5 releases
| 0.1.6 | Mar 19, 2025 |
|---|---|
| 0.1.5 | Feb 6, 2024 |
| 0.1.4 | Nov 27, 2023 |
| 0.1.3 | Nov 8, 2023 |
| 0.1.2 | Sep 30, 2023 |
#74 in Concurrency
2.5MB
4.5K
SLoC
![]()
Parallelo Parallel Library (PPL): Unlock the Power of Parallel Computing in Rust
🌟 Welcome to Parallelo Parallel Library (PPL) – a small, but powerful, parallel framework written in Rust. 🚀
Parallelo Parallel Library (PPL) is an under-development parallel framework written in Rust. The main goal of PPL is to provide a structured approach to parallel programming in Rust, allowing developers to unleash the power of parallelism without having to deal with low-level concurrency management mechanisms. PPL empowers your Rust programs by unlocking the immense potential of parallelism, making your computations faster and more efficient. Whether you're working on large-scale data processing, simulations, or any computationally intensive task, PPL has got you covered.
Table of Contents
Features
-
Parallel Computing: Unleash the full power of parallelism in Rust with the Parallelo Parallel Library (PPL). Tap into the potential of multiple cores to turbocharge your computations, making them faster and more efficient than ever before.
-
Task, Stream, and Data Parallelism: PPL offers tools to express task, stream, and data parallelism models. Harness the power of task parallelism to break down your computations into smaller tasks that can be executed in parallel. Handle continuous data streams and process structured datasets in parallel, enabling efficient data processing and analysis.
-
Work-Stealing Thread Pool: PPL includes a work-stealing thread pool that elevates parallel execution to new heights. Thanks to the work-stealing thread pool, tasks are dynamically distributed among available threads, ensuring load balancing and efficient utilization of computational resources. This feature boosts the efficiency of parallel computations, enabling superior performance and scalability in your Rust applications.
-
Efficient Resource Management: Optimal resource management is vital in the realm of parallel programming. PPL grants you fine-grained control over resource allocation, including choose the number of threads to use, set up thread wait policies, and enable CPU pinning. This level of control ensures the optimal utilization of your hardware resources, resulting in enhanced performance and efficiency for your parallel computations.
-
Multiple Channel Backends: PPL provides you with the freedom to choose from a range of channel backends for seamless communication and coordination between parallel tasks. Take advantage of popular channel implementations like crossbeam-channel, flume, and kanal. Each backend possesses its own unique performance characteristics, memory usage, and feature set, allowing you to select the one that perfectly aligns with your specific requirements. These versatile channel backends facilitate smooth data flow and synchronization within your parallel computations.
-
Flexibility and Customization: With PPL you have the flexibility to create custom nodes for your pipeline, allowing you to express more complex parallel computations. This empowers you to tailor your parallel pipelines to suit your precise needs, creating highly customizable parallel workflows. Stateful nodes can store intermediate results and maintain crucial context information, enabling efficient data sharing between different stages of the computation. This flexibility and customizability augment the expressiveness of PPL, enabling you to tackle a wide range of parallel programming scenarios.
-
Intuitive API: Whether you're a seasoned parallel computing expert or a parallelism novice, PPL simplifies parallel programming with its intuitive API based on Structured Parallel Programming. Developers of all skill levels can effortlessly harness the power of parallel computing in Rust. The intuitive API ensures a smooth learning curve, allowing you to dive straight into parallelizing your computations with ease.
Installation
Parallelo Parallel Library (PPL) is currently available on both GitHub and Crates.io.
Please make sure you have Rust and Cargo installed on your system before proceeding. If you don't have them installed, you can get them from the official Rust website: https://www.rust-lang.org/tools/install
To use PPL in your Rust project, you can add the following in your Cargo.toml:
[dependencies]
ppl = { git = "https://github.com/valebes/ppl.git" }
Usage
A Simple (but long) Example: Fibonacci pipeline
Here a simple example that show how create a pipeline that computes the first 20 numbers of Fibonacci.
This pipeline is composed by:
- Source: emits number from 1 to 20.
- Stage: computes the i-th number of Fibonacci.
- Sink: accumulates and return a Vec with the results.
