7 releases
| 0.0.5 | May 24, 2024 |
|---|---|
| 0.0.5-rc2 | Oct 4, 2023 |
| 0.0.5-rc1 | May 7, 2023 |
| 0.0.4 | Dec 28, 2022 |
| 0.0.2 | Sep 23, 2022 |
#197 in Web programming
402 downloads per month
300KB
5.5K
SLoC
![]()
![]()
![]()
![]()
A scalable, distributed message queue powered by a segmented, partitioned, replicated and immutable
log.
This is currently a work in progress.
Usage
laminarmq provides a library crate and two binaries for managing laminarmq deployments. In order
to use laminarmq as a library, add the following to your Cargo.toml:
[dependencies]
laminarmq = "0.0.5"
Refer to latest git API Documentation or Crate Documentation for more details. There's also a book being written to further describe design decisions, implementation details and recipes.
laminarmq presents an elementary commit-log abstraction (a series of records ordered by indices),
on top of which several message queue semantics such as publish subscribe or even full blown
protocols like MQTT could be implemented. Users are free to read the messages with offsets in any
order they need.
Major milestones for laminarmq
- Locally persistent queue of records
- Single node, multi threaded, eBPF based request to thread routed message queue
- Service discovery with SWIM.
- Replication and consensus of replicated records with Raft.
Examples
Find examples demonstrating different capabilities of laminarmq in the
examples directory.
Media
Media associated with the laminarmq project.
Design
This section describes the internal design of laminarmq.
Cluster Hierarchy
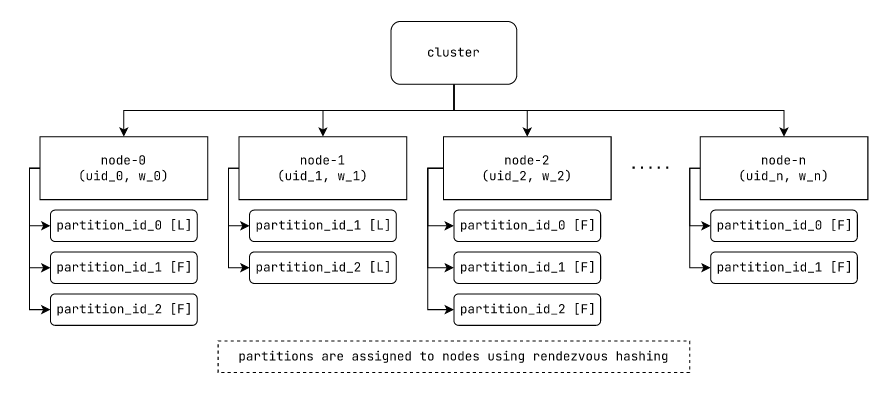
partition_id_x is of the form (topic_id, partition_idx)
In this example, consider:
partition_id_0 = (topic_id_0, partition_idx_0)
partition_id_1 = (topic_id_0, partition_idx_1)
partition_id_2 = (topic_id_1, partition_idx_0)
The exact numerical ids don't have any pattern with respect to partition_id and topic_id; there can be multiple topics, each of which can have multiple partitions (identified by partition_idx).
… alternatively:
[cluster]
├── node#001
│ ├── (topic#001, partition#001) [L]
│ │ └── segmented_log{[segment#001, segment#002, ...]}
│ ├── (topic#001, partition#002) [L]
│ │ └── segmented_log{[segment#001, segment#002, ...]}
│ └── (topic#002, partition#001) [F]
│ └── segmented_log{[segment#001, segment#002, ...]}
├── node#002
│ ├── (topic#001, partition#002) [F]
│ │ └── segmented_log{[segment#001, segment#002, ...]}
│ └── (topic#002, partition#001) [L]
│ └── segmented_log{[segment#001, segment#002, ...]}
└── ...other nodes
[L] := leader; [F] := follower
Fig: laminarmq cluster hierarchy depicting partitioning and replication.
A "topic" is a collection of records. A topic is divided into multiple "partition"(s). Each "partition" is then further replicated across multiple "node"(s). A "node" may contain some or all "partition"(s) of a "topic". In this way a topic is both partitioned and replicated across the nodes in the cluster.
There is no ordering of messages at the "topic" level. However, a "partition" is an ordered collection of records, ordered by record indices.
Although we conceptually maintain a hierarchy of partitions and topics, at the cluster level, we have chosen to maintain a flat representation of topic partitions. We present an elementary commit-log API at the partition level.
Users may hence do the following:
- Directly interact with our message queue at the partition level
- Use client side load balancing between topic partitions
This alleviates the burden of load balancing messages among partitions and message stream ownership record keeping from the cluster. Higher level constructs can be built on top of the partition commit-log based API as necessary.
Each partition replica group has a leader where writes go, and a set of followers which follow the leader and may be read from. Users may again use client side load balancing to balance reads across the leader and all the followers.
Each partition replica is backed by a segmented log for storage.
