18 releases (stable)
| 4.4.0 | Apr 23, 2025 |
|---|---|
| 4.3.0 | Mar 17, 2025 |
| 4.2.0 | Oct 13, 2024 |
| 4.1.0 | Jun 16, 2024 |
| 0.3.1 | Sep 29, 2018 |
#37 in Encoding
418,944 downloads per month
Used in 4 crates
530KB
11K
SLoC
schema_registry_converter
This library provides a way of using the Confluent Schema Registry in a way that is compliant with the Java client. Since Karapace is API compatible it could also be used with this library. If you want to use advances features of the Confluent Schema Registry like client side encryption schema-registry-client is likely better suited.
The release notes can be found on github
Consuming/decoding and producing/encoding is supported. It's also possible to provide the schema to use when decoding.
You can also include references when decoding. Without a schema provided, the latest schema with the same subject will
be used.
It's supposed to be feature complete compared to the Java version. If anything is missing or not working as expected please create an issue or start a discussion on github discussions. An example of using this library async with protobuf to produce data to Kafka can be found in ksqlDB-GraphQL-poc. A blog with a bit of background on this library can be found titled confluent Schema Registry and Rust
Getting Started
schema_registry_converter.rs is available on crates.io. It is recommended to look there for the newest and more elaborate documentation. It has a couple of feature flags, be sure to set them correctly.
Avro
To use it to convert using Avro async use:
[dependencies]
schema_registry_converter = { version = "4.4.0", features = ["avro"] }
For simplicity there are easy variants that internally have an arc.
Making it easier to use at the price of some overhead. To use the easy variants add the easy feature and use the
structs that start with Easy in the name to do the conversions.
[dependencies]
schema_registry_converter = { version = "4.4.0", features = ["easy", "avro"] }
...and see the docs for how to use it.
All the converters also have a blocking (non async) version, in that case use something like:
[dependencies]
schema_registry_converter = { version = "4.4.0", default-features = false, features = ["avro", "blocking"] }
If you need to use both in a project you can use something like, but have to be weary you import the correct paths depending on your use.
[dependencies]
schema_registry_converter = { version = "4.4.0", features = ["avro", "blocking"] }
Protobuf
To use it to convert using Protobuf async use:
[dependencies]
schema_registry_converter = { version = "4.4.0", features = ["proto_raw"] }
For simplicity there are easy variants that internally have an arc.
Making it easier to use at the price of some overhead. To use the easy variants add the easy feature and use the
structs that start with Easy in the name to do the conversions.
[dependencies]
schema_registry_converter = { version = "4.4.0", features = ["easy", "proto_raw"] }
...and see the docs for how to use it.
Consumer
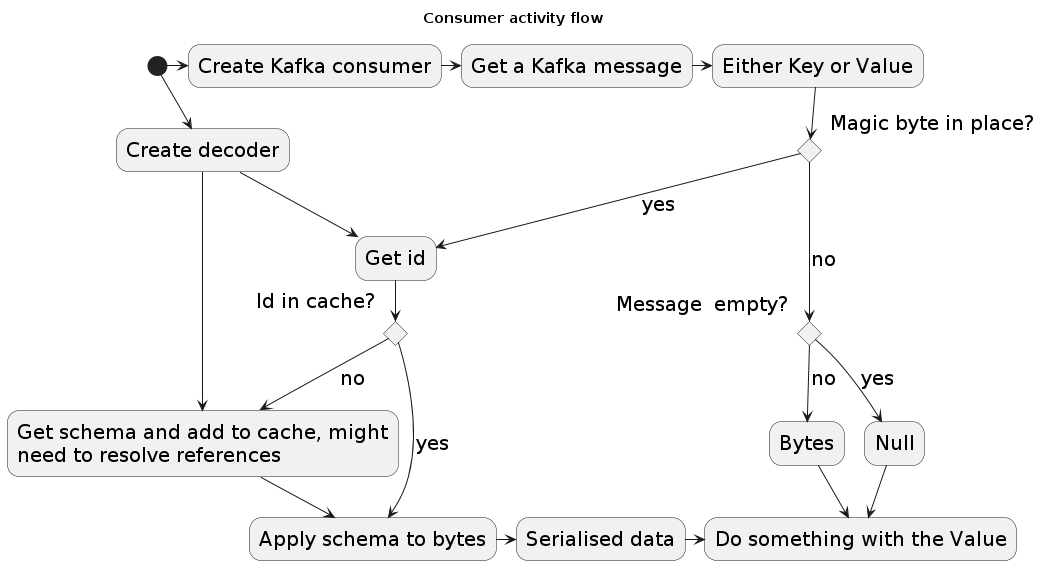
For consuming messages encoded with the schema registry, you need to fetch the correct schema from the schema registry to transform it into a record. For clarity, error handling is omitted from the diagram.
Producer
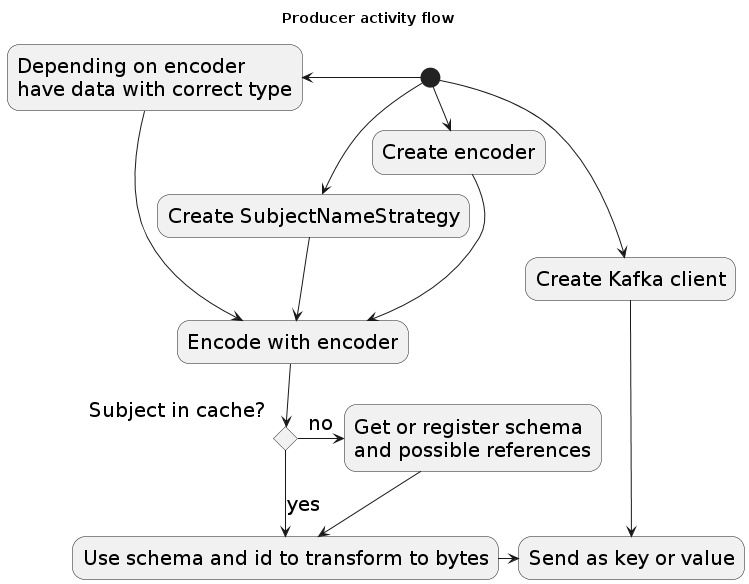
For producing messages which can be properly consumed by other clients, the proper id needs to be encoded with the message. To get the correct id, it might be necessary to register a new schema. For clarity, error handling is omitted from the diagram.