Here a snipped of code to show how build this pipeline:
use ppl::{prelude::*, templates::misc::{SourceIter, Sequential, SinkVec}};
fn main() {
let mut p = pipeline![
SourceIter::build(1..21),
Sequential::build(fib), // fib is a method that computes the i-th number of Fibonacci
SinkVec::build()
];
p.start();
let res = p.wait_end().unwrap().len();
assert_eq!(res, 20)
}
In this example we're building a simple pipeline, so why not use clousure instead than the library templates?
use ppl::prelude::*;
fn main() {
let mut p = pipeline![
{
let mut counter = 0;
move || {
if counter < 20 {
counter += 1;
Some(counter)
} else {
None
}
}
},
|input| Some(fib(input)),
|input| println!("{}", input)
];
p.start();
p.wait_end();
}
The run-time supports of the framework will call the clousure representing the Source till it returns None, when the Source returns None then a termination message will be propagated to the other stages of the pipeline.
If we want to parallelize the computation we must find a part of this algorithm that can be parallelized. In this case the stage in the middle is a good candidate, we replicate that stage introducing a Farm.
Now the code is as follows:
use ppl::{prelude::*, templates::misc::{SourceIter, Parallel, SinkVec}};
fn main() {
let mut p = pipeline![
SourceIter::build(1..21),
Parallel::build(8, fib), // We create 8 replicas of the stage seen in the previous code.
SinkVec::build()
];
p.start();
let res = p.wait_end().unwrap().len();
assert_eq!(res, 20)
}
If we don't want to use the templates offered by the library, there is the possibility to create custom stage. By creating custom stages it is possible to build stateful and more complex nodes for our pipeline.
Here the same example but using custom defined stages:
use ppl::prelude::*;
struct Source {
streamlen: usize,
counter: usize,
}
impl Out<usize> for Source {
// This method must be implemented in order to implement the logic of the node
fn run(&mut self) -> Option<usize> {
if self.counter < self.streamlen {
self.counter += 1;
Some(self.counter)
} else {
None
}
}
}
#[derive(Clone)]
struct Worker {}
impl InOut<usize, usize> for Worker {
// This method must be implemented in order to implement the logic of the node
fn run(&mut self, input: usize) -> Option<usize> {
Some(fib(input))
}
// We can override this method to specify the number of replicas of the stage
fn number_of_replicas(&self) -> usize {
8
}
}
struct Sink {
counter: usize,
}
impl In<usize, usize> for Sink {
// This method must be implemented in order to implement the logic of the node
fn run(&mut self, input: usize) {
println!("{}", input);
self.counter += 1;
}
// If at the end of the stream we want to return something, we can do it by implementing this method.
fn finalize(self) -> Option<usize> {
println!("End");
Some(self.counter)
}
}
fn main() {
let mut p = pipeline![
Source {
streamlen: 20,
counter: 0
},
Worker {},
Sink { counter: 0 }
];
p.start();
let res = p.wait_end(); // Here we will get the counter returned by the Sink
assert_eq!(res.unwrap(), 20);
}
Surely is more verbose, but allows to express a more variety of parallel computations in which each node can be stateful. Also, thanks to this approach, it is possible to build templates for stages that can be reused in different pipelines and/or projects.
Parallelo also offers a powerful work-stealing threadpool. Using that instead, we can express the same parallel computation as following:
use ppl::thread_pool::ThreadPool;
fn main() {
let tp = ThreadPool::new(); // We create a new threadpool
for i in 1..21 {
tp.execute(move || {
fib(i);
});
}
tp.wait(); // Wait till al worker have finished
}
If we don't want to wait the threads explicitly, we can create a parallel scope. At the end of the scope, all the threads are guaranteed to have finished their jobs. This can be done with the following code:
use ppl::thread_pool::ThreadPool;
fn main() {
let tp = ThreadPool::new(); // We create a new threadpool
tp.scope(|s| {
for i in 1..21 {
s.execute(move || {
fib(i);
});
}
}); // After this all threads have finished
}
A More Complex Example: Word Counter
To demonstrate the capabilities of Parallelo Parallel Library (PPL), let's consider a common problem: counting the occurrences of words in a text dataset. This example showcases how PPL can significantly speed up computations by leveraging parallelism.
Problem
The task is to count the occurrences of each word in a given text dataset. This involves reading the dataset, splitting it into individual words, normalizing the words (e.g., converting to lowercase and removing non-alphabetic characters), and finally, counting the occurrences of each word.
Approach 1: Pipeline
The pipeline approach in PPL provides an intuitive and flexible way to express complex parallel computations. In this approach, we construct a pipeline consisting of multiple stages, each performing a specific operation on the data. The data flows through the stages, with parallelism automatically applied at each stage.
In the word counter example, the pipeline involves the following stages:
- Source: Reads the dataset and emits lines of text.