Service discovery and partition distribution to nodes
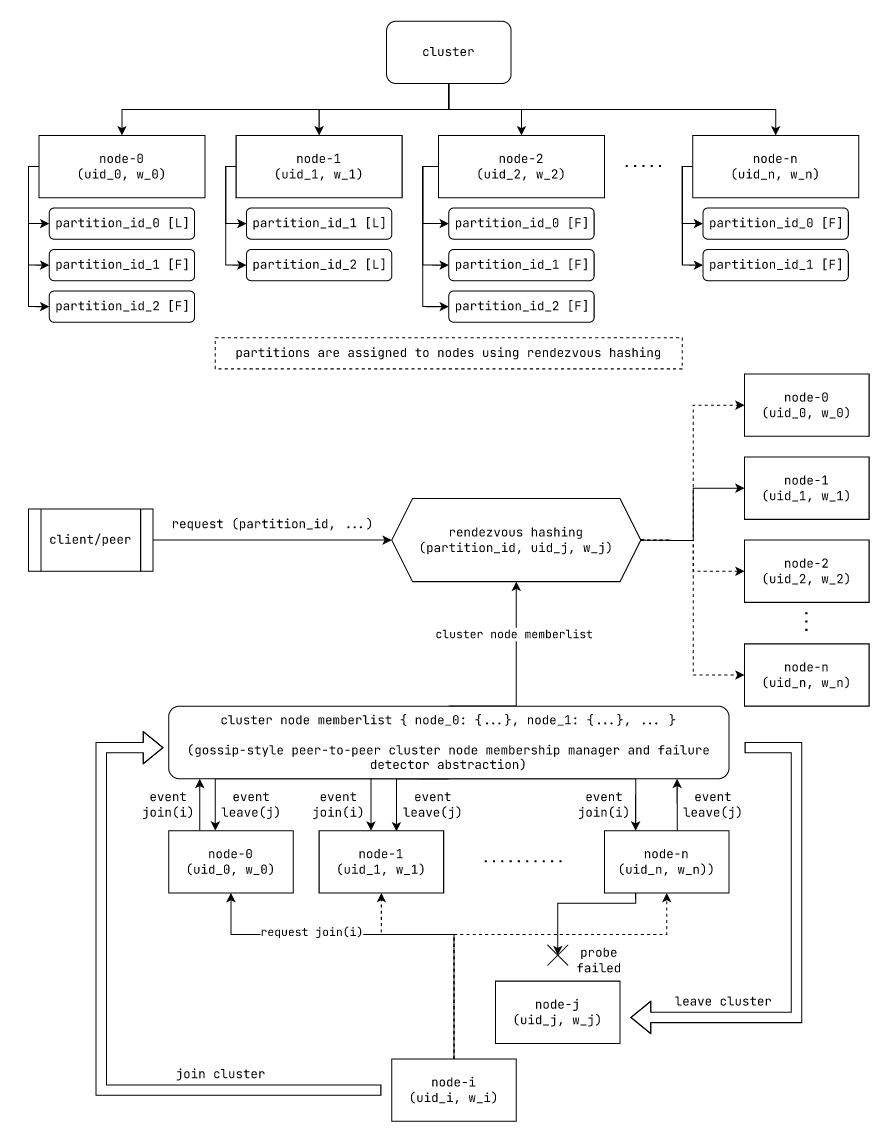
Fig: Rendezvous hashing based partition distribution and gossip style service discovery
mechanism used by laminarmq
In our cluster, nodes discover each other using gossip style peer to peer mechanisms. One such mechanism is SWIM (Scalable Weakly Consistent Infection-style Process Group Memberhsip).
In this mechanism, each member node notifies other members in the group whether a node is joining or leaving the cluster by using a gossip style information dissemination mechanism (A node gossips to neighbouring nodes, they in-turn gossip to their neighbours and so on).
In order to see whether a node has failed, the nodes randomly probes individual nodes in the cluster. For instance, node A probes node B directly. If node B responds, it has not failed. If node B does not respond, A attempts to probe node B indirectly through other nodes in the cluster, e.g. node A might ask node C to probe node B. Node A continues to indirectly probe node B with all the other nodes in the cluster. If node B responds to any of the indirect probes, it is still considered to not have failed. It is otherwise declared failed and removed from the cluster.
There are mechanisms in place to reduce false failures caused due to temporary hiccups. The paper goes into detail about those mechanisms.
This is also the core technology used in Hashicorp Serf, where there are further enhancements to improve failure detection and convergence speed.
Using this mechanism we can obtain a list of all the members in our cluster, along with their unique ids and capacity weights. We then use their ids and weights to determine where to place a partition using Rendezvous hashing.
From the Wikipedia article:
Rendezvous or highest random weight (HRW) hashing is an algorithm that allows clients to achieve distributed agreement on a set of k options out of a possible set of n options. A typical application is when clients need to agree on which sites (or proxies) objects are assigned to.
In our case, we use rendezvous hashing to determine the subset of nodes to use for placing the replicas of a partition.
For some hashing function H, some weight function f(w, hash) and partition id P_x, we proceed
as follows:
- For every node
N_iin the cluster with a weightw_i, we computeR_i = f(w_i, H(concat(P_x, N_i))) - We rank all nodes
N_ibelonging to the set of nodesNwith respect to their rank valueR_i. - For some replication factor
k, we select the topknodes to place thekreplicas of the partition with idP_x
(We assume k <= |N|; where |N| is the number of nodes and k is the number of replicas)
With this mechanism, anyone with the ids and weights of all the members in the cluster can compute the destination nodes for the replicas of a partition. This knowledge can also be used to route partition request to the appropriate nodes at both the client side and the server side.
