1 unstable release
Uses old Rust 2015
| 0.5.0 | Apr 15, 2018 |
|---|---|
| 0.4.0 |
|
| 0.3.1 |
|
| 0.2.0 |
|
| 0.1.0 |
|
#2337 in Data structures
137 downloads per month
91KB
635 lines
Contains (Zip file, 14KB) doc/illustration-with-heap.odg, (Zip file, 13KB) doc/illustration.odg
seq module
The module seq provides the lightweight, generic sequence container Seq for unmovable data
and is embedded into the program during compile time. Elements of Seq are
stacked on top of each other.
Initially a sequence is empty. A longer sequence is constructed attaching a new head to the existing sequence, representing the tail.
Multiple sequences may share the same tail, permitting memory-efficient organisation of hierarchical data.
Usage
Put this in your Cargo.toml:
## Cargo.toml file
[dependencies]
seq = "0.5"
The "default" usage of this type as a queue is to use Empty or ConsRef to construct a
queue, and head and tail to deconstruct a queue into head and remaining
tail of a sequence.
pub enum Seq<'a, T: 'a> {
Empty,
ConsRef(T, &'a Seq<'a, T>),
ConsOwn(T, Box<Seq<'a, T>>),
}
Examples
Constructing two sequences seq1 as [1,0] and seq2 as [2,1,0], sharing data with seq1
// constructing the sequence 'seq1'
const seq1: Seq<i32> = Seq::ConsRef(1, &Seq::ConsRef(0, &Seq::Empty));
// construction the sequence 'seq2' sharing data with 'seq1'
const seq2: Seq<i32> = Seq::ConsRef(2, &seq1);
Deconstructing a sequence
fn print_head<'a>(seq: &'a Seq<i32>) {
println!("head {}", seq.head().unwrap());
}
Extend an existing sequence. Note the lifetime of the return type matches the one of the tail.
fn extend<'a>(head: i32, tail: &'a Seq<i32>) -> Seq<'a, i32> {
return Seq::ConsRef(head, tail);
}
Extend an existing sequence with dynamic element residing in heap-memory
fn extend_boxed<'a>(head: i32, tail: &'a Seq<i32>) -> Box<Seq<'a, i32>> {
return Box::new(Seq::ConsRef(head, tail));
}
Iterate a sequence
fn sum_up(seq: &Seq<i32>) -> i32 {
return seq.into_iter().fold(0, |x, y| x + y);
}
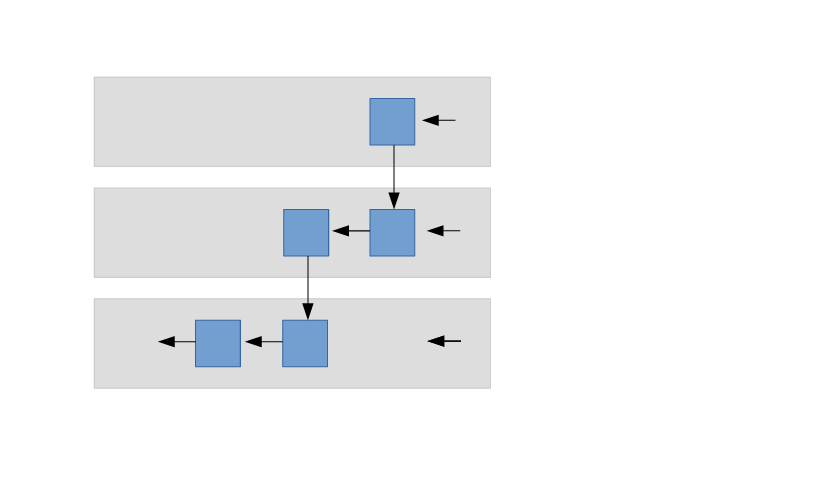
Memory layout
The following image illustrates the sequences s, t, u. The sequence s is a sub-sequence of t, and t
being a sub-sequence of u; each one accessible in its function context only.
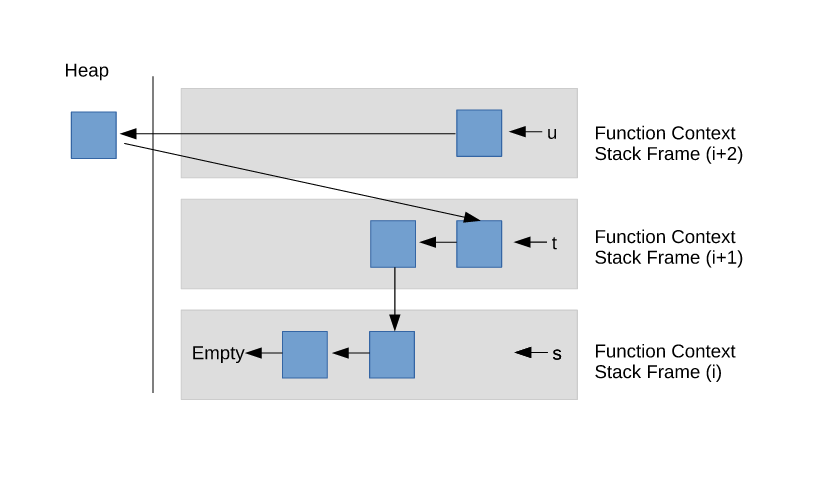
For use-cases where a sub-routine/expression shall return a temporary extended sequence, it is possible to construct new
sequences using elements in heap-memory. In this case these heap-elements are boxed/owned.