- MapReduce: The map function converts each line of text into a list of words, where each word is paired with a count of 1. Moreover, the reduce function aggregates the counts of words by summing them for each unique word.
- Sink: Stores the final word counts in a hashmap.
By breaking down the computation into stages and leveraging parallelism, PPL's pipeline approach allows for efficient distribution of work across multiple threads or cores, leading to faster execution.
Here's the Rust code for the word counter using the pipeline approach:
use ppl::{
templates::map::MapReduce,
prelude::*,
};
struct Source {
reader: BufReader<File>,
}
impl Out<Vec<String>> for Source {
// Implementation details...
}
struct Sink {
counter: HashMap<String, usize>,
}
impl In<Vec<(String, usize)>, Vec<(String, usize)>> for Sink {
fn run(&mut self, input: Vec<(String, usize)>) {
// Increment value for key in hashmap
// If key does not exist, insert it with value 1
for (key, value) in input {
let counter = self.counter.entry(key).or_insert(0);
*counter += value;
}
}
fn finalize(self) -> Option<Vec<(String, usize)>> {
Some(self.counter.into_iter().collect())
}
}
pub fn ppl(dataset: &str, threads: usize) {
// Initialization and configuration...
let mut p = pipeline![
Source { reader },
MapReduce::build_with_replicas(
threads / 2, // Number of worker for each stage
|str| -> (String, usize) { (str, 1) }, // Map function
|a, b| a + b, // Reduce function
2 // Number of replicas of this stage
),
Sink {
counter: HashMap::new()
}
];
p.start();
let res = p.wait_end();
}
Approach 2: Thread Pool
Alternatively, PPL also provides a thread pool for parallel computations. In this approach, we utilize the par_map_reduce function of the thread pool to perform the word counting task.
The thread pool approach in PPL involves the following steps:
- Create a thread pool with the desired number of threads.
- Read the dataset and collect all the lines into a vector.
- Use the
par_map_reducefunction to parallelize the mapping and reducing operations on the vector of words. - The mapping operation converts each word into a tuple with a count of 1.
- The reducing operation aggregates the counts of words by summing them for each unique word.
Using the thread pool, PPL efficiently distributes the work across the available threads, automatically managing the parallel execution and resource allocation.
use ppl::prelude::*;
pub fn ppl_map(dataset: &str, threads: usize) {
// Initialization and configuration...
let file = File::open(dataset).expect("no such file");
let reader = BufReader::new(file);
// We can also create custom-sized thread pool
let mut tp = ThreadPool::with_capacity(threads);
let mut words = Vec::new();
reader.lines().map(|s| s.unwrap()).for_each(|s| words.push(s));
let res = tp.par_map_reduce(
words
.iter()
.flat_map(|s| s.split_whitespace())
.map(|s| {
s.to_lowercase()
.chars()
.filter(|c| c.is_alphabetic())
.collect::<String>()
})
.collect::<Vec<String>>(),
|str| -> (String, usize) { (str, 1) }, // Map function
|a, b| a + b, // Reduce function
);
}
An Advanced Example: Single-Input Multi-Output stage
In this example, we demonstrate how to model a data processing pipeline using PPL, where a stage produces multiple outputs for each input received.
This pipeline involves the following stages:
- Source: Generates a stream of 1000 numbers.
- Worker: Given a number, it produces multiple copies of that number.
- Sink: The
SinkVecstruct acts as a sink stage in the pipeline. It collects the output from the worker stage and stores the results in a vector.
The implementation of the InOut<usize, usize> trait overrides the run method to process the input received from the source and prepare the worker for producing multiple copies. The produce method generates the specified number of copies of the input. By implementing the is_producer method and returning true, this stage is marked as a producer. Additionally, the number_of_replicas method specifies the number of replicas of this worker to create for parallel processing.
use ppl::{templates::misc::SinkVec, prelude::*};
// Source
struct Source {
streamlen: usize,
counter: usize,
}
impl Out<usize> for Source {
fn run(&mut self) -> Option<usize> {
if self.counter < self.streamlen {
self.counter += 1;
Some(self.counter)
} else {
None
}
}
}
// Given an input, it produces 5 copies of it.
#[derive(Clone)]
struct Worker {
number_of_messages: usize,
counter: usize,
input: usize,
}
impl InOut<usize, usize> for Worker {
fn run(&mut self, input: usize) -> Option<usize> {
self.counter = 0;
self.input = input;
None
}
// After calling the run method, the rts of the framework
// will call the produce method till a None is returned.