In our case, we use client side load balancing to load balance all idempotent partition requests across all the possible nodes where a replica of the request's partition can be present. For non-idempotent request, if we send it to any one of the candidate nodes, they redirect it to the current leader of the replica set.
Supported execution models
laminarmq supports two execution models:
- General async execution model used by various async runtimes in the Rust ecosystem (e.g
tokio) - Thread per core execution model
In the thread-per-core execution model individual processor cores are limited to single threads. This model encourages design that minimizes inter-thread contention and locks, thereby improving tail latencies in software services. Read: The Impact of Thread per Core Architecture on Application Tail Latency.
In the thread per core execution model, we have to leverage application level partitioning such that each individual thread is responsible for a subset of requests and/or responsibilities. We also have to complement this model with proper routing of requests to the threads to ensure locality of requests. In our case this translates to having each thread be responsible for only a subset of the partition replicas in a node. Requests pertaining to a partition replica are always routed to the same thread. The following sections will go into more detail as to how this is achieved.
We realize that although the thread per core execution model has some inherent advantages, being compatible with the existing Rust ecosystem will significantly increase adoption. Therefore, we have designed our system with reusable components which can be organized to suit both execution models.
Request routing in nodes
General design
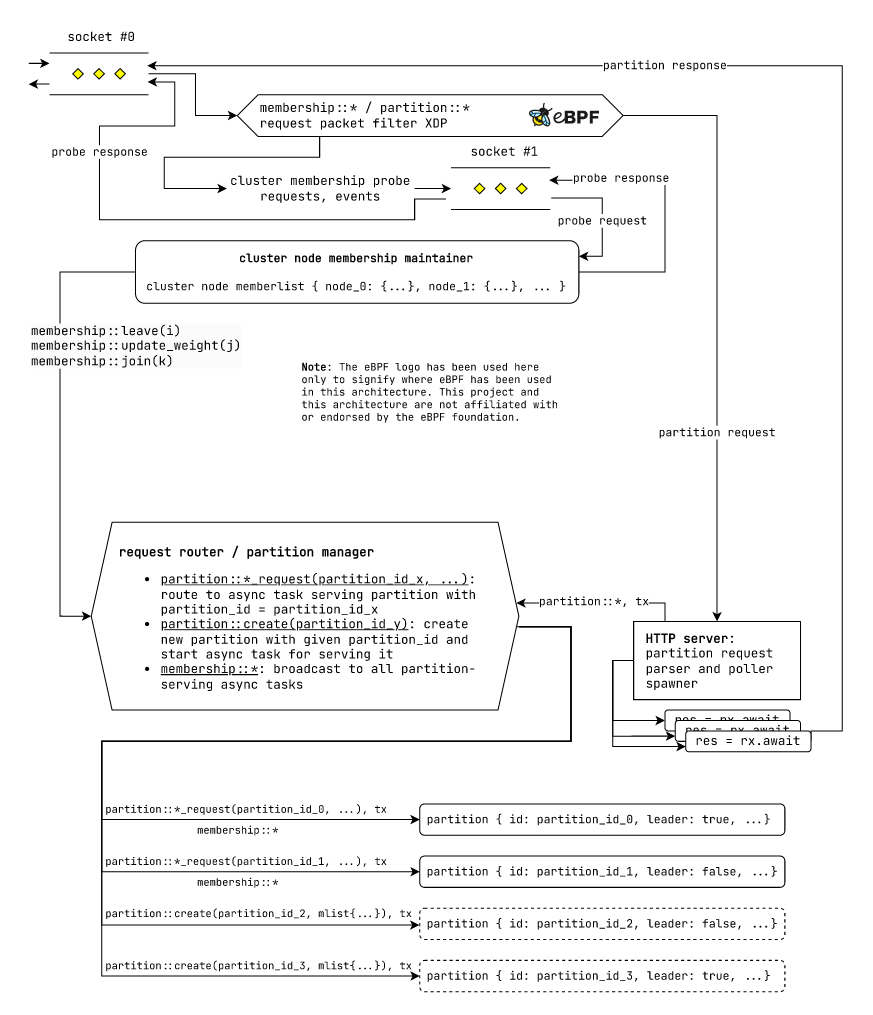
Fig: Request routing mechanism in laminarmq nodes using the general execution
model.
In our cluster, we have two kinds of requests:
- membership requests: used by the gossip style service discovery system for maintaining cluster membership.
- partition requests: used to interact with
laminarmqtopic partitions.
We use an eBPF XDP filter to classify request packets at the socket layer into membership request packets and partition request packets. Next we use eBPF to route membership packets to a different socket which is exclusively used by the membership management subsystem in that node. The partition request packets are left to flow as is.
Next we have an "HTTP server", which parses the incoming partition request packets from the original
socket into valid partition::* requests. For every partition::* request, the HTTP server spawns
a future to handle it. This request handler future does the following:
- Create a new channel
(tx, rx)for the request. - Send the parsed partition request along with send end of the channel
(partition::*, tx)to the "Request Router" over the request router's receiving channel. - Await on the recv. end of the channel created by this future for the response.
res = rx.await - When we receive the response from this future's channel, we serialize it and respond back to the socket we had received the packets from.
