| 0.2.5 |
|
|---|---|
| 0.2.3 |
|
| 0.2.2-alpha.6 |
|
#16 in #flink
605KB
16K
SLoC
rlink-rs
![]()
![]()
![]()
High performance Stream Processing Framework. A new, faster, implementation of Apache Flink from scratch in Rust. pure memory, zero copy. single cluster in the production environment stable hundreds of millions per second window calculation.
Framework tested on Linux/MacOS/Windows, requires stable Rust.
Monitor
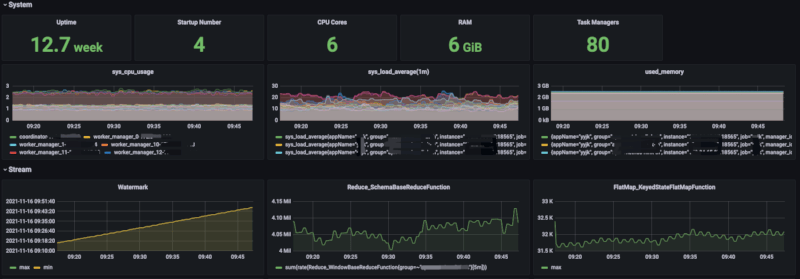
Graph
Graph Evolution
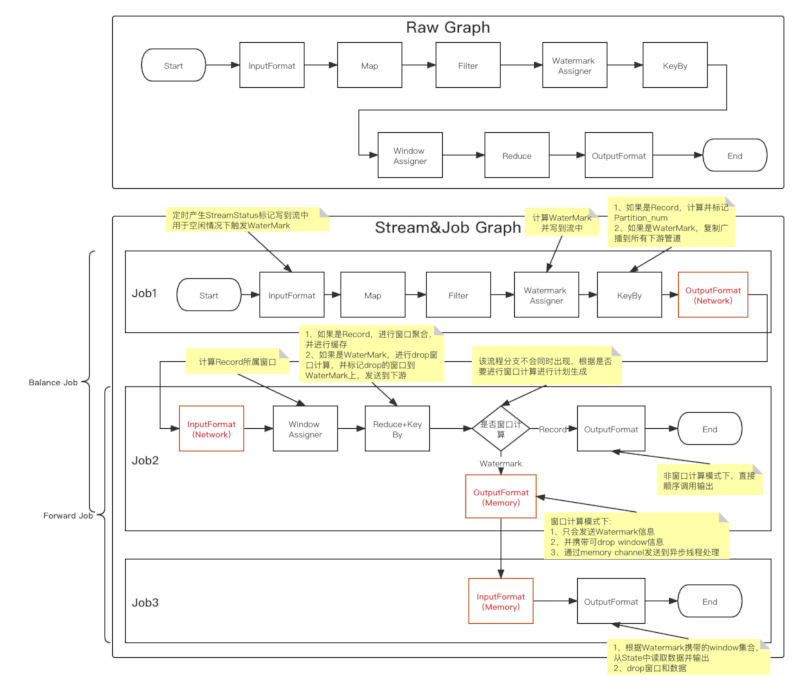
rlink Plan Visualizer
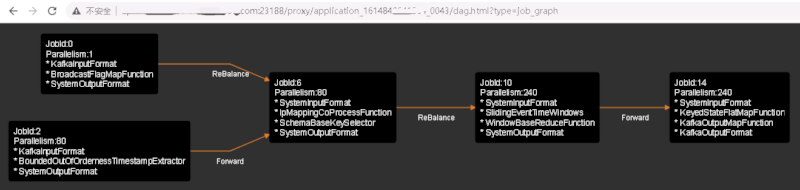
Example
rlink = "0.6"
SELECT
HOP_START(timestamp, INTERVAL '20' SECOND, INTERVAL '60' SECOND),
HOP_END(timestamp, INTERVAL '20' SECOND, INTERVAL '60' SECOND),
name,
SUM(value),
MAX(value),
MIN(value),
COUNT(*),
FROM stream_table
GROUP BY HOP(timestamp, INTERVAL '20' SECOND, INTERVAL '60' SECOND), name
#[derive(Clone, Debug)]
pub struct SimpleStreamApp {}
impl StreamApp for SimpleStreamApp {
fn prepare_properties(&self, properties: &mut Properties) {
properties.set_application_name("rlink-simple");
}
fn build_stream(&self, _properties: &Properties, env: &mut StreamExecutionEnvironment) {
env.register_source(vec_source(gen_records(), &model::FIELD_METADATA), 1)
.assign_timestamps_and_watermarks(
DefaultWatermarkStrategy::new()
.for_bounded_out_of_orderness(Duration::from_secs(1))
.wrap_time_periodic(Duration::from_secs(10), Duration::from_secs(20))
.for_schema_timestamp_assigner("timestamp"),
)
.key_by(SchemaKeySelector::new(vec!["name"]))
.window(SlidingEventTimeWindows::new(
Duration::from_secs(60),
Duration::from_secs(20),
None,
))
.reduce(
SchemaReduceFunction::new(vec![sum("value"), max("value"), min("value"), count()]),
2,
)
.add_sink(print_sink());
}
}
Build
Build source
# debug
cargo build --color=always --all --all-targets
# release
cargo build --release --color=always --all --all-targets
Standalone Deploy
Config
standalone.yaml
---
# all job manager's addresses, one or more
application_manager_address:
- "http://0.0.0.0:8770"
- "http://0.0.0.0:8770"
metadata_storage:
type: Memory
# bind ip
task_manager_bind_ip: 0.0.0.0
task_manager_work_dir: /data/rlink/application
task_managers
TaskManager list
10.1.2.1
10.1.2.2
10.1.2.3
10.1.2.4
Launch
Coordinator
./start_job_manager.sh
Worker