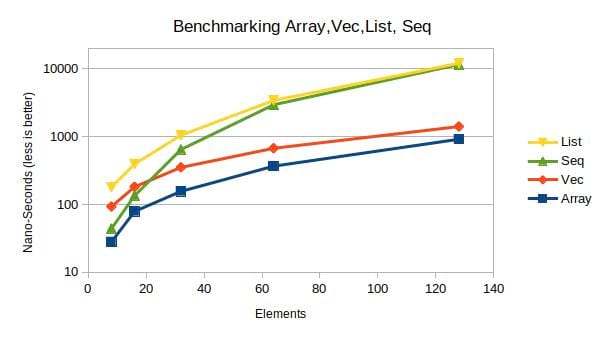
Benchmarks
The data structure Seq implements a linked list. In terms of performance it cannot compete with a native
array. But, Seq ranks between the containers Vec and LinkedList.
The benchmark is a memory-intensive, recursive function call and benefits from consecutive memory; each recursive function-call a new integer element is appended and an iterator is cumulating all elements.
As the benchmark-chart demonstrates, the container Seq performs better than Vec andLinkedList for up to
N=16 elements; and even shows better performance than LinkedList if less than N=64 elements. The benchmark
is performed for up to N= 8, 16, 32, 64, 128, 256, 512.
> cargo bench --features benchmark
test benchmark::bench_array___8 ... bench: 0 ns/iter (+/- 0)
test benchmark::bench_array__16 ... bench: 0 ns/iter (+/- 0)
test benchmark::bench_array__32 ... bench: 196 ns/iter (+/- 9)
test benchmark::bench_array__64 ... bench: 450 ns/iter (+/- 29)
test benchmark::bench_array_128 ... bench: 1,109 ns/iter (+/- 98)
test benchmark::bench_array_256 ... bench: 3,125 ns/iter (+/- 50)
test benchmark::bench_array_512 ... bench: 12,053 ns/iter (+/- 230)
test benchmark::bench_list___8 ... bench: 215 ns/iter (+/- 4)
test benchmark::bench_list__16 ... bench: 527 ns/iter (+/- 10)
test benchmark::bench_list__32 ... bench: 1,408 ns/iter (+/- 461)
test benchmark::bench_list__64 ... bench: 4,209 ns/iter (+/- 86)
test benchmark::bench_list_128 ... bench: 13,638 ns/iter (+/- 884)
test benchmark::bench_list_256 ... bench: 52,786 ns/iter (+/- 4,552)
test benchmark::bench_list_512 ... bench: 188,453 ns/iter (+/- 3,053)
test benchmark::bench_seq___8 ... bench: 53 ns/iter (+/- 1)
test benchmark::bench_seq__16 ... bench: 191 ns/iter (+/- 10)
test benchmark::bench_seq__32 ... bench: 1,081 ns/iter (+/- 30)
test benchmark::bench_seq__64 ... bench: 4,432 ns/iter (+/- 82)
test benchmark::bench_seq_128 ... bench: 16,749 ns/iter (+/- 209)
test benchmark::bench_seq_256 ... bench: 63,775 ns/iter (+/- 528)
test benchmark::bench_seq_512 ... bench: 247,919 ns/iter (+/- 2,183)
test benchmark::bench_vec___8 ... bench: 111 ns/iter (+/- 3)
test benchmark::bench_vec__16 ... bench: 221 ns/iter (+/- 4)
test benchmark::bench_vec__32 ... bench: 398 ns/iter (+/- 11)
test benchmark::bench_vec__64 ... bench: 735 ns/iter (+/- 19)
test benchmark::bench_vec_128 ... bench: 1,634 ns/iter (+/- 49)
test benchmark::bench_vec_256 ... bench: 4,774 ns/iter (+/- 103)
test benchmark::bench_vec_512 ... bench: 15,306 ns/iter (+/- 250)
Every element of Seq is causing overhead of ca 16 bytes for the discriminator, and the reference
to the tail.
Conclusion
These benchmarks show, the collection Seq shows better performance than Vec for 16 elements or less, and even
better performance than LinkedList for 64 elements or less. In this range Seq benefits from stack-memory.
When N>64 performance drops, probably caused by page-faults and the need to request new memory-pages from OS.