Next we have a "Request Router / Partition manager" responsible for routing various requests to the
partition serving futures. The request router unit receives both membership::* requests from the
membership subsystem and partition::* requests received from the "HTTP server" request handler
futures (also called request poller futures from here on since they poll for the response from the
channel recv. rx end). The request router unit routes requests as follows:
membership::*requests are broadcast to all the partition serving futures(partition::*_request(partition_id_x, …), tx)tuples are routed to their destination partitions using thepartition_id.(partition::create(partition_id_x, …), tx)tuples are handled by the request router/ partition manager itself. For this, the request router / partition manager creates a new partition serving future, allocates the required storage units or it and sends and appropriate response ontx.
Finally, the individual partition server futures receive both membership::* and (partition::*, tx) requests as they come to our node and routed. They handle the requests as necessary and send a
response back to tx where applicable.
Thread per core execution model compatible design
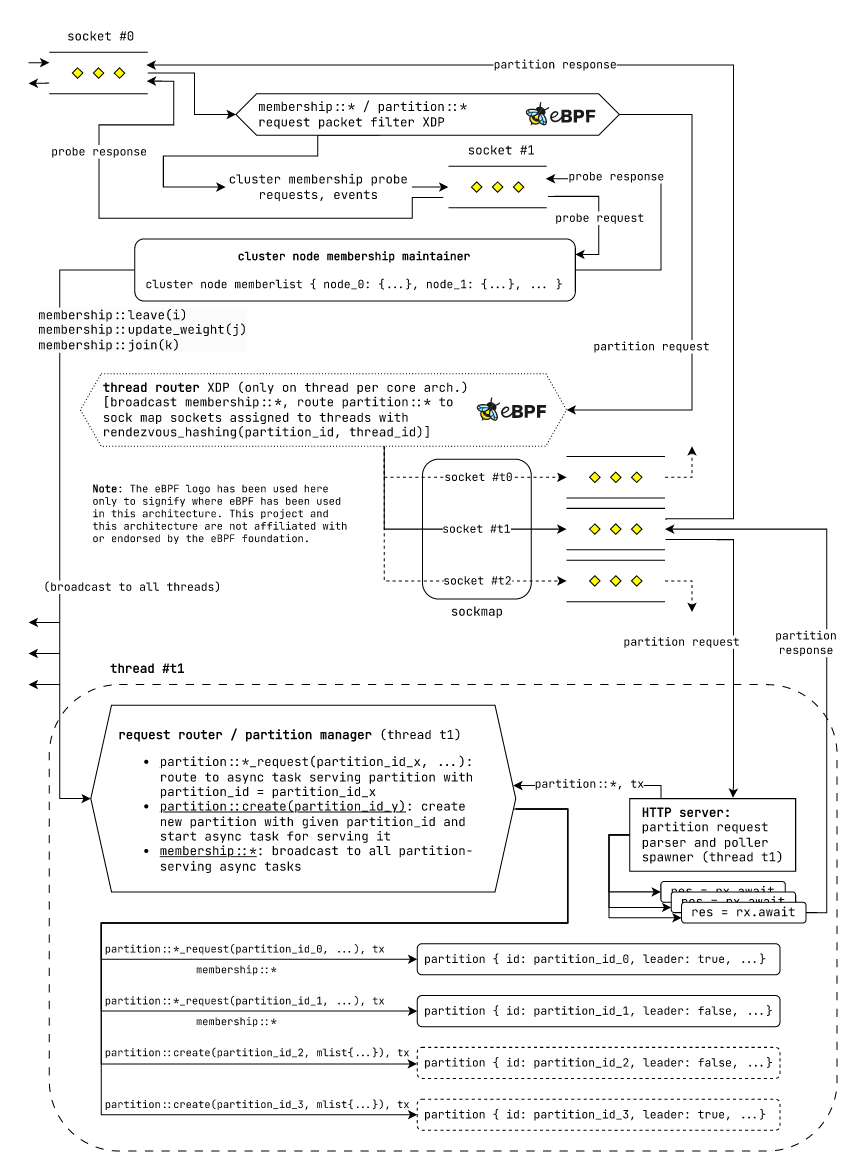
Fig: Request routing mechanism in laminarmq nodes using the thred per core
execution model.
In the thread per core execution model each thread is responsible for a subset of the partitions. Hence each thread has it's own "Request Router / Partition Manager", "HTTP Server" and a set of partition serving futures. We run multiple such threads on different processor cores.
Now, as discussed before we need to route individual requests to the correct destination thread to ensure request locality. We use a dedicated "Thread Router" eBPF XDP filter to route partition request packets to their destination threads.
The "Thread Router" eBPF XDP filter keeps a eBPF sockmap which contains the sockets where each of
the threads listen to for requests. For every incoming request, we route it to its destination
thread using this sockmap. Now we can again leverage rendezvous hashing here to determine the
thread to be used for a request. We use the partition_id and thread_id for rendezvous hashing.
Since all the threads run on different processor cores, they will have similar request handling
capacity and hence will have equal weights. Using this, requests belonging to a particular partition
will always be routed to the same thread on a particular node. This ensures a high level of request
locality.
The remaining components behave as discussed above. Notice how we are able to reuse the same components in a drastically different execution model, as promised before.