Example with consumer and producer using Avro (blocking)
Examples which does both consuming/decoding and producing/encoding. To use structs with Avro they must have an
implementation
of either the serde::Deserialize or serde::Serialize trait to work. The examples are especially useful to update
from the 1.x.x version, when starting you probably want to use the async versions.
use rdkafka::message::{Message, BorrowedMessage};
use apache_avro::types::Value;
use schema_registry_converter::blocking::{Decoder, Encoder};
use schema_registry_converter::blocking::schema_registry::SubjectNameStrategy;
fn main() {
let decoder = Decoder::new(SrSettings::new(String::from("http://localhost:8081")));
let encoder = Encoder::new(SrSettings::new(String::from("http://localhost:8081")));
let hb = get_heartbeat(msg, &decoder);
let record = get_future_record_from_struct("hb", Some("id"), hb, &encoder);
producer.send(record);
}
fn get_value<'a>(
msg: &'a BorrowedMessage,
decoder: &'a Decoder,
) -> Value {
match decoder.decode(msg.payload()) {
Ok(v) => v,
Err(e) => panic!("Error getting value: {}", e),
}
}
fn get_heartbeat<'a>(
msg: &'a BorrowedMessage,
decoder: &'a Decoder,
) -> Heartbeat {
match decoder.decode_with_name(msg.payload()) {
Ok((name, value)) => {
match name.name.as_str() {
"Heartbeat" => {
match name.namespace {
Some(namespace) => {
match namespace.as_str() {
"nl.openweb.data" => from_value::<Heartbeat>(&value).unwrap(),
ns => panic!("Unexpected namespace {}", ns),
}
}
None => panic!("No namespace in schema, while expected"),
}
}
name => panic!("Unexpected name {}", name),
}
}
Err(e) => panic!("error getting heartbeat: {}", e),
}
}
fn get_future_record<'a>(
topic: &'a str,
key: Option<&'a str>,
values: Vec<(&'static str, Value)>,
encoder: &'a Encoder,
) -> FutureRecord<'a> {
let subject_name_strategy = SubjectNameStrategy::TopicNameStrategy(topic, false);
let payload = match encoder.encode(values, &subject_name_strategy) {
Ok(v) => v,
Err(e) => panic!("Error getting payload: {}", e),
};
FutureRecord {
topic,
partition: None,
payload: Some(&payload),
key,
timestamp: None,
headers: None,
}
}
fn get_future_record_from_struct<'a>(
topic: &'a str,
key: Option<&'a str>,
heartbeat: Heartbeat,
encoder: &'a Encoder,
) -> FutureRecord<'a> {
let subject_name_strategy = SubjectNameStrategy::TopicNameStrategy(topic, false);
let payload = match encoder.encode_struct(heartbeat, &subject_name_strategy) {
Ok(v) => v,
Err(e) => panic!("Error getting payload: {}", e),
};
FutureRecord {
topic,
partition: None,
payload: Some(&payload),
key,
timestamp: None,
headers: None,
}
}
Direct interaction with schema registry
Some functions have been opened so this library can be used to directly get all the subjects, all the version of a subject, or the raw schema with a subject and version. For these see the either async or blocking version of the integration tests.
Example using to post schema to schema registry
use schema_registry_converter::blocking::schema_registry::{
post_schema,
SuppliedSchema
};
fn main() {
let schema = SuppliedSchema {
name: String::from("nl.openweb.data.Heartbeat"),
schema_type: SchemaType::AVRO,
schema: String::from(r#"{"type":"record","name":"Heartbeat","namespace":"nl.openweb.data","fields":[{"name":"beat","type":"long"}]}"#),
references: vec![],
};
let result = post_schema("http://localhost:8081/subjects/test-value/versions", heartbeat_schema);
}
Relation to related libraries
The avro part of the conversion is handled by avro-rs. As such, I don't include tests for every possible schema. While I used rdkafka in combination to successfully consume from and produce to kafka, and while it's used in the example, this crate has no direct dependency on it. All this crate does is convert [u8] <-> Some Value (based on converter used). With Json and Protobuf some other dependencies are pulled in, by using said features. I have tried to encapsulate all the errors in the SRCError type. So even when you get a pannic/error that's an SRCError it could be an error from one of the dependencies. Please make sure you are using the library correctly, and the error is not caused by a depency, before creating an issue.
Integration test
The integration tests require a Kafka cluster running on the default ports. It will create topics, register schema's,
produce and consume some messages. They are only included when compiled with the kafka_test feature, so to include
them in testing cargo test --verbose --all-features -- --test-threads=1 needs to be run.
The 'prepare_integration_test.sh' script can be used to create the 3 topics needed for the tests. To ensure Java
compatibility it's also needed to run
the schema-registry-test-app docker image.
License
This project is licensed under either of
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in Schema Registry Converter by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
Dependencies
~6–20MB
~283K SLoC