// After a None is returned, the node will fetch the
// next input and call the run method again.
fn produce(&mut self) -> Option<usize> {
if self.counter < self.number_of_messages {
self.counter += 1;
Some(self.input)
} else {
None
}
}
// We mark this node as a producer
fn is_producer(&self) -> bool {
true
}
fn number_of_replicas(&self) -> usize {
8
}
}
fn main() {
// Create the pipeline using the pipeline! macro
let mut p = pipeline![
Source {
streamlen: 1000,
counter: 0
},
Worker {
number_of_messages: 5,
counter: 0,
input: 0
},
SinkVec::build()
];
// Start the processing
p.start();
// Wait for the processing to finish and collect the results
let res = p.wait_end().unwrap();
}
More complex examples are available in benches/, examples/, and in tests/.
Configuration
The configuration of Parallelo Parallel Library (PPL) can be customized by setting environment variables. The following environment variables are available:
-
PPL_MAX_CORES: Specifies the maximum number of CPUs to use. This configuration is only valid when pinning is active.
-
PPL_PINNING: Enables or disables the CPU pinning. By default, pinning is disabled (
false). (Equivalent toOMP_PROC_BINDin OpenMP). -
PPL_SCHEDULE: Specifies the scheduling method used in the pipeline. The available options are:
static: Static scheduling (Round-robin) (Default).dynamic: Dynamic scheduling (Work-stealing between replicas of the same stage enabled).
-
PPL_WAIT_POLICY: If set to
passive, the threads will try to give up their time to other threads when waiting for a communication or unused. This is particularly useful when we are using SMT and can improve performances. Instead, if is set toactive, the threads wil do busy waiting. By default, this option is set topassive. -
PPL_THREAD_MAPPING: Specifies the thread mapping. By default, the threads are mapped in the order in which the CPUs are found. This option is only valid when pinning is active. (Note that this environment variable is kinda similar to the
OMP_PLACESenvironment variable in OpenMP).- Example:
PPL_THREAD_MAPPING=0,2,1,3will map the threads in the following order:0 -> core 0,1 -> core 2,2 -> core 1,3 -> core 3.
- Example:
To customize the configuration, set the desired environment variables before running your Rust program that uses PPL. For example, you can set the environment variables in your shell script or use a tool to load them from a file.
Please note that changing these configuration options may have an impact on the performance and behavior of your parallel computations. Experiment with different settings to find the optimal configuration for your specific use case.
Moreover, you can determine the mapping string for a specific machine by using the script available at FastFlow Mapping String Script. This script helps identify the optimal thread-to-core mapping for your system.
Channel Backend
Parallelo Parallel Library (PPL) provides flexibility in choosing the channel backend used for multi-producer, single-consumer communication in the framework. Depending on your requirements and preferences, you can select the desired channel backend at compile time using feature flags.
The default backend in PPL is crossbeam.
Crossbeam provides a highly performant channel implementation that provides efficient and reliable communication differents threads. It is well-suited for a wide range of parallel computing scenarios.
Overall, PPL supports the following backends:
- crossbeam: Uses the Crossbeam channel (Default).
- flume: Uses the Flume channel.
- kanal: Uses the Kanal channel.
- ff: Uses a channel based on FastFlow queues (Experimental).
To select a specific channel backend, enable the corresponding feature flag during the build process. For example, to use the flume channel, add the following to your Cargo.toml file:
[dependencies]
ppl = { git = "https://github.com/valebes/ppl.git", default-features = false, features = ["flume"]}
FastFlow Channel
In addition to the others channel backends, PPL also provides an experimental mpsc channel implementation based on FastFlow queues. This backend is available using the ff feature flag.
This implementation can be found here and is substantially based on the FF Buffer by Luca Rinaldi.
This backend is built around a wrapper for the FastFlow queues that provides a channel-like interface.
In order to use this implementation you must download and install the FastFlow library in the home directory. The library can be downloaded from here or as follows:
cd ~
git clone https://github.com/fastflow/fastflow.git
Benchmarks
The benchmarks are available in the benches/ directory. To run the benchmarks, use the following command:
cargo bench
In order to generate the data set for the Image-Processing benchmark, do the following:
cd benches/benchmarks/img/images
./generate_input.sh
Available Benchmarks
-
Image Processing: A benchmark that is based on the Image-Processing benchmark found in RustStreamBench. You can find the benchmark source code here.
-
Mandelbrot Set: A basic parallel implementation of the well-known iterative algorithm to compute the Mandelbrot Set.