Partition control flow and replication
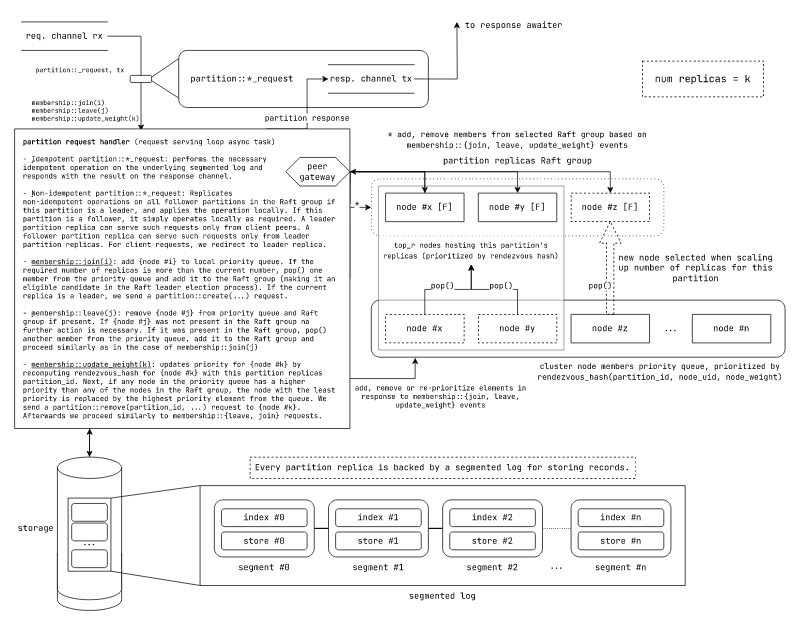
Fig: Partition serving future control flow and partition replication mechanism in
laminarmq
The partition controller future receives membership event requests membership::{join, leave, update_weight} or (paritition::*, tx) requests from the request router future.
The partition request handler handles the different requests as follows:
-
Idempotent
partition::*_request: performs the necessary idempotent operation on the underlying segmented log and responds with the result on the response channel. -
Non-idempotent
partition::*_request: Leader and follower replicas handle non-idempotent replicas differently:- Leader replicas: Replicates non-idempotent operations on all follower partitions in the Raft group if this partition is a leader, and then applies the operation locally. This might involve first sending an Raft append request, locally writing once majority of replicas respond back, then commit-ing it locally and finally relay the commit to all other replicas. Leader replicas respond to requests only from clients. Non-idempotent requests from follower replicas are ignored.
- Follower replicas: Follower replicas respond to non-idempotent requests only from leaders. Non-idempotent from clients are redirected to the leader. A follower replica handles non-idempotent requests by applying the changes locally in accordance with Raft.
Once the replicas are done handling the request, they send back an appropriate response to the response channel, if present. (A redirect response is also encoded properly and sent back to the response channel).
-
membership::join(i): add {node #i} to local priority queue. If the required number of replicas is more than the current number, pop() one member from the priority queue and add it to the Raft group (making it an eligible candidate in the Raft leader election process). If the current replica is a leader, we send apartition::create(...)request. If there is no leader among the replicas, we initial the leadership election process with each replica as a candidate. -
membership::leave(j): remove {node #j} from priority queue and Raft group if present. If{node #j}was not present in the Raft group no further action is necessary. If it was present in the Raft group,pop()another member from the priority queue, add it to the Raft group and proceed similarly as in the case ofmembership::join(j) -
membership::update_weight(k): updates priority for{node #k}by recomputing rendezvous_hash for {node #k} with this partition replicas partition_id. Next, if any node in the priority queue has a higher priority than any of the nodes in the Raft group, the node with the least priority is replaced by the highest priority element from the queue. We send apartition::remove(partition_id, ...)request to{node #k}. Afterwards we proceed similarly tomembership::{leave, join}requests.
When a node goes down the appropriate membership::leave(i) message (where i is the node that
went down) is sent to all the nodes in the cluster. The partition replica controllers in each node
handle the membership request accordingly. In effect:
- For every leader partition in that node:
- if there are no other follower replicas in other nodes in it's Raft group, that partition goes down.
- if there are other follower replicas in other nodes, there are leader elections among them and after a leader is elected, reads and writes for that partition proceed normally
- For every follower partition in that node:
- the remaining replicas in the same raft group continue to function in accordance with Raft's mechanisms.
For each of the partition replicas on the node that went down, new host nodes are selected using rendezvous hash priority.
In our system, we use different Raft groups for different data buckets (replica groups). CockroachDB and Tikv call this manner of using different Raft groups for different data buckets on the same node as MultiRaft.
Read more here:
Every partition controller is backed by a segmented_log for persisting records.
Persistence mechanism
segmented_log: Persistent data structure for storing records in a partition
The segmented-log data structure for storing was originally described in the Apache Kafka paper.

Fig: Data organisation for persisting the segmented_log data structure on a
*nix file system.
A segmented log is a collection of read segments and a single write segment. Each "segment" is backed by a storage file on disk called "store".
The log is:
- "immutable", since only "append", "read" and "truncate" operations are allowed. It is not possible to update or delete records from the middle of the log.
- "segmented", since it is composed of segments, where each segment services records from a particular range of offsets.
All writes go to the write segment. A new record is written at offset = write_segment.next_offset
in the write segment. When we max out the capacity of the write segment, we close the write segment
and reopen it as a read segment. The re-opened segment is added to the list of read segments. A new
write segment is then created with base_offset equal to the next_offset of the previous write
segment.
