2 stable releases
| 1.0.1 | Jul 19, 2024 |
|---|---|
| 0.1.0 |
|
#787 in Encoding
1,710 downloads per month
Used in 19 crates
(2 directly)
315KB
545 lines
simd_cesu8 


An extremely fast, SIMD-accelerated, encoding and decoding library for CESU-8 and Modified UTF-8.
Features
- Extremely fast encoding and decoding of CESU-8 and Modified UTF-8.
- Only allocates memory when absolutely necessary. Zero reallocations.
- Supports lossy decoding of CESU-8 and MUTF-8.
- Supports strict decoding of CESU-8 and MUTF-8.
- Up to 25 times faster than known alternatives when encoding.
- Up to 14 times faster than known alternatives when decoding.
- Supports AVX 2 and SSE 4.2 implementations on x86 and x86-64.
- ARM64 (aarch64) SIMD is supported.
- WASM (wasm32) SIMD is supported.
- PowerPC (powerpc) SIMD is (partially) supported.
- Falls back to word-at-a-time implementations instead of byte-at-a-time.
- No-std support.
Usage
Add this to your Cargo.toml file:
[dependencies.simd_cesu8]
version = "1"
features = ["nightly"]
It is extremely recommended to use the nightly feature, as it enables the fastest implementations of the library. If you don't want to use nightly, you can remove the feature and the library will still work, but will be slower.
Documentation
The documentation can be found on docs.rs.
For quick access to certain functions, I highly recommend pressing the "All Items" button in the top left corner of the documentation page.
MSRV
The minimum supported Rust version is 1.79.0.
Benchmarks
These benchmarks were run with an AMD Ryzen 9 7950X3D on WSL2 with Rust
1.81.0-nightly. Each of the operations were measured with an input exactly equal
to 16,380 bytes. Data sets were randomly generated with the same seed for each
operation. Each set contained 1,000 values, that were endlessly repeated as
input. The benchmarks were run with the criterion crate. The tables got
created via critcmp. The source code for the benchmarks can be found in the
benches directory. Any call to simd_cesu8 was replaced with the cesu8
equivalent when collecting the data for the cesu8 benchmarks. The data
collected can also be found in the benches directory.
We compare simd_cesu8 to the cesu8 library, as it's the most popular
library for CESU-8 and MUTF-8 encoding and decoding in Rust. I originally
started this project, however, because there's a few minor semantic errors in
the cesu8 library that I wanted to fix myself.
Encoding
To understand the benchmarks, it's first a good idea to familiarize yourself with the datasets used to benchmark the encoding operations:
ascii_non_null_stringsare strings exactly 16,380 bytes long with only ASCII characters and no null bytes.ascii_null_alternating_stringsare strings exactly 16,380 bytes long with only ASCII characters and null bytes alternating, where every odd byte is non-null and every even byte is null.interspersed_stringsare strings exactly 16,380 bytes long with every 20 bytes in the following pattern:- A non-null ASCII character (1 byte)
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character
- A null byte
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character
null_stringsare strings exactly 16,380 bytes long with only null bytes.utf8_clamped_width_2_stringsare strings exactly 16,380 bytes long with only 2-byte UTF-8 characters.utf8_clamped_width_3_stringsare strings exactly 16,380 bytes long with only 3-byte UTF-8 characters.utf8_clamped_width_4_stringsare strings exactly 16,380 bytes long with only 4-byte UTF-8 characters.
simd_cesu8::encode
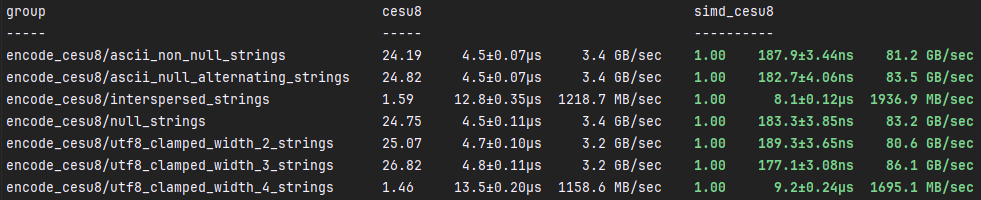
simd_cesu8::encode is around %2,500 faster than cesu8::to_cesu8 in optimal
conditions. In suboptimal conditions, simd_cesu8::encode is around %50 faster
than cesu8::to_cesu8. The main reason for the speedup, beyond SIMD, is
that simd_cesu8 doesn't quickly check for just ASCII characters, but instead,
it checks for the start of 4-byte characters. This is a significant speedup over
the traditional ASCII hot paths. Other speedups come in the form of cumulative,
tiny optimizations that add up to a significant speedup.
simd_cesu8::mutf8::encode
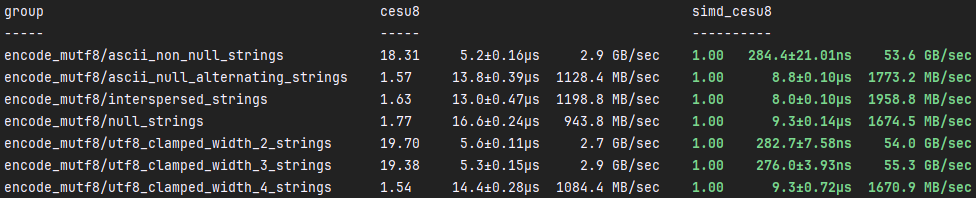
Similar to simd_cesu8::encode, simd_cesu8::mutf8::encode is around %1800
faster than cesu8::to_java_cesu8 in optimal conditions. In suboptimal
conditions, simd_cesu8::mutf8::encode is around %50 faster than
cesu8::to_java_cesu8. The same reason for the speedup applies here, but
instead of checking for the start of 4-byte characters, we're also checking for
any null bytes with SIMD. Other speedups come in the form of cumulative, tiny
optimizations that add up to a significant speedup.