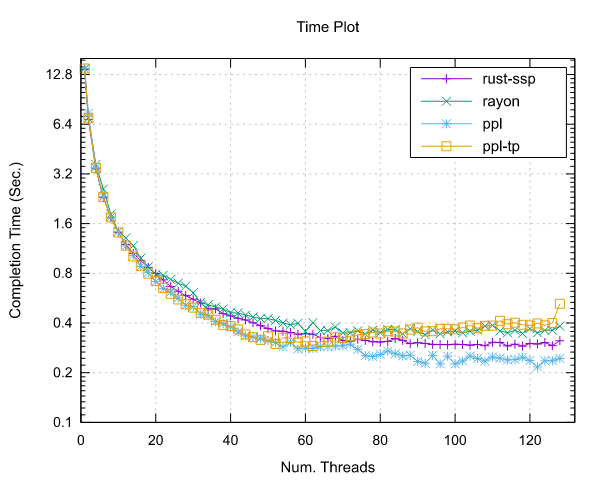
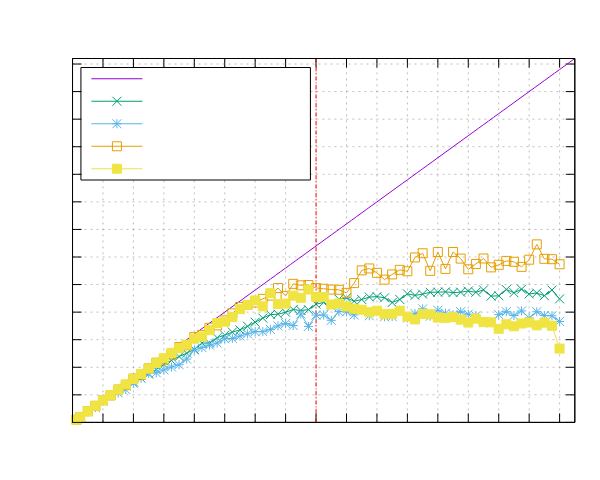
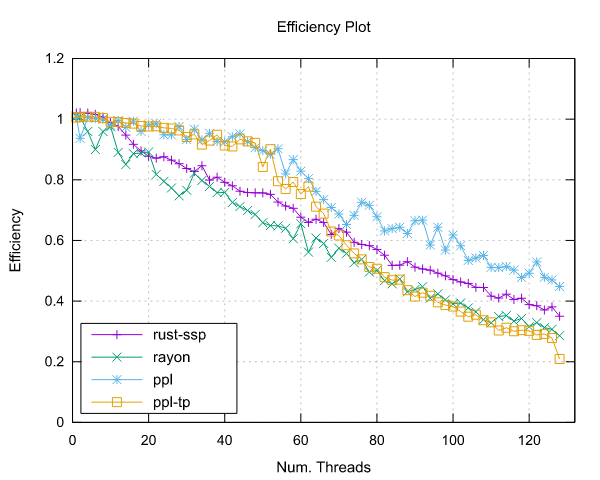
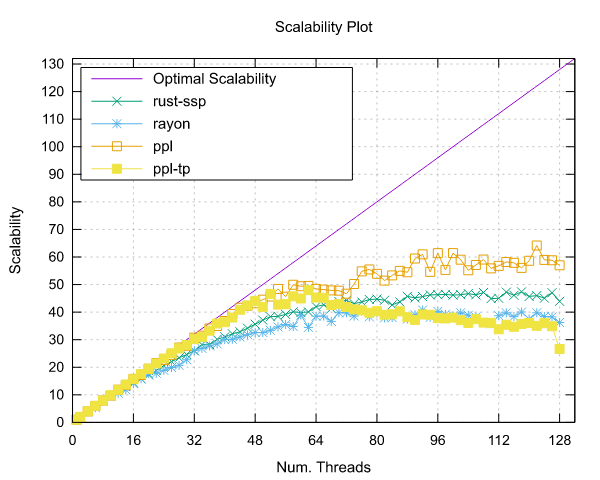
Image-Processing Results
Following are reported the results obtained by running the image-processing benchmark.
Both benchmarks were implemented using the Pipeline interface (ppl) and the Threadpool interface (ppl-tp).