When reading from a particular offset, we linearly check which segment contains the given read segment. If a segment capable of servicing a read from the given offset is found, we read from that segment. If no such segment is found among the read segments, we default to the write segment. The following scenarios may occur when reading from the write segment in this case:
- The write segment has synced the messages including the message at the given offset. In this case the record is read successfully and returned.
- The write segment hasn't synced the data at the given offset. In this case the read fails with a segment I/O error.
- If the offset is out of bounds of even the write segment, we return an "out of bounds" error.
laminarmq specific enhancements to the segmented_log data structure
While the conventional segmented_log data structure is quite performant for a commit_log
implementation, it still requires the following properties to hold true for the record being
appended:
- We have the entire record in memory
- We know the record bytes' length and record bytes' checksum before the record is appended
It's not possible to know this information when the record bytes are read from an asynchronous stream of bytes. Without the enhancements, we would have to concatenate intermediate byte buffers to a vector. This would not only incur more allocations, but also slow down our system.
Hence, to accommodate this use case, we introduced an intermediate indexing layer to our design.
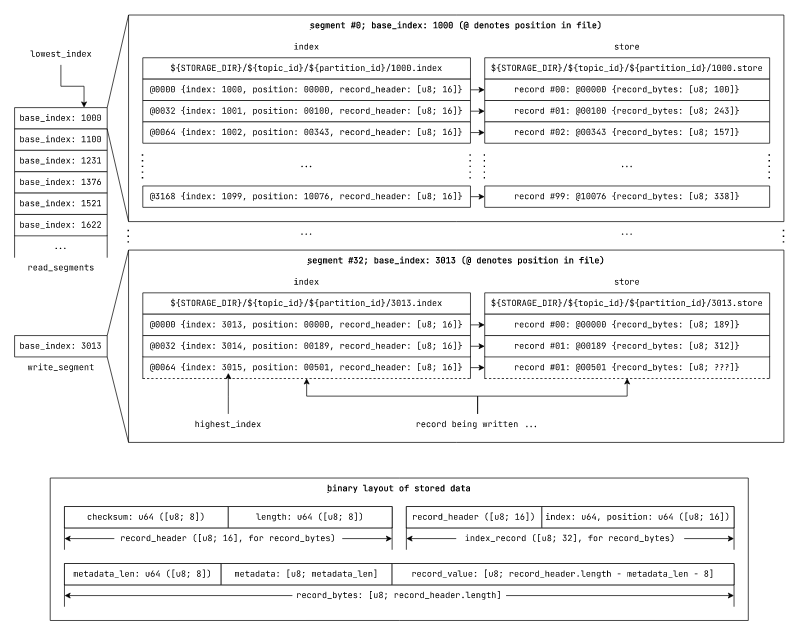
//! Index and position invariants across segmented_log
// segmented_log index invariants
segmented_log.lowest_index = segmented_log.read_segments[0].lowest_index
segmented_log.highest_index = segmented_log.write_segment.highest_index
// record position invariants in store
records[i+1].position = records[i].position + records[i].record_header.length
// segment index invariants in segmented_log
segments[i+1].base_index = segments[i].highest_index = segments[i].index[index.len-1].index + 1
Fig: Data organisation for persisting the segmented_log data structure on a
*nix file system.
In the new design, instead of referring to records with a raw offset, we refer to them with indices. The index in each segment translates the record indices to raw file position in the segment store file.
Now, the store append operation accepts an asynchronous stream of bytes instead of a contiguously
laid out slice of bytes. We use this operation to write the record bytes, and at the time of writing
the record bytes, we calculate the record bytes' length and checksum. Once we are done writing the
record bytes to the store, we write it's corresponding record_header (containing the checksum and
length), position and index as an index_record in the segment index.
This provides two quality of life enhancements:
- Allow asynchronous streaming writes, without having to concatenate intermediate byte buffers
- Records are accessed much more easily with easy to use indices
Now, to prevent a malicious user from overloading our storage capacity and memory with a maliciously
crafted request which infinitely loops over some data and sends it to our server, we have provided
an optional append_threshold parameter to all append operations. When provided, it prevents
streaming append writes to write more bytes than the provided append_threshold.
At the segment level, this requires us to keep a segment overflow capacity. All segment append
operations now use segment_capacity - segment.size + segment_overflow_capacity as the
append_threshold value. A good segment_overflow_capacity value could be segment_capacity / 2.
Execution Model
General async runtime (e.g. tokio, async-std etc.)