Decoding
To understand the benchmarks, it's first a good idea to familiarize yourself with the datasets used to benchmark the decoding operations:
ascii_non_null_bytesis a set of UTF-8 strings exactly 16,380 bytes long with only ASCII characters and no null bytes.ascii_null_alternating_bytesis a set of UTF-8 strings exactly 16,380 bytes long with only ASCII characters and null bytes alternating, where every odd byte is non-null and every even byte is null.interspersed_bytesis a set of UTF-8 strings exactly 16,380 bytes long with every 20 bytes in the following pattern:- A non-null ASCII character (1 byte)
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character
- A null byte
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character
interspersed_cesu8_bytesis a set of CESU-8 strings exactly 16,380 bytes long with every 12 bytes in the following pattern:- An ASCII character (1 byte)
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character encoded as a surrogate pair (6 bytes)
interspersed_mutf8_bytesis a set of MUTF-8 strings exactly 16,380 bytes long with every 26 bytes in the following pattern:- A non-null ASCII character (1 byte)
- A non-null ASCII character (1 byte)
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character encoded as a surrogate pair (6 bytes)
- A null byte encoded as a 2-byte sequence
- A 2-byte UTF-8 character
- A 3-byte UTF-8 character
- A 4-byte UTF-8 character encoded as a surrogate pair (6 bytes)
mutf8_null_bytesis a set of MUTF-8 strings exactly 16,380 bytes long with only null encoded as a 2-byte sequence.null_bytesis a set of UTF-8 strings exactly 16,380 bytes long with only null bytes.surrogate_pairs_bytesis a set of CESU-8 strings exactly 16,380 bytes long with only 6-byte surrogate pairs.utf8_clamped_width_2_bytesis a set of UTF-8 strings exactly 16,380 bytes long with only 2-byte UTF-8 characters.utf8_clamped_width_3_bytesis a set of UTF-8 strings exactly 16,380 bytes long with only 3-byte UTF-8 characters.utf8_clamped_width_4_bytesis a set of UTF-8 strings exactly 16,380 bytes long with only 4-byte UTF-8 characters.
simd_cesu8::decode
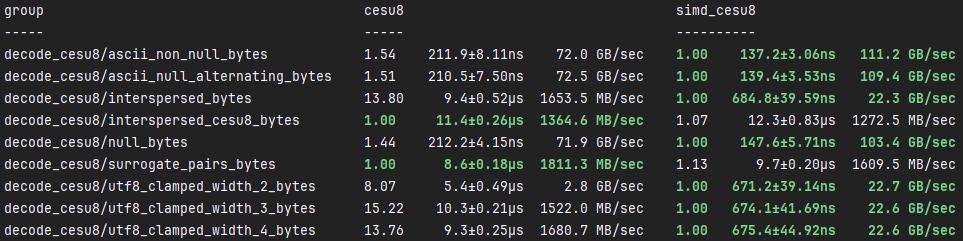
In optimal conditions, simd_cesu8::decode can be around %1,400 faster than
cesu8::to_cesu8. However, simd_cesu8::decode is slower
than cesu8::to_cesu8 when decoding surrogate pairs. The main reason is
that simd_cesu8 supports lossy decoding, but the internals of that seems to
introduce a decent amount of overhead. simd_cesu8 is faster in all ways
that cesu8 when LTO is enabled. However, I didn't run the benchmarks with
LTO enabled because it seems disingenuous to do so as LTO shouldn't be a
requirement for a library to be fast.
simd_cesu8::mutf8::decode
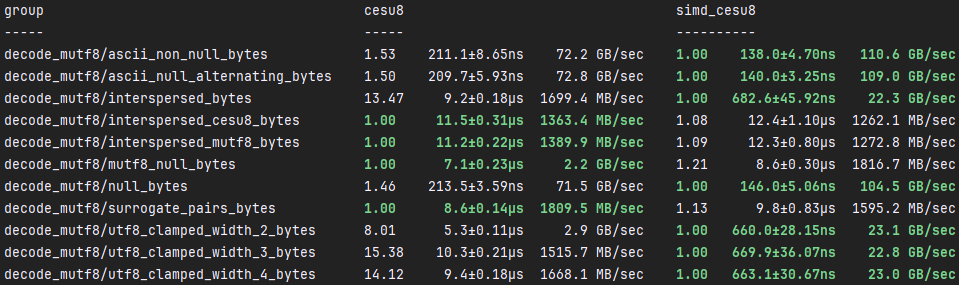
Much like simd_cesu8::decode, simd_cesu8::mutf8::decode can be around %1,400
faster than cesu8::to_java_cesu8. But, the pitfalls are equally the same, as
simd_cesu8::mutf8::decode is slower than cesu8::to_java_cesu8 when decoding
surrogate pairs. The other catch is that we're slightly slower than cesu8 when
decoding null bytes. The same reasoning applies here, as the overhead is higher.
Thanks
- To the authors of the
cesu8library. It's a genuinely good library that helped me years ago learn some more complex Rust concepts. - To the authors of
simdutf8for arguably one of the biggest improvements to the borrow paths in this library. - To the authors of
simdnbtfor the inspiration of usingportable_simd.
License
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.