Ampere Altra (ARM)
- Processor: 2x Ampere Altra 80 Cores @ 3.0GHz
- Configuration: PPL with pinning and dynamic scheduling enabled
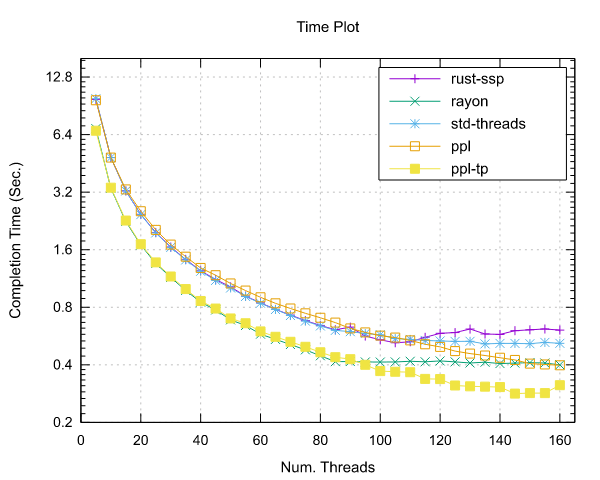 |
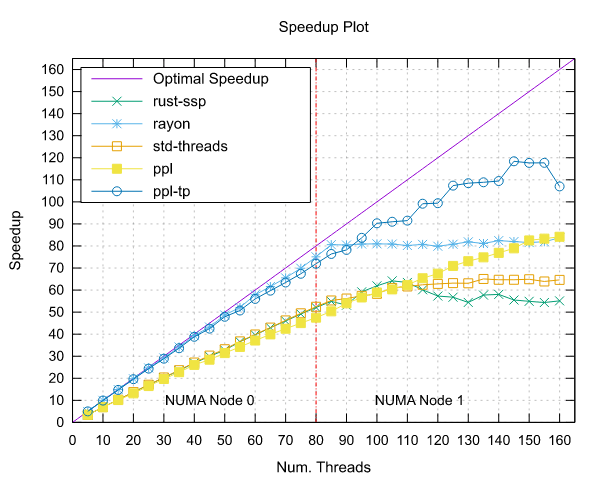 |
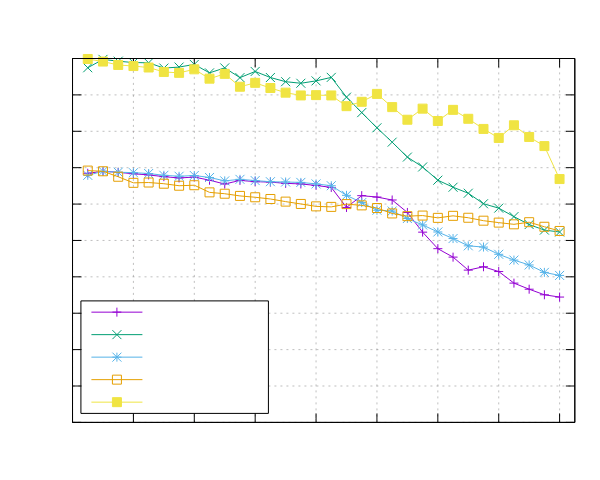 |
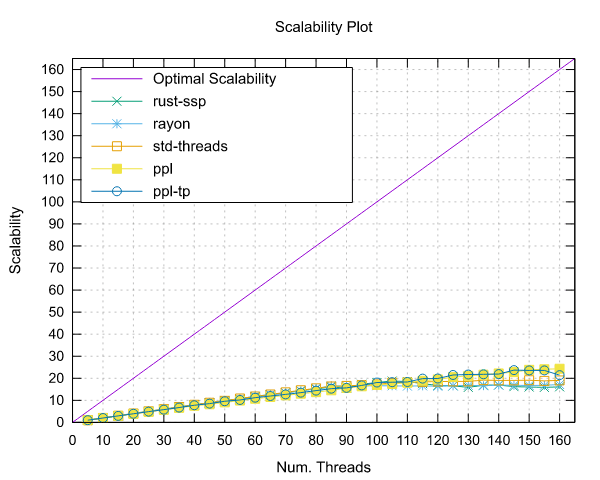 |
AMD EPYC 7551 (x86)
- Processor: 2x AMD EPYC 7551 32 Cores @ 2.5 GHz
- Configuration: PPL with pinning and dynamic scheduling enabled
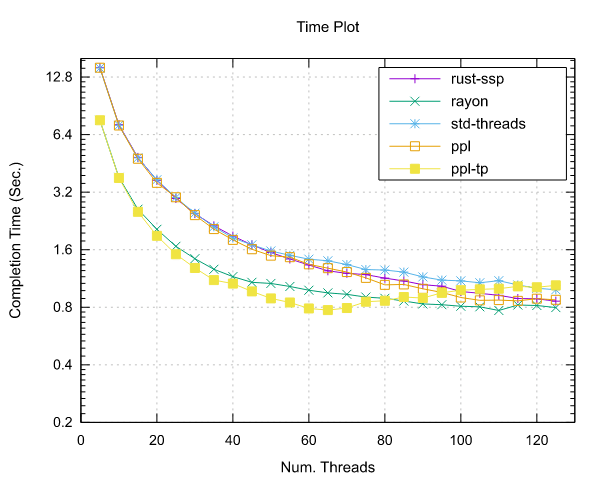 |
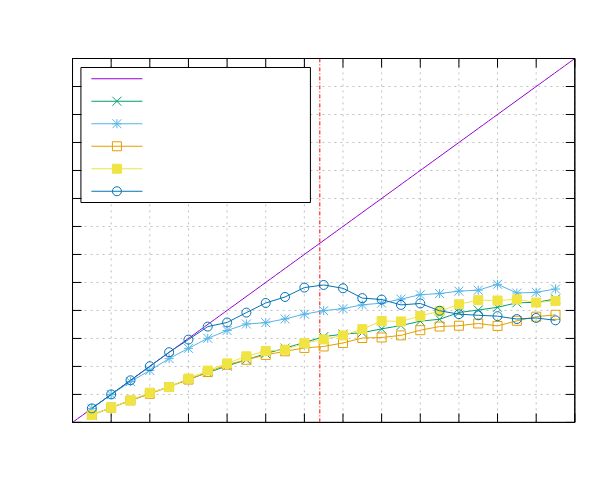 |
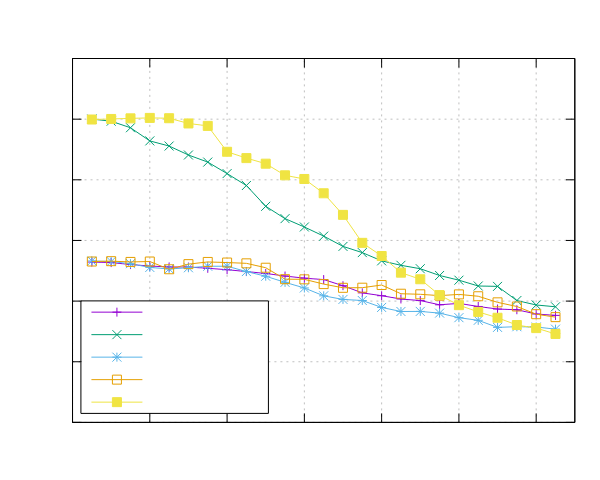 |
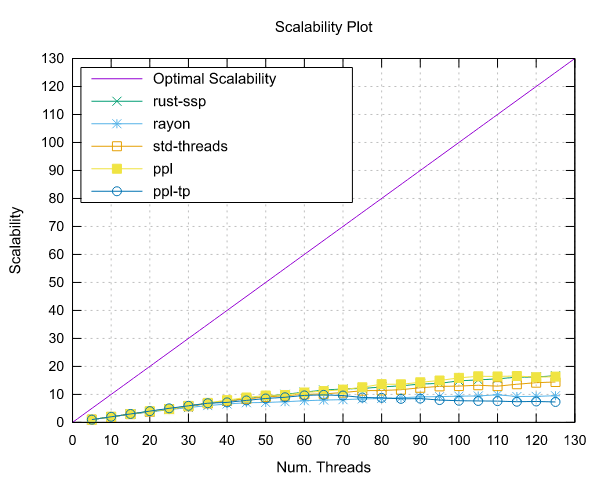 |
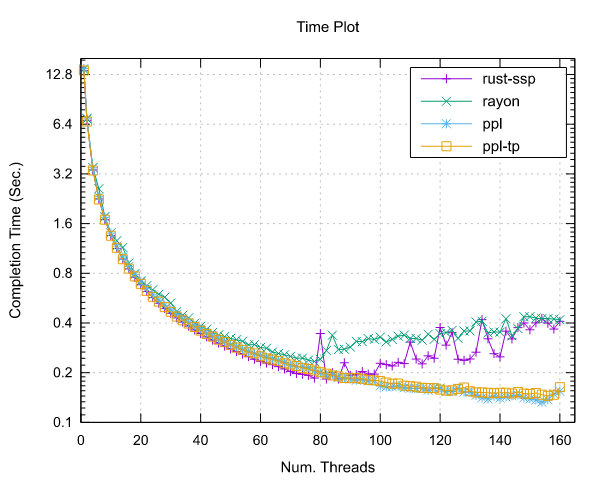
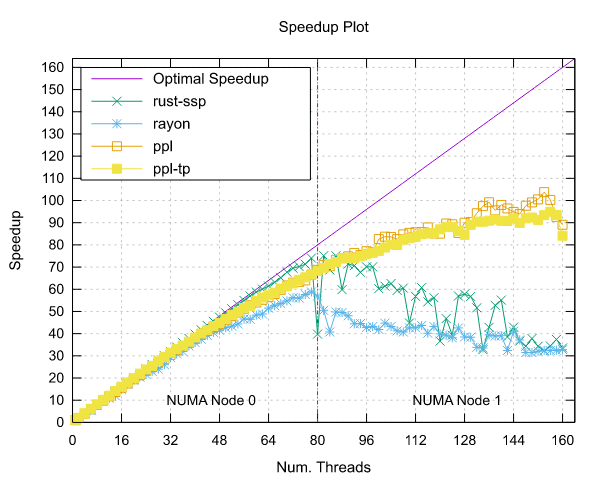
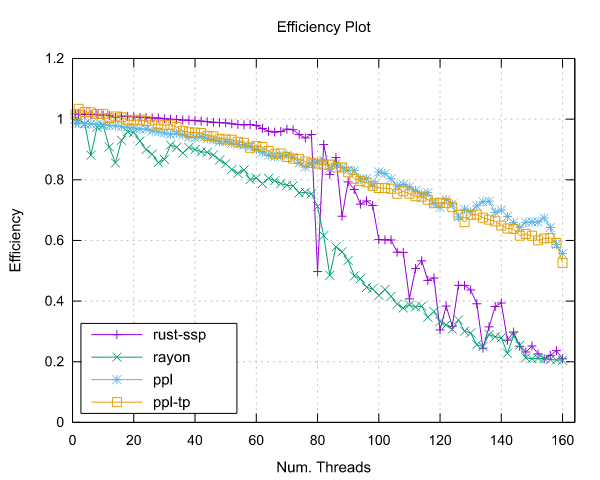
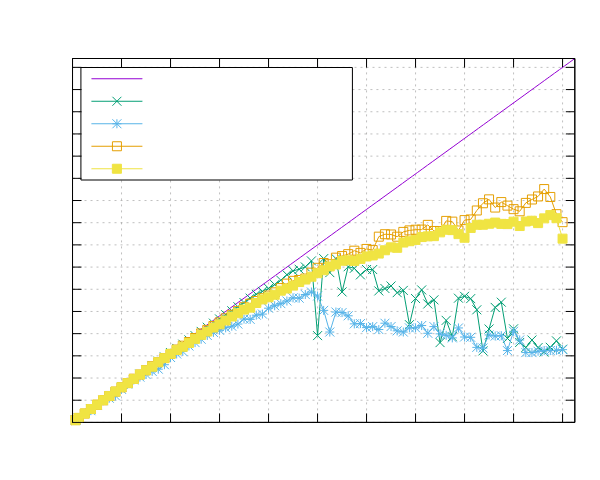
Mandelbrot Set Results