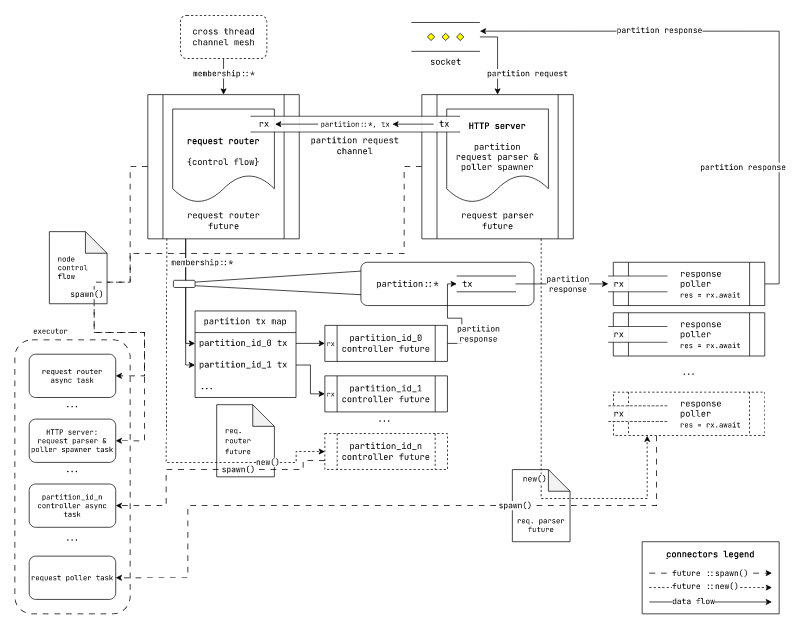
Fig: General async runtime based execution model for laminarmq
This execution model is based on the executor, reactor, waker abstractions used by all rust async runtimes. We don't have to specifically care about how and where a particular future is executed.
The data flow in this execution model is as follows:
- A HTTP server future parses HTTP requests from the request socket
- For every HTTP request it creates a new future to handle it
- The HTTP handler future sends the request and a response channel tx to the request router via a channel. It also awaits on the response rx end.
- The request router future maintains a map of partition_id to designated request channel tx for each partition controller future.
- For every partition request received it forwards the request on the appropriate partition request
channel tx. If a
partition::create(...)request is received it creates a new partition controller future. - The partition controller future send back the response to the provided response channel tx.
- The response poller future received it and responds back with a serialized response to the socket.
All futures are spawned using the async runtime's designated {…}::spawn(…) method. We don't have
to specify any details as to how and where the future's corresponding task will be executed.
Thread per core async runtime (e.g. glommio)
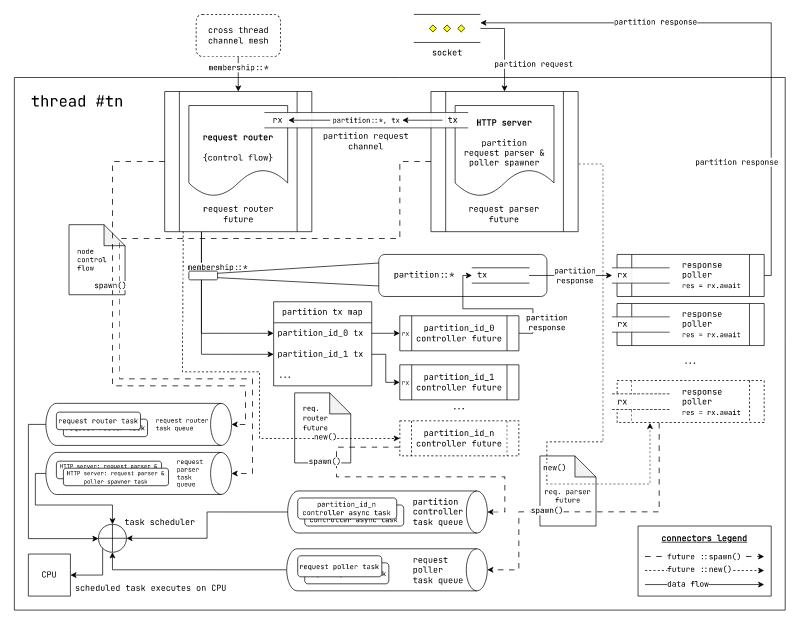
Fig: Thread per core async runtime based execution model for laminarmq
In the thread per core model since each processor core is limited to a single thread, tasks in a thread need to be scheduled efficiently. Hence each worker thread runs their own task scheduler.
We currently use glommio as our thread-per-core runtime.
Here, tasks can be scheduled on different task queues and different task queues can be provisioned with specific fractions of CPU time shares. Generally tasks with similar latency profiles are executed on the same task queue. For instance web server tasks will be executed on a different queue than the one that runs tasks for persisting data to the disk.
We re-use the same constructs that we use in the general async runtime execution model. The only difference being, we explicitly care about in which task queue a class of future's tasks are executed. In our case, we have the following 4 task queues:
- Request router task queue
- HTTP server request parser task queue
- Partition replica controller task queue
- Response poller task queue
Each of these task queue can be assigned specific fractions of CPU time shares. glommio also
provides utilities for automatically deducing these CPU time shares based on their runtime latency
profiles.
Apart from this glommio leverages the new linux 5.x io_uring
API which facilitates true asynchronous IO for both networking and disk interfaces. (Other async
runtimes such as tokio make blocking system calls for disk IO operations
in a thread-pool.)
io_uring also has the advantage of being able to queue together multiple system calls together and
then asynchronously wait for their completion by making a maximum of one context switch. It is also
possible to avoid context switches altogether. This is achieved with a pair of ring buffers called
the submission-queue and the completion-queue. Once the queues are set up, user can queue multiple
system calls on the submission queue. The linux kernel processes the system calls and places the
results in the completion queue. The user can then freely read the results from the
completion-queue. This entire process after setting up the queues doesn't require any additional
context switch.
Read more: https://man.archlinux.org/man/io_uring.7.en
glommio presents additional abstractions on top of io_uring in the form of an async runtime,
with support for networking, disk IO, channels, single threaded locks and more.