./start_task_manager.sh
Submit Application
On Standalone
## submit an application
# create job
curl http://x.x.x.x:8770/job/application \
-X POST \
-F "file=@/path/to/execute_file" \
-v
# run job
curl http://x.x.x.x:8770/job/application/application-1591174445599 \
-X POST \
-H "Content-Type:application/json" \
-d '{"batch_args":[{"cluster_mode":"Standalone", "manager_type":"Coordinator","num_task_managers":"15"}]}' \
-v
# kill job
curl http://x.x.x.x:8770/job/application/application-1591174445599/shutdown \
-X POST \
-H "Content-Type:application/json"
On Yarn
update manager jar to hdfs
upload rlink-yarn-manager-{version}-jar-with-dependencies.jar to hdfs
eg: upload to hdfs://nn/path/to/rlink-yarn-manager-{version}-jar-with-dependencies.jar
update dashboard to hdfs
upload rlink-dashboard.zip to hdfs
eg: upload to hdfs://nn/path/to/rlink-dashboard.zip
update application to hdfs
upload your application executable file to hdfs.
eg: upload rlink-showcase to hdfs://nn/path/to/rlink-showcase
submit yarn job
submit yarn job with rlink-yarn-client-{version}.jar
hadoop jar rlink-yarn-client-{version}.jar rlink.yarn.client.Client \
--applicationName rlink-showcase \
--worker_process_path hdfs://nn/path/to/rlink-showcase \
--java_manager_path hdfs://nn/path/to/rlink-yarn-manager-{version}-jar-with-dependencies.jar \
--yarn_manager_main_class rlink.yarn.manager.ResourceManagerCli \
--dashboard_path hdfs://nn/path/to/rlink-dashboard.zip \
--master_memory_mb 256 \
--master_v_cores 1 \
--memory_mb 256 \
--v_cores 1 \
--queue root.default \
--cluster_mode YARN \
--manager_type Coordinator \
--num_task_managers 80 \
--application_process_arg xxx
On Kubernetes
Preparation
- Kubernetes
- KubeConfig, configurable via ~/.kube/config. You can verify permissions by running kubectl auth can-i <list|create|edit|delete> pods
take a look at how to setup a Kubernetes cluster.
Starting a rlink application on Kubernetes
# start
./target/release/rlink-kubernetes \
name=my_first_rlink_application \
image_path=name:tag \
job_v_cores=1 \
job_memory_mb=100 \
task_v_cores=1 \
task_memory_mb=100 \
num_task_managers=1 \
# stop
kubectl delete deployment/my_first_rlink_application
Build image example-simple
sudo docker build -t xxx:xx -f ./docker/Dockerfile_example_simple .
Dependencies
~30–45MB
~754K SLoC