Following are reported the results obtained by running the mandelbrot set benchmark.
Ampere Altra (ARM)
- Processor: 2x Ampere Altra 80 Cores @ 3.0GHz
- Configuration: PPL with pinning and dynamic scheduling enabled
 |
 |
 |
 |
AMD EPYC 7551 (x86)
- Processor: 2x AMD EPYC 7551 32 Cores @ 2.5 GHz
- Configuration: PPL with pinning and dynamic scheduling enabled
 |
 |
 |
 |
Contributing
Thank you for considering contributing to Parallelo Parallel Library (PPL)!
If you would like to fix a bug, propose a new feature, or create a new template, you are welcome to do so! Please follow the steps below to contribute to PPL.
Code of Conduct
Please review our Code of Conduct before contributing.
How to Contribute
-
Create an Issue: Before starting significant changes, create an issue to discuss and coordinate efforts.
-
Fork and Clone: Fork the repository, then clone it to your local machine.
-
Branching: Create a new branch for your changes.
-
Make Changes: Implement your changes, write clear commit messages.
-
Tests: Add tests to ensure the correctness of your changes.
-
Run Tests: Verify that all tests pass successfully.
-
Submit a Pull Request: Push your branch and create a pull request referencing the relevant issue(s).
-
Review and Iterate: Address feedback and make necessary changes.
-
Celebrate! 🎉: Once approved and merged, your contributions will be part of PPL!
Reporting Issues
To report bugs, ask questions, or suggest new ideas, create an issue.
Warning
This library is still in an early stage of development. The API is not stable and may change in the future.
License
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.