Read more: https://www.datadoghq.com/blog/engineering/introducing-glommio/
Testing
You may run tests with cargo as you would for any other crate. However, since laminarmq is
poised to support multiple runtimes, some of them might require some additional setup before running
the steps.
For instance, the glommio async runtime which requires an updated linux kernel (at least 5.8) with
io_uring support. glommio also requires at least 512 KiB of locked memory for io_uring to
work. (Note: 512 KiB is the minimum needed to spawn a single executor. Spawning multiple executors
may require you to raise the limit accordingly. I recommend 8192 KiB on a 8 GiB RAM machine.)
First, check the current memlock limit:
ulimit -l
# 512 ## sample output
If the memlock resource limit (rlimit) is lesser than 512 KiB, you can increase it as follows:
sudo vi /etc/security/limits.conf
* hard memlock 512
* soft memlock 512
To make the new limits effective, you need to log in to the machine again. Verify whether the limits
have been reflected with ulimit as described above.
(On old WSL versions, you might need to spawn a login shell every time for the limits to be reflected:
su ${USER} -lThe limits persist once inside the login shell. This is not necessary on the latest WSL2 version as of 22.12.2022)
Finally, clone the repository and run the tests:
git clone https://github.com/arindas/laminarmq.git
cd laminarmq/
cargo test
Benchmarking
Same pre-requisites as testing. Once the pre-requisites are satisfied you may
run benchmarks with cargo as usual:
git clone https://github.com/arindas/laminarmq.git
cd laminarmq/
cargo bench
The complete latest benchmark reports are available at https://arindas.github.io/laminarmq/bench/latest/report.
All benchmarks in the reports have been run on a machine (HP Pavilion x360 Convertible 14-ba0xx) with:
- 4 core CPU (Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz)
- 8GB RAM (SK Hynix HMA81GS6AFR8N-UH DDR4 2133 MT/s)
- 128GB SSD storage (SanDisk SD8SN8U-128G-1006)
Selected Benchmark Reports
This section presents some selected benchmark reports.
Note: We use the following names for different record sizes:
size_name size comments tiny12 bytesnone tweet140 bytesnone half_k560 bytes≈ 512 bytesk1120 bytes≈ 1024 bytes (1 KiB)linked_in_post2940 bytes≤ 3000 bytes (3 KB)blog11760 bytes (11.76 KB)4X linked_in_post
commit_log write benchmark with 1KB messages

Fig: Comparing Time taken v/s Input size in bytes (lower is better) across storage back-ends
View this benchmark report in more detail here
This benchmark measures the time taken to write messages of size 1KB across different commit_log storage back-ends.
We also profile our implementation across different storage backends. Here's a
profile using the
DmaStorage
backend.

Fig: Flamegraph for 10,000 writes of 1KB messages on DmaStorage backend
As you can see, a lot of time is spent simply hashing the request bytes.
segmented_log streaming read benchmark with 1KB messages
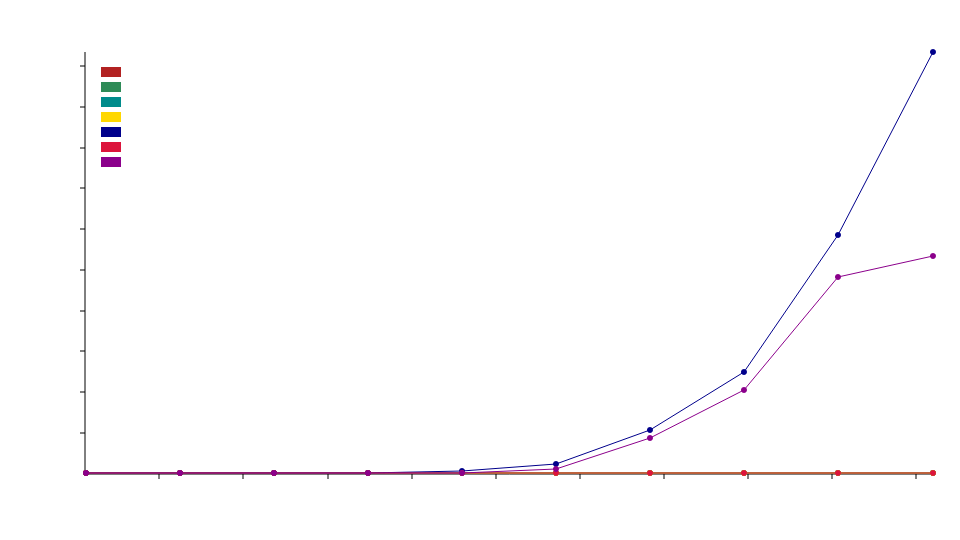
Fig: Comparing Time taken v/s Input size in bytes (lower is better) across storage back-ends
View this benchmark report in more detail here
This benchmark measures the time taken for streaming reads on messages of size
1KB across different segmented_log storage back-ends.
We also profile our implementation across different storage backends. Here's a
profile using the
DmaStorage
backend.

Fig: Flamegraph for 10,000 reads of 1KB messages on DmaStorage backend
In this case, more time is spent on system calls and I/O.
The remaining benchmark reports are available at https://arindas.github.io/laminarmq/bench/latest/report.
License
laminarmq is licensed under the MIT License. See
License for more details.
Dependencies
~19–34MB
~551K SLoC