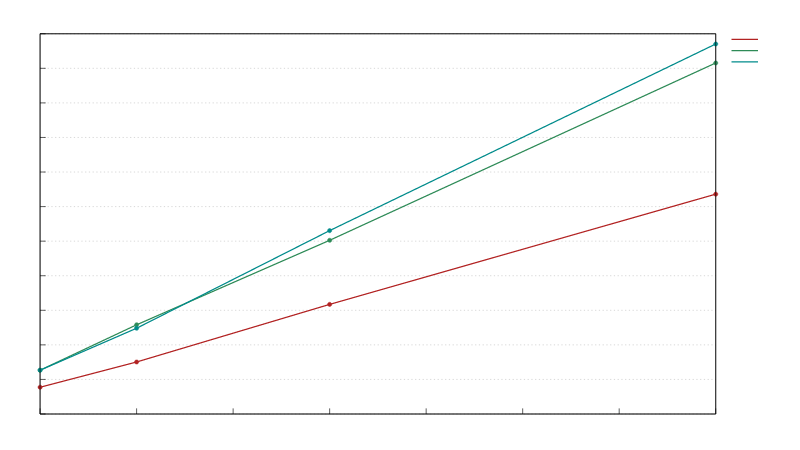
In the Read Only test we do a find on a value in the vector.